これはBEAR.Sundayの全てのマニュアルページを一つにまとめたページです。
高度な実装ガイド
概要
このドキュメントでは、Application-Level Profile Semantics (ALPS)のより高度な実装トピックについて説明します。基本的な要素や属性の説明についてはALPSリファレンスを参照してください。
ディスクリプタとリンクリレーションタイプ
表現に状態遷移を含める場合、リンクリレーションタイプの有効な値は以下のいずれかを使用できます:
- 標準リンクリレーションタイプ
- IANAやMicroformats.orgなどのレジストリに登録された短い文字列
- 例:
rel="edit",rel="next",rel="collection" - IANAリンクリレーションを参照
- 拡張リンクリレーションタイプ ([RFC8288])
- リレーションタイプを説明する文書の完全修飾URI
- ALPSディスクリプタへのURIフラグメント識別子を含む
- 例:
rel="http://alps.io/profiles/item#purchased-by" - 例:
rel="http://alps.io/profiles/blog#comment"
- ALPSディスクリプタID
- ALPSドキュメントの状態遷移ディスクリプタのid属性値
- 表現にALPSプロファイルが含まれる場合のみ使用可能
- 例:
rel="purchased-by" - 例:
rel="create-comment"
リンクリレーションの競合解決
- 標準リレーションとの競合
- 状態遷移ディスクリプタが標準リンクリレーションと同じ意味を持つ場合、その意味を変更してはいけません
- 例:
editという名前のディスクリプタを作る場合、IANA登録済みのeditリレーションの意味と一致する必要があります
- ID競合の解決
- 複数のディスクリプタ間でidの競合が発生する場合:
- 一意のidを定義する必要があります
- 必要に応じてname属性を使用して元の名前を保持できます
- 例:
<descriptor id="user-edit" name="edit" type="safe"> <doc>ユーザー情報の編集</doc> </descriptor>
- 複数のディスクリプタ間でidの競合が発生する場合:
既存メディアタイプとの統合
ALPSは様々な既存メディアタイプと組み合わせて使用できます。以下に主要なメディアタイプとの統合方法を説明します。
HTML
HTMLでは主にclass属性を使用してALPSディスクリプタを表現します:
<div class="blog-post">
<h1 class="title">記事タイトル</h1>
<div class="content">本文...</div>
<form class="add-comment" method="post">
<input name="comment-text" class="comment-text">
<button type="submit">コメント追加</button>
</form>
</div>
対応するALPSプロファイル:
<alps version="1.0">
<descriptor id="blog-post" type="semantic">
<descriptor id="title" type="semantic"/>
<descriptor id="content" type="semantic"/>
<descriptor id="add-comment" type="unsafe">
<descriptor id="comment-text" type="semantic"/>
</descriptor>
</descriptor>
</alps>
HAL (Hypertext Application Language)
HALではリンクリレーションとして状態遷移を、プロパティとしてセマンティックディスクリプタを表現します:
{
"_links": {
"self": {"href": "/posts/1"},
"add-comment": {"href": "/posts/1/comments"}
},
"title": "記事タイトル",
"content": "本文...",
"_embedded": {
"comments": [
{
"_links": {
"self": {"href": "/comments/1"}
},
"text": "コメント内容..."
}
]
}
}
Collection+JSON
Collection+JSONではクエリとデータ要素としてディスクリプタを表現します:
{
"collection": {
"version": "1.0",
"href": "/posts/1",
"items": [
{
"data": [
{"name": "title", "value": "記事タイトル"},
{"name": "content", "value": "本文..."}
]
}
],
"template": {
"data": [
{"name": "comment-text", "value": "", "prompt": "コメントを入力"}
]
}
}
}
ALPSドキュメントの参照
ALPSプロファイルを適用する際の参照方法について説明します。
リンクによる参照
- HTML内での参照
<link rel="profile" href="http://example.com/alps/blog" /> - HTTP Linkヘッダーでの参照
Link: <http://example.com/alps/blog>; rel="profile" - メディアタイプパラメータでの参照
Content-Type: application/json; profile="http://example.com/alps/blog"
複数プロファイルの適用
1つの表現に複数のALPSプロファイルを適用できます:
Link: <http://example.com/alps/blog>; rel="profile",
<http://example.com/alps/comments>; rel="profile"
プロファイルの優先順位
複数のプロファイルが競合する場合の優先順位:
- メディアタイプのprofileパラメータで指定されたプロファイル
- HTTPの
Linkヘッダーで指定されたプロファイル - 表現内で指定されたプロファイル(先に指定されたものが優先)
エラー処理とバリデーション
実装時の一般的なエラーケースと対処方法について説明します。
よくあるエラー
- 無効なディスクリプタ参照
- 解決できないURLやフラグメント識別子
- 存在しないディスクリプタへの参照
- リンクリレーションの競合
- 標準リレーションとの意味的な競合
- 複数プロファイル間でのリレーション定義の競合
- メディアタイプの制約
- 特定のメディアタイプで表現できない要素の存在
- リンク表現のサポート不足
ベストプラクティス
状態
アプリケーション状態のセマンティックディスクリプタは大文字始まりのアッパーキャメルケースで表されます。
"descriptor": [
{"id": "BlogPosting", "type": "semantic", "def": "https://schema.org/BlogPosting", "descriptor": [
{"href": "#id"},
{"href": "#articleBody"},
{"href": "#dateCreated"},
{"href": "#blog"}
]}
]
安全な状態遷移
typeがsafeのセマンティックディスクリプタは、次の遷移先のディスクリプタにgoのプレフィックスを付加します。
(RFC8288)
[
{"id": "goHome", "type": "safe", "rt": "#Home"},
{"id": "goFirst", "type": "safe", "rt": "#TodoList"},
{"id": "goPrevious", "type": "safe", "rt": "#TodoList"}
]
safe以外のセマンティックディスクリプタには、doの接頭辞をつけます。
[
{"id": "doEditUser", "type": "idempotent", "rt": "#UserList"},
{"id": "doDeleteUser", "type": "idempotent", "rt": "#UserList"}
]
rt(遷移先)のIDはgoまたはdoのプレフィックスに次の遷移先のディスクリプタIDを付加します。
[
{"id": "goBlogPosting", "type": "safe", "rt": "#BlogPosting"},
{"id": "doEditBlogPosting", "type": "idempotent", "rt": "#Blog"}
]
要素
アプリケーション状態として定義されないセマンティックディスクリプタ、つまり要素(element)のセマンティックディスクリプタは小文字始まりのローワーキャメルケースで表記します。
[
{"id": "articleBody"},
{"id": "dateCreated"}
]
ALPSファイルの構造
ALPSファイルのセマンティクディスクリプターは以下の順の3つのブロックに分けます。
defやdocを用いた意味定義のセマンティックディスクリプタ群(オントロジー)- 包含関係のセマンティックディスクリプタ群(タクソノミー)
- 状態遷移のセマンティックディスクリプタ群(コレオグラフィー)
"descriptor" : [
{"id" : "name", "type" : "semantic", "def": "http://schema.org/identifier"},
{"id" : "age", "type" : "semantic", "def": "http://schema.org/title"},
{"id" : "Person", "type": "semantic", "descriptor":[
{"href": "#name"},
{"href": "#age"}
]}
{"id": "goPerson", "type": "safe", "rt": "#Person"},
]
ALPSの外にある階層構造
ALPSでは、階層的な意味をポジションで表現できます。
"descriptor": [
{"id": "name", "def": "https://schema.org/name"},
{"id": "Product", "descriptor":[
{"href": "#name"}
]}
{"id": "Person", "descriptor":[
{"href": "#name"}
]}
]
- 上記の例では、
nameは、Product/nameとPerson/nameで共有されています。 このような語をフラットな階層しかないフォーマットで表現する場合には、各フォーマットの慣習に従うのが基本です。 - htmlの場合は、Lower camel caseで表します。
<form>
<input name="productName" type="text">
<input name="personName" type="text">
</form>
スキーマ参照の追加
ALPSプロファイルを作成する際には、スキーマ参照を追加することをお勧めします。
{
"$schema": "https://alps-io.github.io/schemas/alps.json",
"alps" : {
}
}
<alps
version="1.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="https://alps-io.github.io/schemas/alps.xsd">
</alps>
実装例
セマンティック要素
基本要素の定義:
<descriptor id="title" title="タイトル" doc="記事のタイトル。最大100文字。"/>
<descriptor id="content" title="内容" doc="記事の本文。Markdown形式をサポート。"/>
<descriptor id="publishedAt" title="公開日時" doc="記事の公開日時。ISO 8601形式。"/>
{
"descriptor": [
{"id": "title", "title": "タイトル", "doc": {"value": "記事のタイトル。最大100文字。"}},
{"id": "content", "title": "内容", "doc": {"value": "記事の本文。Markdown形式をサポート。"}},
{"id": "publishedAt", "title": "公開日時", "doc": {"value": "記事の公開日時。ISO 8601形式。"}}
]
}
基本要素の再利用:
<descriptor id="blogPost">
<doc>ユーザーが作成した記事。公開後は全てのユーザーが閲覧可能。</doc>
<descriptor href="#title"/>
<descriptor href="#content"/>
<descriptor href="#publishedAt"/>
</descriptor>
<descriptor id="pagePost">
<doc>固定ページ。サイトの基本情報などの永続的なコンテンツ。</doc>
<descriptor href="#title"/>
<descriptor href="#content"/>
</descriptor>
{"descriptor": [
{"id": "blogPost", "doc": {"value": "ユーザーが作成した記事。公開後は全てのユーザーが閲覧可能。"}, "descriptor": [
{"href": "#title"},
{"href": "#content"},
{"href": "#publishedAt"}
]},
{"id": "pagePost", "doc": {"value": "固定ページ。サイトの基本情報などの永続的なコンテンツ。"}, "descriptor": [
{"href": "#title"},
{"href": "#content"}
]}
]}
操作の定義
<descriptor id="goBlog" type="safe" rt="#Blog" doc="ブログのトップページを表示。最新10件の記事を一覧表示。"/>
<descriptor id="doCreateBlogPost" type="unsafe" rt="#BlogPost">
<doc>新規記事を作成。下書き状態で保存される。</doc>
<descriptor href="#title"/>
<descriptor href="#content"/>
</descriptor>
<descriptor id="doPublishBlogPost" type="idempotent" rt="#BlogPost">
<doc>記事を公開。publishedAtに現在時刻が設定される。</doc>
<descriptor href="#id"/>
</descriptor>
{"descriptor": [
{"id": "goBlog", "type": "safe", "rt": "#Blog", "doc": {"value": "ブログのトップページを表示。最新10件の記事を一覧表示。"}},
{"id": "doCreateBlogPost", "type": "unsafe", "rt": "#BlogPost", "doc": {"value": "新規記事を作成。下書き状態で保存される。"}, "descriptor":[
{"href": "#title"},
{"href": "#content"}
]},
{"id": "doPublishBlogPost", "type": "idempotent", "rt": "#BlogPost", "doc": {"value": "記事を公開。publishedAtに現在時刻が設定される。"}, "descriptor": [
{"href": "#id"}
]}
]}
例
FAQ
Q. どのような人が利用できますか
A. サイト制作に関わる全ての人(エンジニア、デザイナー、PO)が利用できます。
Q. どのような人がALPSを記述できますか
A. XMLやJSONを理解でき、簡単なHTMLのコーディングができる人ならALPSを記述できます。
Q. どのように使いますか
A. 情報を最小限必要な要素に整理してサイト設計を行い、WebやAPIサービスの設計に使います。設計はJSONやXMLなどのフォーマットとして表し、遷移図やボキャブラリリストなどのドキュメントを生成できます。また各制作者はその情報設計に基づいて情報の正確な言葉や意味、構造を知ることができます。
Q. 情報設計とはなんですか
A. IA(Information Architecture)に基づいて、情報のオントロジー(言葉の意味)、タクソノミー(情報の分類)、コレオグラフィー(リンク)の観点で情報の情報(メタ情報)を定義します。
Q. 設計の清書に使うものでしょうか
A. いいえ。サイト設計のごく初期段階から、情報を整理しどのようなサイトを形作っていくなどモデリングツールとして利用できます。
Q. ALPSを記述するのには何が必要ですか
A. JSONやXMLを編集するエディターが必要です。
Q. XMLやJSONを直接編集するのは大変じゃないですか
A. WebStormなどのスキーマをサポートするエディターを使うと補完やバリデーションが効いて快適に編集できます。
Q. XMLとJSONではどちらが良いですか
A. 機能に違いはありません。また複数のALPSファイルを利用する場合でも統一する必要がありません。実際に見比べてみてください。XML / JSON
Q. リンクのないAPIにも使えますか
A. 遷移図は表せませんが、ボキャブラリや情報の性質を表すドキュメントが生成できます。
Q. ALPSと同様の技術は他にありますか
A. 直接の競合技術はありません。近い技術にMicroformatがあります。
Q. OpenAPIなどのIDLと何が違いますか
A. ALPSはHTTPよりさらに上位のRESTの抽象を扱います。そのためOpenAPI実装のためのモデリングや設計言語として用いることもできます。
Q. 私に必要ですか
A. ユーザー体験の質の向上のために情報中心でサイトを設計したい、制作メンバー間の認識を統一するための信頼できる唯一の情報源(SSOT)が欲しい、設計を俯瞰し再利用したい、情報設計を規格化されたドキュメントとして残したい、などの動機があれば役に立つでしょう。
情報アーキテクチャとALPS
API設計やシステム構築において、情報アーキテクチャ(IA)の考え方をドメインモデリングに適用することで、ビジネス要件を体系的に整理できます。もともとUXやコンテンツ設計で培われてきたIAの「意味」「構造」「インタラクション」という要素は、ビジネスドメインの知識を構造化する際にも重要な役割を果たし、ALPSはこの考え方を標準化された方法で表せます。
情報アーキテクチャの適用
情報アーキテクチャの専門家であるDan Klynは情報アーキテクチャ(IA)を「意味(Ontology)」「構造(Taxonomy)」「インタラクションのルール(Choreography)」の相互作用として定義しました。1 これらの概念はコンテンツ設計だけでなく、システム設計の基盤としても機能します。OpenAPIがAPIの技術的な詳細(エンドポイント、HTTPメソッド、リクエスト/レスポンス構造など)に焦点を当てるのに対し、ALPSはこれらのIA概念を用いてビジネスドメインの構造化を行います。
設計プロセスにおける位置づけ
ALPSは設計の初期段階からビジネス要件とシステム設計を橋渡しします。従来のエンドポイント中心の設計が決定済みの仕様を文書化する段階で使用されるのに対し、ALPSは要件定義のフェーズから活用できます。これにより、ビジネス要件の解釈の違いを早期に発見し、修正できます。また、技術チームとビジネスチーム間で共通言語が確立され、設計変更の影響範囲を把握しやすい仕組みが整えられます。
ALPSはAPIエンドポイントの設計を超え、ビジネス領域の知識を体系化し共有するための手段を提供します。信頼できる唯一の情報源(Single Source of Truth, SSOT)として、システムの構造と動作を一貫してモデル化します。ビジネス用語を中心とした記述により、複雑なビジネスルールを明確に表現し、ワークフローを可視化し情報の相互作用を俯瞰し直感的に理解できます。
技術変化への対応
ALPSはさまざまなAPIスタイルに適用できる柔軟性を持っています。技術の進化によってアーキテクチャスタイルが変化しても、ビジネスドメインの設計を維持できます。例えば、RESTful APIからGraphQLへの移行や、マイクロサービスアーキテクチャの導入、新しい通信プロトコルの採用など、技術的な変更が生じても、ALPSで定義したドメインモデルは継続して使用できます。これは、ALPSが実装の詳細ではなく、抽象化されたビジネスロジックに焦点を当てているためです。
知識基盤の構築
Taxonomyの実装では、ビジネスエンティティ間の関係性を定義し、階層構造による拡張性を確保します。これにより、組織全体で共通の語彙が確立され、コミュニケーションが効率化されます。Choreographyでは、ビジネスプロセスのフローとサービス間の連携ルールを定義し、システム全体の一貫性と信頼性を高めます。
IAの考え方をドメインモデリングに適用することで、技術的な実装とビジネス要件を自然に結びつけます。ALPSはこの橋渡しを実現するフレームワークとして機能し、組織の知識を体系的に構造化し、進化させる基盤となります。
この取り組みにより、技術の変化に影響されない持続可能な組織の知識基盤を構築する事ができます。
IANAリンクリレーション
このドキュメントはALPSプロファイルのrel属性で使用が推奨される、IANAリンクリレーションの一覧です。
状態遷移
| リレーション | 説明 |
| edit | 対象の状態を編集できる遷移を表す |
| edit-form | 編集用のフォームを取得する遷移を表す |
| create-form | 作成用のフォームを取得する遷移を表す |
| collection | コレクション全体を表す状態への遷移 |
| item | コレクションの個別要素を表す状態への遷移 |
順序のある遷移
| リレーション | 説明 |
| first | シリーズの最初の状態への遷移 |
| last | シリーズの最後の状態への遷移 |
| next | シリーズの次の状態への遷移 |
| prev | シリーズの前の状態への遷移 |
意味的記述
| リレーション | 説明 |
| describedby | セマンティックディスクリプタの詳細な説明への参照 |
| describes | セマンティックディスクリプタが説明する対象への参照(describedbyの逆関係) |
| type | セマンティックディスクリプタの抽象的な型を示す |
文書構造
| リレーション | 説明 |
| section | 文書内のセクションを示す |
| subsection | 文書内のサブセクションを示す |
| chapter | 文書内の章を示す |
| contents | 文書の目次を示す |
メタデータ
| リレーション | 説明 |
| author | 作成者情報への参照 |
| license | ライセンス情報への参照 |
| copyright | 著作権情報への参照 |
バージョン管理
| リレーション | 説明 |
| latest-version | 最新バージョンの状態への遷移 |
| predecessor-version | 前バージョンの状態への遷移 |
| successor-version | 次バージョンの状態への遷移 |
| version-history | バージョン履歴を示す状態への遷移 |
関連情報
| リレーション | 説明 |
| help | ヘルプ情報への参照 |
| status | 状態に関する情報への参照 |
| alternate | 代替表現への参照 |
注意:
- このリストはALPSプロファイルでよく使用される可能性のあるリレーションの抜粋です
- 完全な一覧はIANAのRegistryを参照してください
- カテゴリ分けは便宜上のものです
- 実際の使用時は、アプリケーションの要件に応じて適切なリレーションを選択してください
イントロダクション

ALPS: アプリケーションレベルの意味と構造を明確にするフォーマット
Application-Level Profile Semantics (ALPS)は、アプリケーションレベルのセマンティクスを表現し、JSONやHTMLなどの汎用メディアにアプリケーション固有の情報を付加するフォーマットです。ALPSはデータの意味や構造、そして操作を明確化し、開発プロセスの効率化、システム間の互換性向上、APIの再利用性と発見性の促進を実現します。
電子商取引プラットフォームを例に考えてみましょう。クレジットカード、電子マネー、銀行振込など、複数の支払いサービスとの統合時、ALPSは支払いプロセスの各ステップにおけるデータと操作の意味を標準化します。これにより、新しい決済方法の追加や既存システムとの統合が容易になり、開発者は一貫した方法でAPIを実装できます。フロントエンドとバックエンドの開発者も共通の言語で効率的にコミュニケーションを取り、迅速に機能を追加・改善できます。
ASD: アプリケーション状態遷移の可視化
ASD(Application State Diagram)は、ALPSドキュメントからアプリケーションの状態遷移と行動を可視化するツールです。これにより、アプリケーションの全体構造を俯瞰し、状態間の遷移や可能なアクションを直感的に捉えることが可能になります。例えば、オンラインショッピングアプリにおいて、ユーザーが商品を検索してから購入に至るプロセスが明確に可視化され、開発者はユーザーが各段階で直面する選択と可能な操作を理解しやすくなります。これはユーザー体験の向上に繋がる設計上の意思決定を助けます。
ASDの利用により、プロダクトオーナー、バックエンドおよびフロントエンドの開発者、UI/UXデザイナーなど、プロジェクトに関わる全てのチームメンバーが同じ視点でアプリケーションを理解し、効果的に協力できるようになります。 これにより、専門分野の異なるメンバー間でスムーズなコミュニケーションが可能になり、複雑なプロジェクトでも新しいメンバーがスムーズに参加できるようになります。また、アプリケーションの流れやロジックを素早く把握して必要な調整ができるため、設計の早い段階で問題を見つけて解決でき、開発の効率と品質を高めます。
ASDを活用することで、プロジェクトの透明性が高まり、各チームメンバーが持つビジョンの齟齬を最小化できます。
RESTアプリケーション設計のための情報アーキテクチャ
情報アーキテクチャの観点からRESTアプリケーションを設計する際、ALPSとASDはお互いを補完する役割を果たします。ALPSはアプリケーションが扱うデータの意味や構造を標準化し、チーム全体で共通の語彙を使って情報を定義できるようにします。一方、ASDはアプリケーションの状態の変化を図で表現し、ユーザーの操作とアプリケーションの反応を視覚的に理解しやすくします。ALPSの仕様とASDによる可視化により、RESTアプリケーションの開発における情報設計が強化され、チーム間のコミュニケーションがスムーズになり、プロジェクト全体の一貫性と品質を高めます。
開発効率の向上、優れたユーザーエクスペリエンスの提供、そしてプロジェクトの持続可能性の確保には、多様な開発者間で共有される理解の基盤が不可欠です。ALPSとASDは、この基盤を構築しプロジェクトの長期的な成功を支えます。
イントロダクション

ALPS:アプリの情報を整理する方法
ALPS(アプリケーションレベルのプロファイルセマンティクス)は、アプリの情報や仕組みをきちんと説明するための方法です。インターネット上でよく使われる形式(例えばJSONやHTML)に、アプリ固有の情報を加えて、そのアプリがどのように動くのか、どんな情報を扱っているのかをはっきりさせます。これにより、アプリを作る過程がスムーズになり、異なるアプリやシステム同士が上手く連携できるようになります。
例えば、ネットショッピングのサイトを考えてみましょう。お客さんが商品を選んで買うまでの一連の手順(支払いを含む)について、ALPSを使うと、それぞれのステップで何が起こっているのかを明確に示すことができます。これにより、アプリを作る人たちは、お客さんがスムーズに買い物ができるように、必要な改善をしやすくなります。
ASD:アプリの動きを図で見る
ASD(アプリケーション状態遷移図)は、ALPSで説明されたアプリの情報をもとに、アプリの動きやユーザーができる操作を図で示します。これにより、アプリがどのように動いているのかを一目で理解できるようになります。ネットショッピングのサイトでいうと、商品を探してカートに入れる、支払う、という一連の流れが図で示されます。
ASDを使うと、アプリを作っているチームの中で、プログラマーやデザイナーなど、異なる役割の人たちが、アプリがどのように動くべきかについて、共通の理解を持つことができます。これは、アプリをより良くするための議論や、新しいアイデアを出し合う際にとても役立ちます。
RESTアプリケーションの設計
ALPSとASDは、特にWeb上で動くアプリ(RESTアプリケーションと呼ばれます)の設計に役立ちます。これらのツールを使うことで、アプリがどのような情報を扱い、どのように動くのかをはっきりと示すことができます。結果として、アプリの作成や改善がしやすくなり、使っている人にとっても、より使いやすいアプリになります。
多様なスキルを持つチームメンバーが同じ目標に向かって効率的に作業を進めるためには、お互いの作業内容を正確に理解し合うことが大切です。ALPSとASDは、そのための理解を深めるのに非常に役立つツールです。
リソース
ALPS Prompt Creation
Paste your existing ALPS profile below and proceed directly to the format conversion step.
Convert ALPS to Implementation Format
Generated ALPS Prompt
💡 Pro Tip: After receiving your ALPS profile from the AI, consider asking: "Please review this ALPS profile to verify that there are no isolated states (unreachable or exit-less states) and that all state transitions are properly connected. Also check if all semantic descriptors are consistently tagged and grouped."
💡 Next Step: After confirming that ALPS is rendered correctly at https://editor.app-state-diagram.com/, Paste your ALPS profile into textarea and proceed directly to the format conversion step.
Select Target Implementation Format
Generated Conversion Prompt
Copy this prompt to ChatGPT, Claude, or any other AI assistant:
💡 Remember: For best results, first have the AI verify the ALPS profile for correctness, then provide this conversion prompt.
Tip: For quick results, you can also use ALPS Assistant GPTs with your prompts.
インストールと利用ガイド
ASD(app-state-diagram)は、アプリケーションの状態遷移図やボキャブラリリストを含んだALPSの包括的なドキュメントを作成するためのツールです。以下の方法で利用できます。
利用方法の選択
1. オンライン版
ローカルインストール不要で、すぐに利用できます:
特徴:
- インストール不要
- ブラウザですぐに利用可能
- JSON/XML/HTMLファイルをドラッグ&ドロップで読み込み可能
- スニペットや高度なコード補完機能
- ローカル環境へのインストールが不要な場合の推奨オプション
- 注意)現在複数ファイルを一度に編集することができません
2. Homebrew版
homebrewがインストールされている環境では最も簡単に利用できます。
インストール:
brew install alps-asd/asd/asd
3. Docker版
Dockerで実行するためのスクリプトをダウンロードして実行します。シェルスクリプトのダウンロードと実行を伴うために以下のセキュリティ確認手順に従ってください。
セキュリティ確認手順
- スクリプトの内容確認(推奨):
curl -sL https://alps-asd.github.io/app-state-diagram/asd.sh | less
- チェックサム検証:
curl -sL https://alps-asd.github.io/app-state-diagram/asd.sh | sha256sum
期待値:
0f05034400b2e7fbfee6cddfa9dceb922e51d93fc6dcda62e42803fb8ef05f66
- インストール実行:
sudo curl -sL https://alps-asd.github.io/app-state-diagram/asd.sh -o /usr/local/bin/asd
sudo chmod +x /usr/local/bin/asd
前提条件
- Dockerがインストールされていること
- curlコマンドが利用可能であること
4. Macランチャーアプリケーション(GUI版)
コマンドライン操作が不要なMac用GUIアプリケーションです。
インストール手順:
- ASD launcherをダウンロード
- セキュリティ確認:
- ダウンロードしたファイルの内容を確認してください
- チェックサム(SHA-256)の検証:
shasum -a 256 [ダウンロードしたzipファイル] - 公式リポジトリの期待値と比較してください: 659ecc3225b95a04f0e2ac4ebed544267ba78a0221db7ed84b6dfd7b08ce423b
- ダウンロードしたスクリプトをスクリプトエディタで開く
- セキュリティ警告が表示された場合は、スクリプトを右クリック(またはControlキーを押しながらクリック)して「開く」を選択
- システム設定 > プライバシーとセキュリティで、表示された場合は「開く」をクリック
- アプリケーションとして書き出す:
- 保存先:「アプリケーション」
- フォーマット:「アプリケーション」として保存
5. GitHub Actions版
CIでASD作成を行います。詳細はマーケットプレイスをご覧ください。
6. VSCode Plugin
VSCodeでライブプレビューを可能にするプラグインが利用可能です。 (experimental)
Visual Studio Marketplace - Application State Diagram
使用方法
デモ実行
# デモファイルのダウンロードと実行
curl -L https://alps-asd.github.io/app-state-diagram/blog/profile.json > alps.json
asd -w ./alps.json
コマンドラインオプション
asd [options] [alpsFile]
オプション:
-w, --watch ウォッチモード
-m, --mode 描画モード
--port 利用ポート(デフォルト3000)
モード設定
- 非公開リポジトリでの利用時はMarkdownモードを使用可能
- ただし、Markdownモードではダイアグラムのリンクは機能しません
- HTMLを公開できない場合の代替オプションとして利用
インストール確認
asd
usage: asd [options] alps_file
@see https://github.com/alps-asd/app-state-diagram#usage
選択の目安
- すぐに試したい、一時的な利用 → オンライン版
- Mac環境でのローカル利用 → Homebrew版
- クロスプラットフォームでの利用 → Docker版
- Macローカル環境でGUI → ランチャーアプリケーション
- CI/CD環境での利用 → GitHub Actions版
ALPSリファレンス
概要
Application-Level Profile Semantics (ALPS) は、アプリケーションのセマンティクス(意味論)を記述するためのドキュメントフォーマットです。このドキュメントではALPSの要素と属性について説明します。
文書構造
ALPSドキュメントは以下のような階層構造を持ちます:
- ルート要素 (
alps)- バージョン情報を含むドキュメントのルート要素
- すべての定義はこの要素の中に含まれます
- ディスクリプタ要素 (
descriptor)- アプリケーションの機能や情報の意味を定義する中心的な要素
- 以下の4つの型があります:
- semantic: 語句・情報を表す(デフォルト)
- safe: 読み取り操作(リソースの状態を変更しない)
- idempotent: 同じ操作を複数回実行しても結果が変わらない操作(PUTによる完全な置き換えやDELETEによる消去など)
- unsafe: 同じ操作を複数回実行すると異なる結果になる操作(POSTによる新規作成、数値の加算操作など)
- 他のdescriptor要素を子要素として含むことができます
- link要素を子要素として含むことができます
- 補足要素
doc: 詳細な説明や補足情報link: 関連ドキュメントへの参照title: プロファイルの説明
記述形式
ALPSドキュメントは以下の2つの形式で記述できます:
XML形式
<?xml version="1.0" encoding="UTF-8"?>
<alps version="1.0">
<title>ブログAPIプロファイル</title>
<doc>ブログシステムのAPIプロファイル</doc>
<descriptor id="title" title="タイトル" doc="記事のタイトル。最大100文字。"/>
<descriptor id="blogPost">
<doc>ブログ記事</doc>
<descriptor href="#title"/>
<link rel="related" href="http://example.org/related-docs/blog.html" />
</descriptor>
</alps>
JSON形式
{
"alps": {
"version": "1.0",
"title": "ブログAPIプロファイル",
"doc": {"value": "ブログシステムのAPIプロファイル"},
"descriptor": [
{"id": "title", "title": "タイトル", "doc": {"value": "記事のタイトル。最大100文字。"}},
{"id": "blogPost", "doc": {"value": "ブログ記事"},
"descriptor": [
{"href": "#title"}
],
"link": [
{"rel": "related", "href": "http://example.org/related-docs/blog.html"}
]
}
]
}
}
要素と属性の詳細
alps
ALPSドキュメントのルート要素です。
属性:
- version: 文書のバージョン(必須)
descriptor
アプリケーションの機能や情報の意味(セマンティクス)を定義します。 idまたはhrefのいずれかが必要でその他の属性はオプションです。
descriptorは以下の子要素を持つことができます:
- descriptor: 他のdescriptor要素を入れ子にして、階層構造を表現できます
- doc: 詳細な説明
- link: 関連リソースへのリンク
- ext: 拡張情報
descriptor属性一覧
| 属性名 | 必須 | 型 | 説明 | 例 |
|---|---|---|---|---|
| id | ※1 | string | 要素の一意識別子 | "blogPost" |
| href | ※1 | string | 他要素への参照 | "#title" |
| type | 任意 | enum | 要素の型 | "safe" |
| rt | 任意 | string | 遷移先リソース | "#BlogPost" |
| rel | 任意 | string | リレーション | "item" |
| title | 任意 | string | 表示名 | "ブログ投稿" |
| tag | 任意 | string | 分類タグ | "blog post" |
| name | 任意 | string | 表示用名前 | "blog" |
| def | 任意 | string | 定義元URI | "http://schema.org/BlogPosting" |
| descriptor | 任意 | element | 子descriptorの入れ子 | <descriptor id="child">...</descriptor> |
| link | 任意 | element | 関連リソースへのリンク | <link rel="help" href="..."/> |
※1: idまたはhrefのいずれかが必須
各属性の詳細:
- id: 一意の識別子(hrefと排他)
- descriptorを一意に識別する文字列
- 同一文書内で重複不可
- URL安全な文字のみ使用可能(RFC1738に準拠)
- href: 参照先(idと排他)
- 他のdescriptorを参照するための識別子
- ”#”で始まるフラグメント識別子(例:#user)
- 外部ファイルの場合はパスを含む(例:profile.xml#user)
- 解決可能なURLとフラグメント識別子(#)必須
- type: ディスクリプターの型
- semantic: 語句・情報を表す(デフォルト)
- safe: 読み取り操作(リソースの状態を変更しない)
- idempotent: 同じ操作を複数回実行しても結果が変わらない操作(PUTによる完全な置き換えやDELETEによる消去など)
- unsafe: 同じ操作を複数回実行すると異なる結果になる操作(POSTによる新規作成、数値の加算操作など)
- rt: 遷移先(Return Type)
- 状態遷移後の移動先リソース
- ”#”で始まるフラグメント識別子で指定
- type属性が
safe/idempotent/unsafeの場合に使用
- rel: リレーション
- descriptorの関係性を示す
- IANAで定義されたLink Relationsを使用(item, collection, self, next, prev など)
- カスタムの場合はURIで指定
- title: 表示名
- 人間が読むための表示名
- UIやドキュメントでの表示用
- tag: 分類タグ
- descriptorのグルーピングに使用
- 複数指定する場合はスペース区切り
- カテゴリ分類やフィルタリング用
- name: 表示用名前
- 実際の表現で使用される名前
- idが一意である必要がある場合に、共通の名前を指定するために使用
- 同じnameを持つ複数のdescriptorが存在可能
- def: 定義元URI
- descriptorの定義元となる外部リソースを示すURI
- Schema.orgなどの標準的な定義への参照に使用
doc
要素の詳細な説明を提供します。
doc属性一覧
| 属性名 | 必須 | 型 | 説明 | 例 |
|---|---|---|---|---|
| href | 任意 | string | 外部ドキュメントURL | "http://example.com/doc" |
| format | 任意 | string | ドキュメントフォーマット | "markdown" |
| contentType | 任意 | string | コンテンツタイプ | "text/html" |
| tag | 任意 | string | 分類タグ | "api spec" |
| value | 任意 | string | 説明文 | "詳細な説明" |
format属性のサポートレベル:
- text: サポート必須(MUST)
- html: サポート推奨(SHOULD)
- asciidoc: サポート任意(MAY)
- markdown: サポート任意(MAY)、[RFC7763]に準拠
contentTypeとformatの優先順位:
- contentTypeが存在する場合はそれを使用
- contentTypeとformatが両方ある場合はformatを無視
- どちらもない場合はtext/plainと見なす
link
関連ドキュメントへの参照を定義します。linkはalpsまたはdescriptor要素の子要素として使用できます。
link属性一覧
| 属性名 | 必須 | 型 | 説明 | 例 |
|---|---|---|---|---|
| href | 必須 | string | リンク先URL | "http://example.com/docs" |
| rel | 必須 | string | リレーション | "help" |
| title | 任意 | string | 表示名 | "ヘルプドキュメント" |
| tag | 任意 | string | 分類タグ | "documentation" |
リレーション値:
- self: 自身へのリンク
- profile: プロファイルドキュメント
- help: ヘルプドキュメント
- related: 関連ドキュメント
- その他のIANAリンクリレーション
ext
拡張情報を提供します。標準仕様にない追加情報を含める場合に使用します。
ext属性一覧
| 属性名 | 必須 | 型 | 説明 | 例 |
|---|---|---|---|---|
| id | 必須 | string | 拡張の一意識別子 | "range" |
| href | 推奨 | string | 拡張の説明URL | "http://alps.io/ext/range" |
| value | 任意 | string | 拡張値 | "0,100" |
| tag | 任意 | string | 分類タグ | "validation" |
バリデーション
- descriptorにはidまたはhrefのいずれかが必要です
- href参照先は解決可能なURLでなければならず、フラグメント識別子が必須です
- rt遷移先は文書内に実在する必要があります
- type属性は定義された4値(semantic、safe、idempotent、unsafe)のいずれかである必要があります
- 操作系descriptorには以下のプレフィックスの使用を推奨します:
- safe:
go(例:goBlog) - unsafe:
do(例:doCreateBlog) - idempotent:
do(例:doUpdateBlog)
- safe:
階層構造の例
以下は、入れ子になったdescriptor要素を使用した簡潔な階層構造の例です:
XML形式
<alps version="1.0">
<descriptor id="user" type="semantic">
<doc>ユーザー情報</doc>
<descriptor id="name" type="semantic" />
<descriptor id="email" type="semantic" />
<link rel="help" href="http://example.org/help/user.html" />
</descriptor>
</alps>
JSON形式
{
"alps": {
"version": "1.0",
"descriptor": [
{
"id": "user",
"type": "semantic",
"doc": {"value": "ユーザー情報"},
"descriptor": [
{"id": "name", "type": "semantic"},
{"id": "email", "type": "semantic"}
],
"link": [
{"rel": "help", "href": "http://example.org/help/user.html"}
]
}
]
}
}
Schema.org 用語集
プロパティ
| Property | Description | Meta information |
|---|---|---|
| about | コンテンツの主題。 | |
| abridged | 書籍が抄訳版であるかどうかを示します。 | |
| abstract | 抄録は、CreativeWork を要約する短い説明です。 | |
| accelerationTime | 車両を指定された初期速度から指定された目標速度まで加速するのに要する時間。 一般的な単位コード: 秒の場合はSEC
|
|
| acceptedAnswer | 質問/回答サイトで最良のものとして受け入れられた回答(たち)。サイトによって選定方法は異なり、例えばコミュニティの意見や質問者の見解に基づいて決定されることがあります。 | |
| acceptedOffer | 注文に含まれる提案(例:製品、数量、価格の組み合わせ) | |
| acceptedPaymentMethod | このオファーに対して出品者が受け付ける支払い方法(s)。 | |
| acceptsReservations | FoodEstablishmentが予約を受け付けるかどうかを示します。値はBoolean、予約ができるURL、または(後方互換性のため)文字列「Yes」または「No」となります。 |
|
| accessCode | パスワード、PIN、または配達に必要なアクセスコード(例:ロッカーからのもの)。 | |
| accessMode | 人間の感覚知覚システムまたは、人が情報を処理または知覚する認知能力。期待される値には、auditory、tactile、textual、visual、colorDependent、chartOnVisual、chemOnVisual、diagramOnVisual、mathOnVisual、musicOnVisual、textOnVisual が含まれます。 | |
| accessModeSufficient | リソースのすべての知的コンテンツを理解するのに十分な、単一または組み合わせのaccessModesのリスト。想定される値には、auditory、tactile、textual、visualが含まれます。 | |
| accessibilityAPI | リソースが参照されているアクセシビリティAPI(WebSchemas wikiは可能な値をリストしています)と互換性があることを示します。 | |
| accessibilityControl | 記述されたリソースを完全に制御するのに十分な入力方法を特定します (WebSchemas wiki に可能な値がリストされています)。 | |
| accessibilityFeature | リソースのコンテンツ機能(アクセシブルなメディア、代替案、アクセシビリティのためのサポートされている拡張機能など)(WebSchemas wiki は可能な値をリストしています)。 | |
| accessibilityHazard | 記述されたリソースの特徴で、一部のユーザーにとって生理的に危険なものです。WCAG 2.0 ガイドライン 2.3 に関連します (WebSchemas wiki は可能な値をリストしています)。 | |
| accessibilitySummary | 特定のアクセシビリティ機能または欠如に関する、人間が読める要約で、他のアクセシビリティメタデータと一貫性がありながら、「短い説明は存在するが、非視覚ユーザーには長い説明が必要になる」や「短い説明は存在し、長い説明は必要ない」といったニュアンスを表現するものです。 | |
| accommodationCategory | Accommodationのカテゴリーで、不動産慣例に従います(例:RESO。推奨値については、PropertySubTypeおよびPropertyTypeフィールドを参照)。 | |
| accommodationFloorPlan | あるAccommodationのフロアプラン。 | |
| accountId | 支払いを適用するアカウントの識別子です。 | |
| accountMinimumInflow | 毎月支払う必要のある最低金額。 | |
| accountOverdraftLimit | 口座残高がゼロに達した場合、金融機関からの信用供与が「口座赤字」です。口座赤字により、個人は口座に資金がなくても引き出しを続けることができます。基本的に銀行は、人々に一定額の資金を借りることを許可しています。 | |
| accountablePerson | CreativeWorkに対して法的責任を負う人物を指定します。 | |
| acquireLicensePage | 現在のアイテムのライセンスが購入またはその他の方法でどのように入手できるかを説明するページを示します。 | |
| acquiredFrom | 製品が購入された組織または個人。 | |
| acrissCode | ACRISS車両分類コードは、多くのレンタカー会社で使用されている車両分類コードです。ACRISSは、Association of Car Rental Industry Systems and Standardsの略です。 | |
| actionAccessibilityRequirement | アクションを実行するために満たす必要のある要件のセットです。複数の値が指定されている場合、1つの要件セットを満たすことでアクションを実行できます。 | |
| actionApplication | リクエストを完了できるアプリケーション。 | |
| actionOption | オブジェクトのサブプロパティ。このアクションの対象となるオプション。 | |
| actionPlatform | 指定されたURLに対してアクションを実行できる高レベルのプラットフォーム。特定のアプリケーションまたはオペレーティングシステムインスタンスを指定するには、actionApplicationを使用してください。 | |
| actionStatus | アクションの現在の状態を示します。 | |
| actionableFeedbackPolicy | NewsMediaOrganizationまたはその他のニュース関連のOrganizationにとって、世論との関わり合い活動(ニュースメディアの場合は報道機関の)、についての方針表明。これには、報道の決定、報道、および出版後の活動において、世論をデジタルまたはその他の方法で巻き込むことが含まれます。 | |
| activeIngredient | 有効成分、通常は化学化合物および/または生物学的物質。 | |
| activityDuration | 活動に従事する時間の長さ。 | |
| activityFrequency | その活動にどのくらいの頻度で取り組むべきか。 | |
| actor | 俳優、例えばテレビ、ラジオ、映画、ビデオゲームなど、またはイベント内。俳優は個々のアイテム、またはシリーズ、エピソード、クリップに関連付けられることがあります。 | |
| actors | 俳優、例えばテレビ、ラジオ、映画、ビデオゲームなど。俳優は個々のアイテム、またはシリーズ、エピソード、クリップに関連付けられることがあります。 | |
| addOn | 最初の基本オファーと組み合わせてのみ入手可能な追加のオファー(例:追加料金で利用可能なサプリメントや延長など)。 | |
| additionalName | 人物の追加の名前は、ミドルネームとして使用できます。 | |
| additionalNumberOfGuests | はいと回答する場合、招待者以外に参加するゲストの人数。 | |
| additionalProperty | エンティティの追加特性を表すプロパティと値のペア。例えば、製品機能や、schema.orgに一致するプロパティがない別の特性などです。 注:パブリッシャーは、特定のschema.orgプロパティ(例:https://schema.org/width、https://schema.org/color、https://schema.org/gtin13、…)を使用するように設計されたアプリケーションは、通常、そのようなデータがこれらのプロパティを使用して提供されることを期待し、汎用的なプロパティ/値メカニズムを使用することを期待しないことに注意する必要があります。 |
|
| additionalType | アイテムの追加のタイプで、通常はマイクロデータ構文で外部ボキャブラリーからのより具体的なタイプを追加するために使用されます。これは、何かと、その何かが属するクラスとの関係です。RDFa構文では、複数のタイプには、ネイティブのRDFa構文である「typeof」属性を使用する方が適切です。Schema.orgツールは、追加のタイプ、特に外部で定義されたタイプについて、理解が弱い場合があります。 | |
| additionalVariable | 患者に伝える必要のある、運動処方のあらゆる追加要素。これには、運動の順序、運動の反復回数、定量的な距離、経時的な漸進性などが含まれます。 | |
| address | 商品の物理的な住所。 | |
| addressCountry | 国。例えば、USA。また、2文字のISO 3166-1 alpha-2 国コードも提供できます。 | |
| addressLocality | 住所が存在する地域、およびその地域が存在する地方。例えば、Mountain View。 | |
| addressRegion | 地域が位置する国と、その地域が含まれる場所。例えば、カリフォルニアや、適切な一次レベルの行政区分など。 | |
| administrationRoute | この薬を投与できる経路、例:'oral'。 | |
| advanceBookingRequirement | オファーを受け入れてから、リソースまたはサービスの実際の利用までの時間。 | |
| adverseOutcome | この治療法における起こりうる合併症および/または副作用。有害事象が重篤である(死亡、障害、または永続的な損傷をもたらす、入院を必要とする、または生命を脅かす、または直ちに医療処置を必要とする)ことが判明した場合は、seriouseAdverseOutcomeとしてタグ付けしてください。 | |
| affectedBy | 検査結果に影響を与える薬。 | |
| affiliation | この人物が所属している組織。例えば、学校/大学、クラブ、またはチームなど。 | |
| afterMedia | この方向を実行した後の状況を表すメディアオブジェクト。 | |
| agent | 行為の直接的な実行者または主体(生物または無生物)。例:Johnが本を書いた。 | |
| aggregateRating | アイテムのレビューまたは評価の集計に基づいた全体的な評価。 | |
| aircraft | 航空機の種類(例:「Boeing 747」)。 | |
| album | 音楽アルバム。 | |
| albumProductionType | アルバムのコンテンツの種類による分類:サウンドトラック、ライブアルバム、スタジオアルバムなど。 | |
| albumRelease | このアルバムのリリース。 | |
| albumReleaseType | このアルバムのリリース形態:シングル、EP、またはアルバム。 | |
| albums | 音楽アルバムのコレクション。 | |
| alcoholWarning | この薬を服用中にアルコールを摂取することに関する、あらゆる予防措置、指導、禁忌など。 | |
| algorithm | スコアを計算するためのアルゴリズムまたはルール。 | |
| alignmentType | 学習リソースとフレームワークノード間のアライメントのカテゴリ。推奨値には、'requires'、'textComplexity'、'readingLevel'、および 'educationalSubject' が含まれます。 | |
| alternateName | アイテムのエイリアスです。 | |
| alternativeHeadline | CreativeWorkの副タイトル。 | |
| alumni | 組織の卒業生/関係者。 | |
| alumniOf | その人が卒業生である組織。 | |
| amenityFeature | 宿泊施設の設備の特徴(例:特性またはサービス)。この一般的なプロパティは、その設備が主要な宿泊施設のオファーに含まれているか、追加料金で利用可能かについて言及しません。 | |
| amount | 金額。 | |
| amountOfThisGood | オファーに含まれる商品の数量。 | |
| announcementLocation | SpecialAnnouncementに関連付けられた特定のCivicStructureまたはLocalBusinessを示します。例えば、特定の検査施設や特別な営業時間を持つ事業所などです。より広い地理的範囲(地域全体の隔離など)の場合は、spatialCoverageを使用してください。 | |
| annualPercentageRate | ローン期間にわたる資金の実際の年間コストを単一のパーセンテージ数値で表した、借入(または投資によって生み出される)にかかる年利。これには、取引に関連するあらゆる手数料または追加費用が含まれます。 | |
| answerCount | この質問が受け取った回答の数。 | |
| answerExplanation | Answerに関する段階的な説明、または完全な解説。このAnswerがどのように達成されたかの概要を説明したり、それについてより広範な明確化や声明を含めることができます。 | |
| antagonist | 特定の筋肉の作用を打ち消す筋肉。 | |
| appearance | 何らかのCreativeWorkにおけるClaimの発生を示す。 | |
| applicableLocation | ステータスが適用される場所。 | |
| applicantLocationRequirements | 応募者が応募できる場所。通常、応募者が物理的なオフィスに出勤する必要がないリモートワークの仕事で使用されます。注:これは、国籍または就労ビザの要件に使用しないでください。 | |
| application | リクエストを完了できるアプリケーション。 | |
| applicationCategory | ソフトウェアアプリケーションの種類(例:「Game, Multimedia」)。 | |
| applicationContact | この求人情報に関するお問い合わせ先。 | |
| applicationDeadline | 次期入学サイクルにおいて、プログラムが申請受付を停止する日付。 | |
| applicationStartDate | 次期入学サイクルにおいて、プログラムが申請受付を開始する日付。 | |
| applicationSubCategory | アプリケーションのサブカテゴリ、例: 'Arcade Game'。 | |
| applicationSuite | アプリケーションが属するアプリケーションスイートの名前(例:ExcelはOfficeに属します)。 | |
| appliesToDeliveryMethod | 配送料金または支払い料金の仕様が適用される配送方法。 | |
| appliesToPaymentMethod | 支払料金仕様が適用される支払い方法(s)。 | |
| archiveHeld | コレクション、所蔵品、またはArchiveOrganizationによって保有、保管、または維持されている品物。 | |
| area | ユーザーがブロードキャストサービスに到達できる範囲。 | |
| areaServed | サービスまたは提供される商品が提供される地理的範囲。 | |
| arrivalAirport | フライトが終着する空港。 | |
| arrivalBoatTerminal | ボートが到着するターミナルまたは港。 | |
| arrivalBusStop | バスが到着する停留所または駅。 | |
| arrivalGate | フライトの到着ゲートの識別子。 | |
| arrivalPlatform | 電車が到着するプラットフォーム。 | |
| arrivalStation | 電車旅行が終わる駅。 | |
| arrivalTerminal | フライトの到着ターミナルの識別子。 | |
| arrivalTime | 予想される到着時間。 | |
| artEdition | 作品が複数部制作される場合の部数 - 例えば、限定版20部のプリントの場合、「artEdition」は総部数(この例では「20」)を指します。 | |
| artMedium | 使用素材。(例:オイル、水彩、アクリル、リノプリント、大理石、シアンタイプ、デジタル、リトグラフ、ドライポイント、インタリア、パステル、木版画、鉛筆、複合メディアなど) | |
| arterialBranch | 動脈構造を構成する枝。 | |
| artform | 絵画、ドローイング、彫刻、版画、写真、アッサンブラージュ、コラージュなど。 | |
| articleBody | 記事の本文です。 | |
| articleSection | 雑誌や新聞の記事は、スポーツ、ライフスタイルなどの「セクション」の1つまたは複数に属することがあります。 | |
| artist | 作品の主要なアーティスト、例えば主要なアートワークが水彩やデジタルペイントなどの鉛筆やデジタル線画以外の媒体で行われた場合。 | |
| artworkSurface | アート作品の支持体材料、例:キャンバス、紙、木材、ボードなど。 | |
| aspect | 医療実践において、ページ上で検討される側面、例えば「診断」、「治療」、「原因」、「予後」、「病因」、「疫学」など。 | |
| assembly | ライブラリファイル名 (例: mscorlib.dll, system.web.dll)。 | |
| assemblyVersion | 関連する製品/技術のバージョン。例:.NET Framework 4.5。 | |
| assesses | 記述されている項目は、参照されている用語によって定義された能力または学習成果を評価することを意図しています。 | |
| associatedAnatomy | このエンティティに関連する基礎となる臓器系または構造の解剖学。 | |
| associatedArticle | メディアオブジェクトに関連付けられたNewsArticle。 | |
| associatedMedia | このCreativeWorkをエンコードするメディアオブジェクト。このプロパティは、encodingの同義語です。 | |
| associatedPathophysiology | 該当する場合は、解剖学的システムに関連する病態生理の説明(システムの機械的、物理的、生化学的機能における潜在的な異常な変化を含む)。 | |
| athlete | スポーツチームでプレーするメンバー、コーチとは対照的な選手。 | |
| attendee | イベントに参加する個人または組織。 | |
| attendees | イベントに参加する人。 | |
| audience | 意図された読者層、すなわち、何かが作成された対象となるグループ。 | |
| audienceType | 特定のオーディエンス(例:退役軍人、車の所有者、ミュージシャンなど)に関連付けられたターゲットグループ。 | |
| audio | 埋め込まれた音声オブジェクト。 | |
| authenticator | ユーザーのサブスクリプションを認証する組織。たとえば、多くのメディアアプリでは、メディアを再生する前に、ケーブル/衛星プロバイダーによるサブスクリプションの認証が必要です。 | |
| author | このコンテンツまたは評価の作成者です。作成者は、HTML 5がrelタグを介して作成者を示す特別なメカニズムを提供するという点で特殊です。それはこれと同等であり、相互交換可能です。 | |
| availability | この商品の在庫状況—例えば 在庫あり、在庫切れ、予約受付中、など。 | |
| availabilityEnds | オファーに含まれる製品またはサービスの利用可能期間の終了。 | |
| availabilityStarts | オファーに含まれる製品またはサービスの利用開始日。 | |
| availableAtOrFrom | オファーを入手できる場所(例:店舗所在地)。 | |
| availableChannel | サービスへのアクセス手段(例:電話銀行、ウェブサイト、場所など)。 | |
| availableDeliveryMethod | このオファーで利用可能な配送方法(s)。 | |
| availableFrom | 商品が店舗、ロッカー等で受け取り可能になった時。 | |
| availableIn | 強度が発生する場所。 | |
| availableLanguage | 誰かがアイテム、サービス、または場所で使用する可能性のある言語。IETF BCP 47 標準からの言語コードのいずれかを使用してください。inLanguageも参照してください。 | |
| availableOnDevice | アプリケーションを実行するために必要なデバイス。特定のメーカー/モデルが必要な場合に利用されます。 | |
| availableService | このプロバイダーから利用可能な医療サービス。 | |
| availableStrength | 薬剤の利用可能な剤形および用量。 | |
| availableTest | この検査機関で提供される診断検査または手順。 | |
| availableThrough | この日以降、商品は引き取りできなくなります。 | |
| award | このアイテムが受賞した、またはこのアイテムのために授与された賞。 | |
| awards | このアイテムが受賞した、またはこのアイテムのために授与された賞。 | |
| awayTeam | スポーツイベントの**[away team]**。 | |
| backstory | Article、典型的にはNewsArticleの場合、backstoryプロパティは記事が作成された理由と方法を簡潔に説明するテキスト要約を提供します。ジャーナリズムの現場では、報道プロセス、方法、インタビュー、データソースなどの情報が含まれる場合があります。 | |
| bankAccountType | 銀行口座の種類。 | |
| baseSalary | EmployeeRoleにおけるジョブまたは従業員の基本給。 | |
| bccRecipient | 受信者のサブプロパティ。メッセージのブラインドコピーの受信者。 | |
| bed | 宿泊施設に含まれるベッドの種類。特定の種類のベッドが1つだけの場合、テキストとともにbedを直接使用します。 特定の種類のベッドの数量を示す場合は、BedDetailsのインスタンスを使用してください。より詳細な情報については、amenityFeatureプロパティを使用してください。 | |
| beforeMedia | この方向を実行する前の状況を表すメディアオブジェクト。 | |
| beneficiaryBank | 受益者の銀行口座を運用または受益者への資金をリリースする銀行または銀行の支店、金融機関、または国際金融機関。 | |
| benefits | 職務に関連する特典の説明。 | |
| benefitsSummaryUrl | 特定の標準プランまたはプランバリエーションの給付および保険内容の概要に直接アクセスできるURL。 | |
| bestRating | この評価システムで許可される最大値です。bestRatingが省略された場合、5とみなされます。 | |
| billingAddress | 注文の請求先住所。 | |
| billingDuration | この価格(または価格構成要素)が請求される期間を指定します。たとえば、サブスクリプションまたは支払いプランの契約期間をモデル化するために使用できます。タイプは、DurationまたはNumberのいずれかです(その場合、単位(例:月)はunitCodeプロパティで指定されます)。 | |
| billingIncrement | このプロパティは、請求の基礎となる最小数量と四捨五入の増分を指定します。 測定単位は、unitCodeプロパティで指定されます。 | |
| billingPeriod | 請求書を計算するために使用された時間間隔。 | |
| billingStart | この価格(または価格コンポーネント)が有効になり、請求が開始されるまでの時間を指定します。たとえば、サブスクリプションの最初の1年後に価格を引き上げるモデルを構築するために使用できます。測定単位は、unitCodeプロパティで指定されます。 | |
| biomechnicalClass | 骨のバイオメカニカル特性。 | |
| birthDate | 生年月日。 | |
| birthPlace | 人が生まれた場所。 | |
| bitrate | メディアオブジェクトのビットレート。 | |
| blogPost | このブログの一部である投稿。 | |
| blogPosts | このブログに掲載されている投稿。 | |
| bloodSupply | 心臓から筋肉へ血液を運ぶ血管。 | |
| boardingGroup | 搭乗順序 / 優先度の航空会社固有の指標。 | |
| boardingPolicy | 航空会社が使用する搭乗ポリシーの種類(例:ゾーン制またはグループ制)。 | |
| bodyLocation | 解剖学的構造の体内の位置。 | |
| bodyType | 車両のデザインとボディスタイルを示します(例:ステーションワゴン、ハッチバックなど)。 | |
| bookEdition | 本の{edition}。 | |
| bookFormat | 本の形式。 | |
| bookingAgent | 「bookingAgent」は、予約代行業者として機能する「broker」を示す古い用語です。 | |
| bookingTime | 予約が確定した日時。 | |
| borrower | 参加者のサブプロパティ。貸し出されている物を借りる人物。 | |
| box | ボックスは、2つの点によって形成される矩形によって囲まれた領域です。最初の点は下側の角、2番目の点は上側の角です。ボックスは、スペース文字で区切られた2つの点として表現されます。 | |
| branch | 神経束から分岐する枝。branchOf と混同しないでください。 | |
| branchCode | 事業所を一意に識別する短いテキストコード(「店舗コード」とも呼ばれます)。このコードは通常、親組織によって割り当てられ、構造化されたURLで使用されます。 たとえば、URL http://www.starbucks.co.uk/store-locator/etc/detail/3047 では、「3047」が特定の支店のbranchCodeです。 |
|
| branchOf | このローカルビジネスが属する、もしあれば、より大きな組織。 (解剖学的)branch と混同しないでください。 | |
| brand | 製品またはサービスに関連付けられているブランド(複数可)、または組織または事業者が維持しているブランド(複数可)。 | |
| breadcrumb | ウェブサイトの階層構造を理解し、ナビゲートするのに役立つリンクのセット。 | |
| breastfeedingWarning | 授乳中の母親によるこの薬の使用に関連するあらゆる予防措置、指導、禁忌など。 | |
| broadcastAffiliateOf | この局で放送されるコンテンツを持つメディアネットワーク(s)。 | |
| broadcastChannelId | ブロードキャストサービスがプロバイダーのラインナップ内で識別される一意のアドレス。米国では通常、数字です。 | |
| broadcastDisplayName | チャンネルガイドに表示される名前。多くの米国の提携局では、ネットワーク名です。 | |
| broadcastFrequency | 無線放送に使用される周波数。数値または単純な範囲(例:87-99)。さらに、AMおよびFMラジオチャンネルの周波数に対して、ショートカットイディオムがサポートされています(例:「87 FM」)。 | |
| broadcastFrequencyValue | 特定の放送の周波数(MHz)。 | |
| broadcastOfEvent | スポーツイベントや授賞式など、放送されているイベント。 | |
| broadcastServiceTier | チャンネルへのアクセスに必要なサービスの種類(例:StandardまたはPremium)。 | |
| broadcastSignalModulation | 特定の放送サービスで使用される変調方式(例:FM、AMなど)。 | |
| broadcastSubChannel | 放送に使用されるサブチャンネル。 | |
| broadcastTimezone | サービスがブロードキャストの基準とする、ISO 8601形式のタイムゾーン | |
| broadcaster | 放送サービスを所有または運営する組織。 | |
| broker | 買い手と売り手の間の取引を手配する主体。 ほとんどの場合、ブローカーは取引に関与する製品またはサービスの所有権を取得または放棄することはありません。 主体がブローカー、売り手、買い手のいずれであるか不明な場合は、後者の2つの用語が優先されます。 | |
| browserRequirements | ブラウザの要件を人が読める形式のテキストで指定します。例えば、「HTML5サポートが必要です」などです。 | |
| busName | バスの名前(例:Bolt Express)。 | |
| busNumber | バスの一意な識別子。 | |
| businessDays | 通常、商人が営業する曜日で、営業時間マークアップによって示されます。 | |
| businessFunction | オファーまたはバンドル(TypeAndQuantityNode)のビジネス機能(例:販売、リース、修理、廃棄)。デフォルトは http://purl.org/goodrelations/v1#Sell です。 | |
| buyer | 参加者のサブプロパティ。オブジェクトを購入した参加者/個人/組織。 | |
| byArtist | このアルバムまたは録音を演奏したアーティスト。 | |
| byDay | Recurring Eventが発生する曜日を定義します。DayOfWeekを使用するか、またはiCalのbyDay再帰ルール構文に準拠したTextを使用して指定できます。 | |
| byMonth | 定期的なEventが発生する年の月を定義します。Integerで1~12の範囲で指定します。1は1月です。 | |
| byMonthDay | 再発するEventが発生する月のInteger日(複数可)を定義します。1~31の数値で指定します。 | |
| byMonthWeek | 月間のイベントが繰り返される週(週複数可)を定義します。1~5の整数で指定します。明確にするために、byMonthWeekは、月の第1月曜日や第3月曜日などの概念を示すために、byDayと組み合わせて使用するのが最適です。 | |
| callSign | コールサイン は、人、ラジオ局、テレビ局、または車両を識別するために放送および無線通信で使用されるです。 | |
| calories | カロリーの数。 | |
| candidate | オブジェクトのサブプロパティ。このアクションの候補となる主語。 | |
| caption | このオブジェクトのキャプション。ダウンロード可能な機械形式(クローズドキャプション、字幕など)の場合は、MediaObjectを使用し、encodingFormat を示してください。 | |
| carbohydrateContent | 炭水化物のグラム数。 | |
| cargoVolume | 貨物または手荷物を利用可能な容積。自動車の場合、通常はトランクの容積です。 一般的な単位コード: LTR (リットル), FTQ (立方フィート) 注: minValue および maxValue を使用して範囲を示すことができます。 |
|
| carrier | 「carrier」は、小包配達やフライトの「provider」を示す古い用語です。 | |
| carrierRequirements | アプリケーションの特定のキャリア要件を指定します(例:アプリケーションは特定のキャリアネットワークでのみ動作するように制限される場合があります)。 | |
| cashBack | カード会員特典として、カード会員の純支出額の少額パーセンテージを支払うもの。 | |
| catalog | このデータセットを含むデータカタログ。 | |
| catalogNumber | リリースにおけるカタログ番号。 | |
| category | アイテムのカテゴリです。より大きな記号やスラッシュを使って、カテゴリの階層を非公式に示すことができます。 | |
| causeOf | 引き起こされた状態、合併症、症状、兆候など。 | |
| ccRecipient | 受信者のサブプロパティ。メッセージのコピー送信先。 | |
| character | 創作作品と関連付けられた架空の人物。 | |
| characterAttribute | 架空のキャラクターの特定の側面(スキル、パワー、キャラクターポイント、利点、欠点)を表すデータ。 | |
| characterName | ある演技または演奏の役割で演じられたキャラクターの名前、すなわちPerformanceRoleにおける。 | |
| cheatCode | ゲームのチートコード。 | |
| checkinTime | 宿泊施設にチェックインできる最も早い時間。 | |
| checkoutTime | 宿泊施設からのチェックアウトが可能な最新の時間。 | |
| childMaxAge | 子供の最大年齢。 | |
| childMinAge | 子供の最低年齢。 | |
| children | その人の子供。 | |
| cholesterolContent | コレステロールのミリグラム数。 | |
| circle | 円は、指定された緯度と経度を中心とした、指定された半径の円形の領域です。円は、半径(メートル単位)に続くペアで表現されます。 | |
| citation | 別の創作物(別の出版物、ウェブページ、学術記事など)への言及または参照。 | |
| claimReviewed | ClaimReview でレビューされた特定の主張の簡単な概要。 | |
| clincalPharmacology | 薬物の吸収と排泄、それらを含む濃度(薬物動態、pK)と生物学的効果(薬力学、pD)の説明。 | |
| clinicalPharmacology | 薬物の吸収と排泄、それらを含む濃度(薬物動態、pK)および生物学的効果(薬力学、pD)の説明。 | |
| clipNumber | クリップが順序付けられたクリップのグループ内で持つ位置。 | |
| closes | その曜日における場所またはサービスの閉店時間。 | |
| coach | スポーツチームのコーチングロールで行動する人。 | |
| code | エンティティの医学コードで、ICD-9、DiseasesDB、MeSH、SNOMED-CT、RxNormなどの管理された語彙またはオントロジーから取得されます。 | |
| codeRepository | コンパイルされていない、人が読めるコードと関連コードが配置されているリポジトリへのリンク(SVN、github、CodePlex)。 | |
| codeSampleType | コードサンプルの種類:完全(コンパイル可能)なソリューション、コードスニペット、インラインコード、スクリプト、テンプレート。 | |
| codeValue | 値を一意に識別する短いテキストコード。 | |
| codingSystem | コーディングシステム、例:'ICD-10'。 | |
| colleague | その人の同僚。 | |
| colleagues | その人の同僚。 | |
| collection | オブジェクトのサブプロパティ。アクションのコレクション対象。 | |
| collectionSize | Collection内のアイテム数。 | |
| color | 製品の色。 | |
| colorist | インクで描かれた絵に色を加える人。 | |
| comment | コメント、通常はユーザーからのものです。 | |
| commentCount | このクリエイティブワーク(例:記事、質問、または回答)が受け取ったコメント数。これは、コメントシステムを備えたWebサイトで公開された作品に最も適用されます。追加のコメントが他の場所に存在する可能性もあります。 | |
| commentText | UserCommentの本文。 | |
| commentTime | UserComment が作成された時刻。 | |
| competencyRequired | Educational Occupational CredentialまたはLearningResourceを理解するなど、何かを行うために、個人またはその他のエンティティによって証明されなければならない知識、スキル、能力、または個人的な属性。 | |
| competitor | スポーツイベントの競技者。 | |
| composer | 楽曲を作曲した人または、何らかのイベントで演奏される作品の作曲者。 | |
| comprisedOf | 何か別のものに物理的に含まれるものを特定すること。通常、解剖学的システムを構成する臓器などの基盤となる解剖学的構造について使用されます。 | |
| conditionsOfAccess | アイテムの入手可能性またはアクセス方法に影響を与える条件。通常、ArchiveOrganizationが保管するArchiveComponentのような実世界のアイテムに使用されます。このプロパティは、一般的なWebアクセス制御メカニズムとして使用するのには適していません。自然言語でのみ表現されます。 例えば、「閲覧室での予約制」または「ログインアカウントからのみアクセス可能」など。 |
|
| confirmationNumber | 与えられた注文または支払いを受け取ったことを確認する番号。 | |
| connectedTo | この構造体が接続されているその他の解剖学的構造物。 | |
| constrainingProperty | 示されたタイプ(populationType経由)に対応するエンティティの集合に関して、StatisticalPopulationを定義するための制約として使用されるプロパティを示します。 | |
| contactOption | この接点(例えば、フリーダイヤル番号や聴覚障害者向けサポートなど)で利用可能なオプション。 | |
| contactPoint | 個人または組織の連絡先。 | |
| contactPoints | 個人または組織の連絡先。 | |
| contactType | 人物または組織は、異なる目的のために異なる連絡先を持つことができます。例えば、営業連絡先、広報連絡先などです。このプロパティは、連絡先の種類を指定するために使用されます。 | |
| contactlessPayment | RFIDまたはNFC技術を使用して、消費者がデビットカード、クレジットカード、またはスマートカードを介して製品またはサービスを安全に購入する方法。 | |
| containedIn | 場所とそれを含むものの間の基本的な包含関係。 | |
| containedInPlace | 場所とそれを含むものの間の基本的な包含関係。 | |
| containsPlace | 場所と、それを含む別の場所との間の基本的な包含関係。 | |
| containsSeason | メディアシリーズの一部であるシーズン。 | |
| contentLocation | コンテンツ内で描写または記述されている場所。例えば、写真や絵画の中の場所。 | |
| contentRating | コンテンツの公式レーティング—例えば、「MPAA PG-13」。 | |
| contentReferenceTime | イベント内のある特定の瞬間を強調する作品(例:記事、ビデオオブジェクトなど)における、創造的作品によって描写される具体的な時間。 | |
| contentSize | ファイルサイズは(メガ/キロ)バイト単位です。 | |
| contentType | EntryPointレスポンスでサポートされているコンテンツタイプ(タイプ)です。 | |
| contentUrl | メディアオブジェクトの実際のバイト数。例えば、画像ファイルやビデオファイルなど。 | |
| contraindication | この治療法の禁忌。 | |
| contributor | CreativeWorkまたはEventの二次的な貢献者。 | |
| cookTime | 実際に料理を作るのにかかる時間、ISO 8601 duration形式で。 | |
| cookingMethod | 調理方法、例えば、フライ、蒸し、… | |
| copyrightHolder | CreativeWorkの法的著作権を保有するパーティー。 | |
| copyrightNotice | この創作物に関する著作権についてのお知らせです。この作品の著作権者は、[著作権者名]です。 | |
| copyrightYear | CreativeWorkに対して主張された著作権が最初に主張された年。 | |
| correction | CreativeWorkに対する修正を示します。CorrectionComment、テキスト、または別のドキュメントを通じて行われます。 | |
| correctionsPolicy | Organization(例:NewsMediaOrganization)向けの、誤りに対する開示および修正方針を記述した声明。 | |
| costCategory | コストのカテゴリ、例えば卸売、小売、償還上限など。 | |
| costCurrency | 薬のコストの通貨(3文字)。参照:http://en.wikipedia.org/wiki/ISO_4217。 | |
| costOrigin | コストデータの出所を把握するための追加詳細。例えば、「Medicare Part B」。 | |
| costPerUnit | 薬1単位あたりの費用。 | |
| countriesNotSupported | アプリケーションがサポートされていない国。2文字のISO 3166-1 alpha-2 国コードも提供できます。 | |
| countriesSupported | アプリケーションがサポートされている国。2文字のISO 3166-1 alpha-2 国コードも提供できます。 | |
| countryOfOrigin | 映画または番組の制作会社または個人の主要な事務所の所在地国。 | |
| course | locationのサブプロパティ。このアクションが行われたコース。 | |
| courseCode | コースCourseを識別する識別子で、コースproviderによって使用されます(例:CS101または6.001)。 | |
| courseMode | コースインスタンスの配信媒体または手段、または学習モード(テキストラベル(例:「online」、「onsite」、または「blended」、「synchronous」、または「asynchronous」、「full-time」、または「part-time」)として、または制御語彙の用語へのURL参照として(例:https://ceds.ed.gov/element/001311#Asynchronous ))。 | |
| coursePrerequisites | コース受講の要件。別のCourseの修了、または「担当教員の許可」のようなテキストによる記述である場合があります。要件は、AlignmentObjectを用いて参照される前提条件の能力である場合があります。 | |
| courseWorkload | 学生に求められる学習量は、しばしば週ごとまたは月ごとの数値で示され、種類別に分類されることがあります。例えば、「週に2時間の講義、1時間の実験、3時間の自主学習」などです。 | |
| coverageEndTime | イベントのライブブログの終了予定時刻。イベント終了後も報道が続く場合があります。 | |
| coverageStartTime | イベントのライブブログを開始する時間です。ただし、イベントの開始時間よりも前にカバレッジが開始される場合があります。LiveBlogPosting は、カバレッジが始まる前にも作成される場合があります。 | |
| creativeWorkStatus | クリエイティブ作品のライフサイクルにおける段階に関するステータス。例としては、Incomplete、Draft、Published、Obsoleteなどがあります。一部の組織は、出版ライフサイクルの段階に対する用語のセットを定義しています。 | |
| creator | このCreativeWorkの作成者/著者。これは、CreativeWorkのAuthorプロパティと同じです。 | |
| credentialCategory | 説明されている資格の種類またはタイプ。例えば、「degree」、「certificate」、「badge」、またはより具体的な用語。 | |
| creditText | 公開されたクリエイティブワークに関連する人物および/または組織をクレジットするために使用できるテキスト。 | |
| creditedTo | リリースがクレジットされているグループで、byArtistと異なる場合に使用します。例えば、Red and Blueは「Stefani Germanotta Band」にクレジットされていますが、by Lady Gagaです。 | |
| cssSelector | CSSセレクター。例えば、SpeakableSpecificationまたはWebPageElementのものです。後者の場合、ページ内の複数のマッチは、単一の概念的な「Webページ要素」を構成することがあります。 | |
| currenciesAccepted | 受け入れられる通貨。 標準形式を使用してください:ISO 4217通貨形式 例: "USD"; ティッカーシンボル 仮想通貨の場合、例: "BTC"; 地域通貨システム (LETS) およびその他の通貨タイプの場合は、よく知られている名称を使用してください。例: "Ithaca HOUR"。 |
|
| currency | 金額が表される通貨。 標準形式を使用します:ISO 4217通貨形式 例:"USD";ティッカーシンボル 仮想通貨の場合、例:"BTC";地域通貨システム (LETS) およびその他の通貨タイプ(例:"Ithaca HOUR")。 |
|
| currentExchangeRate | 通貨の現在の価格。 | |
| customer | 注文または請求書を支払う当事者。 | |
| cutoffTime | 注文の締め切り時間は、加盟店がその日に受け付けた注文をそれ以降処理しなくなる時間を記述するものです。締め切り時間後に処理された注文の場合、配達時間の見積もりに1日追加されます。このプロパティは、通常、ShippingRateSettings パブリケーションパターンを介して使用されることが予想されます。時間はISO-8601時間形式で示されます。例えば、"23:30:00-05:00"は、協定世界時(UTC)より5時間遅い東部標準時(EST)の午後6時30分を表します。 | |
| cvdCollectionDate | collectiondate - 患者数集計日。 | |
| cvdFacilityCounty | NHSN施設のデータレコードが適用される郡の名前。施設を特定するにはcvdFacilityIdを使用してください。他の詳細を提供するには、HospitalエントリでhealthcareReportingDataを使用できます。 | |
| cvdFacilityId | このデータレコードが適用されるNHSN施設の識別子です。郡を示すにはcvdFacilityCountyを使用してください。その他の詳細を提供するには、HospitalエントリでhealthcareReportingDataを使用できます。 | |
| cvdNumBeds | numbeds - 入院ベッド:すべての常勤、許可、および緊急時(サージ)に使用される入院患者用のベッドを含む入院ベッド。 | |
| cvdNumBedsOcc | numbedsocc - 入院ベッド稼働率:稼働中の入院ベッドの総数。 | |
| cvdNumC19Died | numc19died - DEATHS: 病院、救急部門、または一時的な収容場所で死亡した、新型コロナウイルス感染症が疑われるか確認された患者。 | |
| cvdNumC19HOPats | numc19hopats - 入院発症:NHSN 入院ケア施設に入院し、入院後14日以上経過後に疑いまたは確認されたCOVID-19の発症患者。 | |
| cvdNumC19HospPats | numc19hosppats - 入院患者: 入院治療を受けており、COVID-19の疑いまたは確認が取れている患者。 | |
| cvdNumC19MechVentPats | numc19mechventpats - 入院および人工呼吸器装着:NHSNの入院ケア施設に入院し、COVID-19が疑われるか確認された患者で、人工呼吸器を使用している患者。 | |
| cvdNumC19OFMechVentPats | numc19ofmechventpats - ED/OVERFLOWおよびVENTILATED:入院ベッドを待機しているEDまたはオーバーフロー場所にいる、または人工呼吸器を使用している、新型コロナウイルス感染症が疑われるまたは確認された患者。 | |
| cvdNumC19OverflowPats | numc19overflowpats - ED/OVERFLOW: COVID-19が疑われるか確認された患者で、EDまたは任意のオーバーフロー場所で入院ベッドを待っている患者。 | |
| cvdNumICUBeds | numicubeds - ICU BEDS: 入院集中治療室(ICU)のスタッフ配置ベッドの総数。 | |
| cvdNumICUBedsOcc | numicubedsocc - ICU BED OCCUPANCY: 入院中のスタッフ配置されたICUベッドの総占有数。 | |
| cvdNumTotBeds | numtotbeds - 全ての病院ベッド:全ての入院および外来ベッドの合計数。スタッフ付き、ICU、許可、および入院または外来患者に使用される増設(サージ)ベッドを含む。 | |
| cvdNumVent | numvent - 機械換気器:利用可能な換気器の総数。 | |
| cvdNumVentUse | numventuse - 機械換気器使用台数: 使用中の換気器の総数。 | |
| dataFeedElement | データフィード内の項目。データフィードには多くの要素が含まれる場合があります。 | |
| dataset | このカタログに含まれるデータセット。 | |
| datasetTimeInterval | データセットの有効期間の範囲、例えば2011年の国勢調査データセットの場合、年2011(ISO 8601時間間隔形式)。 | |
| dateCreated | CreativeWork が作成された、またはアイテムが DataFeed に追加された日付。 | |
| dateDeleted | DataFeedからアイテムが削除された日時。 | |
| dateIssued | チケットの発行日。 | |
| dateModified | CreativeWork が最後に修正された日付、または DataFeed 内のエントリが最後に修正された日付。 | |
| datePosted | オンラインリストの公開日。 | |
| datePublished | 最初の放送/出版日。 | |
| dateRead | 受信者が単一の場合、受信者がメッセージを読み取った日時。 | |
| dateReceived | 単一の受信者が存在する場合のメッセージ受信日時。 | |
| dateSent | メッセージが送信された日時。 | |
| dateVehicleFirstRegistered | 車両の最初の登録日を、それぞれの公的機関において。 | |
| dateline | 配信日時は、ニュース記事に含まれる、記事が書かれたまたは送られた場所と時間を記述する短いテキストですが、日付はしばしば省略されます。場所名のみが記載されることもあります。 配信日時に関連する情報の構造化された表現は、locationCreated(作品が作成された場所、例えばニュースレポートが書かれた場所)を使用して、より明示的に表現することもできます。コンテンツ内で描かれたまたは記述された場所については、contentLocationを使用してください。 配信日時の要約は、自動処理よりも人間の読者向けであり、大きく異なる場合があります。例:「ベイルート、レバノン、6月2日」、「パリ、フランス」、「2017年12月19日 11:43AM ワシントンからの報告」、「北京/モスクワ」、「ケソンシティ、フィリピン」。 |
|
| dayOfWeek | これらの営業時間が有効な曜日。 | |
| deathDate | 死亡日。 | |
| deathPlace | 人が亡くなった場所。 | |
| defaultValue | 入力のデフォルト値です。リテラルを期待するプロパティの場合は、デフォルトはリテラル値となり、オブジェクトを期待するプロパティの場合は、現在の値のいずれかへのID参照となります。 | |
| deliveryAddress | 宛先住所。 | |
| deliveryLeadTime | 注文受領から、商品が倉庫から発送されるか、あるいは配送方法が現地受け取りの場合には準備が完了するまでの典型的な遅延。 | |
| deliveryMethod | instrument のサブプロパティ。配信方法。 | |
| deliveryStatus | パッケージが各配送区間を通過するたびに、新しいエントリが追加されます(発送から最終配達まで)。 | |
| deliveryTime | 注文受領から商品が最終顧客に届くまでにかかる総遅延時間。 | |
| department | 組織と、その組織の部門との関係性。異なるURL、ロゴ、営業時間などを許可する組織としても記述されます。例えば、薬局を併設した店舗、またはカフェを併設したパン屋などです。 | |
| departureAirport | フライトが出発する空港。 | |
| departureBoatTerminal | ボートが出発するターミナルまたは港。 | |
| departureBusStop | バスが出発する停留所または駅。 | |
| departureGate | フライトの出発ゲートの識別子。 | |
| departurePlatform | 電車が出発するプラットフォーム。 | |
| departureStation | 電車が出発する駅。 | |
| departureTerminal | フライトの出発ターミナルの識別子。 | |
| departureTime | 予定された出発時刻。 | |
| dependencies | 記事のステップを完了するために必要な前提条件。 | |
| depth | アイテムの深さ。 | |
| description | 商品の説明。 | |
| device | アプリケーションを実行するために必要なデバイス。特定のメーカー/モデルが必要な場合に利用されます。 | |
| diagnosis | 鑑別診断プロセスにおいて考慮された、1つまたは複数の代替条件であり、診断プロセスの出力。 | |
| diagram | 構造および/またはその構成要素のサブ構造、および/または他の構造との接続を説明する図を含む画像。 | |
| diet | instrumentのサブプロパティ。このアクションで使用されたdiet。 | |
| dietFeatures | 食事プランに特化した栄養情報。避けるべき食品、摂取すべき食品、およびUSDAまたはその他の規制機関が承認した食事ガイドラインからの特定の変更/逸脱に関する食事推奨事項が含まれる場合があります。 | |
| differentialDiagnosis | その状態に対する鑑別診断の一つ。具体的には、この疾患が類似した徴候および症状群を引き起こす他の疾患と区別される際に、通常、認知プロセスの後半で考慮される、密接に関連する、または競合する診断。これにより、患者において最も簡潔な診断または診断に到達する。 | |
| director | テレビ、ラジオ、映画、ビデオゲームなどのコンテンツ、またはイベントのディレクター。ディレクターは、個々のアイテム、またはシリーズ、エピソード、クリップに関連付けられることがあります。 | |
| directors | テレビ、ラジオ、映画、ビデオゲームなどのコンテンツのディレクター。ディレクターは、個々のアイテム、またはシリーズ、エピソード、クリップに関連付けられることがあります。 | |
| disambiguatingDescription | 説明のサブプロパティ。他の類似する項目と区別するために使用される項目の簡単な説明です。説明が区別に役立つためには、他のプロパティ(特に、name)からの情報が必要となる場合があります。 | |
| discount | 注文に適用された割引額(Any discount applied (to an Order))。 | |
| discountCode | 割引を適用するためのコード。 | |
| discountCurrency | 割引の通貨。 標準形式を使用してください:ISO 4217 通貨形式 例: "USD"; ティッカーシンボル 仮想通貨の場合、例: "BTC"; 地域通貨システム (LETS) およびその他の通貨タイプについては、例: "Ithaca HOUR"。 |
|
| discusses | UserCommentに関連付けられたCreativeWorkを指定します。 | |
| discussionUrl | CreativeWorkのコメントを含むページへのリンク。 | |
| diseasePreventionInfo | 病気予防に関する情報。 | |
| diseaseSpreadStatistics | 疾病の広がりに関する統計情報で、WebContent として、または Dataset として直接記述されるもの、またはデータセット内の特定の Observation です。WebContent URL が 提供された場合、示されたページには、そのようなマークアップがさらに含まれている可能性があります。 | |
| dissolutionDate | この組織が解散した日付。 | |
| distance | 移動距離、例えば運動や旅行など。 | |
| distinguishingSign | 鑑別診断において、この診断を他のものと区別するために使用できる兆候および症状の1つ。 | |
| distribution | このデータセットのダウンロード可能な形式は、特定の場所の特定の形式です。 | |
| diversityPolicy | Organization(例:NewsMediaOrganization)による多様性方針に関する声明。NewsMediaOrganizationの場合、人員構成と情報源の両方におけるニュースルームの多様性方針を説明する声明であり、通常は人員構成データを提供します。 | |
| diversityStaffingReport | Organization(しばしば、必ずしもそうではないがNewsMediaOrganization)向けの、人員の多様性に関する報告書。ニュースの文脈では、例えばASNEやRTDNA(米国)の報告書、または自己申告によるものが考えられます。 | |
| documentation | Web APIについて、より詳細に説明したドキュメント。 | |
| doesNotShip | shippingDestinationへの配送が利用できないことを示します。 | |
| domainIncludes | プロパティが使用されることが想定されるクラス(のいずれか)に関連付けます。 | |
| domiciledMortgage | 借り手が、物件所在地となる管轄区域の居住者であるかどうか。 | |
| doorTime | 入場開始時刻は、{時間}です。 | |
| dosageForm | この薬/サプリメントが入手可能な剤形、例:'tablet'、'suspenstion'、'injection'。 | |
| doseSchedule | 薬剤の投与スケジュールは、使用タイプに基づいて、観察された、推奨される、または最大投与量に基づいた、特定の集団に対するものです。 | |
| doseUnit | 投与量の単位、例:'mg'。 | |
| doseValue | 投与量の値、例えば 500。 | |
| downPayment | 高額な商品/サービスの購入時に現金で行われる支払いの一種です。この支払いは通常、購入金額全体の割合の一部を表します。 | |
| downloadUrl | ファイルがダウンロード可能な場合、バイナリをダウンロードするURL。 | |
| downvoteCount | この質問、回答、またはコメントがコミュニティから受け取ったダウンボートの数。 | |
| drainsTo | 静脈がドレナージされる血管。 | |
| driveWheelConfiguration | 駆動輪の構成、すなわち、車両のエンジンからパワートレインを介してどの路輪がトルクを受けるか。 | |
| dropoffLocation | レンタカーの返却場所。 | |
| dropoffTime | レンタカーの返却場所と日時。 | |
| drug | 薬剤または投薬処置で使用される薬の指定。 | |
| drugClass | この薬剤が属する薬剤のクラス(例:スタチン)。 | |
| drugUnit | 薬剤の測定単位、例:'5 mg錠'。 | |
| duns | 組織または事業者を識別するためのダン&ブラッドストリートのDUNS番号。 | |
| duplicateTherapy | この治療を複製または重複する療法。 | |
| duration | ISO 8601 日付形式で表される項目の期間(映画、音声録音、イベントなど)。 | |
| durationOfWarranty | 保証の期間。一般的なunitCodeの値は、年を示すANN、月を示すMON、日を示すDAYです。 | |
| duringMedia | この方向を実行している間の状況を表すメディアオブジェクト。 | |
| earlyPrepaymentPenalty | ローンを早期に返済した場合に支払うべき罰金額。 | |
| editEIDR | ある映画またはテレビ作品の特定の編集/版を示す EIDR (Entertainment Identifier Registry) identifier。 例えば、「ゴーストバスターズ」という映画の titleEIDR は "10.5240/7EC7-228A-510A-053E-CBB8-J" であり、"10.5240/1F2A-E1C5-680A-14C6-E76B-I" や "10.5240/8A35-3BEE-6497-5D12-9E4F-3" など、複数の編集版が存在します。 Movie や TVEpisode のような schema.org タイプは、作品自体と、その複数の表現の両方に使用できるため、一般的な説明には titleEIDR のみを使用することも、より編集版に特化した説明には editEIDR と共に使用することも可能です。 |
|
| editor | CreativeWorkを編集した人物を指定します。 | |
| eduQuestionType | 学習リソースの一部である質問(例:クイズ)の場合、eduQuestionTypeは質問の形式を示します。例:「Multiple choice」、「Open ended」、「Flashcard」。 | |
| educationRequirements | 職務または職業に必要な学歴。 | |
| educationalAlignment | 確立された教育フレームワークへの整合性。 このプロパティは、リソースがコンピテンシーをteachesまたはassessesすることを表現するなど、整合性の性質を単純なプロパティで記述できる場合は使用しないでください。 |
|
| educationalCredentialAwarded | このコースまたはプログラムを修了した結果として授与される資格、賞、証明書、卒業証書、またはその他の教育資格の説明。 | |
| educationalFramework | 記述されているリソースが整合するフレームワーク。 | |
| educationalLevel | 教育または訓練の文脈における進捗度合いのレベル。教育レベルの例としては、「beginner」、「intermediate」、または「advanced」などが挙げられ、正式なレベル指標のセットも含まれます。 | |
| educationalProgramMode | courseModeと同様に、プログラム全体の配信媒体または手段です。値は、テキストラベル(例: "online", "onsite", "blended"; "synchronous", "asynchronous"; "full-time", "part-time")または、制御語彙からの用語へのURL参照(例: https://ceds.ed.gov/element/001311#Asynchronous )のいずれかになります。 | |
| educationalRole | 教育的役割の教育的聴衆。 | |
| educationalUse | 教育の文脈における作品の目的;例えば、「{assignment}」、「{group work}」。 | |
| elevation | 場所の標高(WGS 84)。値は「NUMBER UNITOFMEASUREMENT」の形式(例:「1,000 m」、「3,200 ft」)である場合があり、数値のみの場合はメートル単位の値とみなします。 | |
| eligibilityToWorkRequirement | この仕事に応募する申請者にとって必要な、国籍、ビザ、その他の書類などの法的要件。 | |
| eligibleCustomerType | 指定されたオファーが有効な顧客のタイプ(タイプ)。 | |
| eligibleDuration | 提示されたオファーが有効な期間。 | |
| eligibleQuantity | オファーまたは価格仕様が有効な発注数量の区間と単位。これにより、特定の運賃が特定の数量に対してのみ有効である、といった指定が可能になります。 | |
| eligibleRegion | ISO 3166-1 (ISO 3166-1 alpha-2) または ISO 3166-2 コード、場所、または、オファーまたは配送料金の仕様が有効な地理的・政治的地域(複数可)の GeoShape。 ineligibleRegion も参照してください。 |
|
| eligibleTransactionVolume | 取引金額、またはオファーや価格指定が有効な金額単位。例えば、最小購入数量を示すため、一定金額以上の注文で送料無料を表現するため、またはクレジットカードの利用を一定の最小金額以上の購入に限定するために使用されます。 | |
| メールアドレス。 | ||
| embedUrl | 特定の動画のプレイヤーを指すURL。一般的には、src要素のembedタグ内の情報であり、locタグの内容とは異なるはずです。 |
|
| emissionsCO2 | g/km単位でのCO2排出量。QuantitativeValueと組み合わせて使用する場合は、「g/km」をその値のunitTextプロパティに入力してください。「g/km」に対応するUN/CEFACT共通コードが存在しないため。 | |
| employee | この組織で働いている人。 | |
| employees | この組織で働く人々。 | |
| employerOverview | このポジションにおける雇用主、キャリアの機会、および職場環境の説明。 | |
| employmentType | 雇用形態(例:フルタイム、パートタイム、契約社員、派遣、季節雇用、インターンシップ)。 | |
| employmentUnit | 従業員が報告する部署、ユニット、および/または業務を行う施設を示します。 | |
| encodesCreativeWork | このメディアオブジェクトによってエンコードされたCreativeWork。 | |
| encoding | このCreativeWorkをエンコードするメディアオブジェクト。このプロパティはassociatedMediaのシノニムです。 | |
| encodingFormat | メディアタイプは通常、MIME形式で表現されます(IANAサイトおよびMDNリファレンスを参照)。例:ソフトウェアアプリケーションバイナリの場合はapplication/zip、.mp3の場合はaudio/mpegなど。 CreativeWorkが複数のメディアタイプ表現を持つ場合、各MediaObjectと特定のencodingFormat情報を表すためにencodingを使用できます。 登録されていない、またはニッチなエンコーディングやファイル形式は、代わりに最も適切なURLで示すことができます。例:WebページやWikipedia/Wikidataのエントリを定義します。 |
|
| encodingType | EntryPointリクエストでサポートされているエンコーディングタイプは{supported encoding type(s)}です。 | |
| encodings | このCreativeWorkをエンコードするメディアオブジェクト。 | |
| endDate | アイテムの終了日時(ISO 8601日付形式)。 | |
| endOffset | 作品の開始からの秒数で表されるクリップの終了時間。 | |
| endTime | 何かのendTime。予約されたイベントやサービス(例:FoodEstablishmentReservation)の場合、終了が予想される時間です。一定期間にわたるアクションの場合、アクションが実行された時間です。例:ジョンは1月から12月まで本を執筆しました。メディア(オーディオやビデオを含む)の場合、より大きなファイル内のクリップの終了時間のオフセットです。 Eventは、日付と時刻を表す場合でも、startTime/endTimeではなくstartDate/endDateを使用することに注意してください。この状況は将来の改訂で明確になる可能性があります。 |
|
| endorsee | 参加者のサブプロパティ。支援を受けている個人/組織。 | |
| endorsers | 計画を支持する人々または組織。 | |
| energyEfficiencyScaleMax | 製品が属する製品カテゴリの、規制されたEUのエネルギー消費スケールにおける最もエネルギー効率の良いクラスを指定します。例えば、2020年1月1日以降に市場に出回るテレビのエネルギー消費量は、DからA+++までのスケールで評価されます。 | |
| energyEfficiencyScaleMin | 製品が属する製品カテゴリの、規制されたEUのエネルギー消費スケールにおける最もエネルギー効率の低いクラスを指定します。例えば、2020年1月1日以降に市場に出回るテレビのエネルギー消費量は、DからA+++までのスケールで評価されます。 | |
| engineDisplacement | 内燃機関のシリンダー内のすべてのピストンが単一の動きで掃引する容積。 一般的な単位コード: CMQ (立方センチメートル), LTR (リットル), INQ (立方インチ) * 注記1: valueReference プロパティを使用して、与えられた値がどのように決定されたかに関する情報にリンクできます。 * 注記2: minValue および maxValue を使用して範囲を示すことができます。 |
|
| enginePower | 車両のエンジンの出力。
一般的な単位コード: キロワットの場合は KWT、ブレーキ馬力の場合は BHP、メトリック馬力 (PS、1 PS = 735,49875 W) の場合は N12
|
|
| engineType | 車両を動力源とするエンジンまたはエンジンの種類。 | |
| entertainmentBusiness | locationのサブプロパティ。アクションが発生したエンターテイメントビジネス。 | |
| epidemiology | 関連患者の特性(年齢、性別、人種など) | |
| episode | シリーズまたはシーズン内のテレビ、ラジオ、またはゲームメディアのエピソード。 | |
| episodeNumber | エピソードが順序付けられたエピソードのグループ内で持つ位置。 | |
| episodes | TV/ラジオシリーズまたはシーズンのエピソード。 | |
| equal | この定性値に対する順序関係は、主語がオブジェクトと等しいことを示します。 | |
| error | 失敗したアクションについて、失敗の原因に関する詳細情報。 | |
| estimatedCost | 命令を実行する際に消費される供給物または供給物の推定コスト。 | |
| estimatedFlightDuration | フライトの推定所要時間。 | |
| estimatedSalary | 業界、職種、場所など、さまざまな変数を基に、求人または職種に対する推定給与。推定給与は、採用組織ではなく、外部組織によって計算されることが多く、採用組織がその推定値にコミットしているとは限りません。 | |
| estimatesRiskOf | リスクが推定されている状態、合併症、または症状。 | |
| ethicsPolicy | ジャーナリズムおよび出版慣行、またはRestaurantの食品調達方針を説明するページに関する、NewsMediaOrganizationの倫理規定に関する声明。{{NewsMediaOrganization}の場合、倫理規定は通常、組織が期待する個人的、組織的、および企業倫理の基準を説明する声明です。 | |
| event | この場所、組織、または行動に関連する今後のイベントまたは過去のイベント。 | |
| eventAttendanceMode | イベントの eventAttendanceMode は、オンライン、オフライン、またはその組み合わせで発生するかどうかを示します。 | |
| eventSchedule | Event と Schedule を関連付けます。一連の繰り返しイベントのデータそのものよりも、スケジュールを共有することが好ましい場合があります。たとえば、ウェブサイトやアプリケーションは、個々のイベントのデータを提供するよりも、週ごとのジムのクラスのスケジュールを公開することを好む場合があります。スケジュールはアプリケーションによって処理され、今後のイベントをカレンダーに追加できます。このプロパティを使用して Schedule と関連付けられた Event は、startDate または endDate プロパティを持つべきではありません。これらは代わりに、関連付けられた Schedule 内で定義されます。これにより、データを使用するクライアントにとっての曖昧さを回避します。このプロパティには、異なるスケジュール(たとえば、異なる月や季節の場合)を指定するために、繰り返しの値を含めることができます。 | |
| eventStatus | イベントのイベントStatusは、そのステータスを表します。特に、イベントがキャンセルまたは再スケジュールされた場合に役立ちます。 | |
| events | この場所または組織に関連する今後のイベントまたは過去のイベント。 | |
| evidenceLevel | ガイドラインの策定に使用されたデータの証拠の強さ(列挙)。 | |
| evidenceOrigin | ガイダンスの策定に使用されたデータの出典、例:RCT、コンセンサス意見など。 | |
| exampleOfWork | この作品が例/インスタンス/実現/派生である創造的作品。 | |
| exceptDate | DateまたはDateTimeの間に、予定されているEventが開催されないことを定義します。このプロパティにより、Scheduleに対する例外を指定できます。例外がDateTimeとして指定された場合、その特定の日時開始予定だったイベントのみがスケジュールから除外されます。例外がDateとして指定された場合、その24時間以内にスケジュールされているすべてのイベントがスケジュールから除外されます。これにより、スケジュールされているすべてのイベントを個別に列挙することなく、1日全体をスケジュールから除外できます。 | |
| exchangeRateSpread | ブローカーまたはその他の仲介業者が外国為替を買い売りする価格の差。 | |
| executableLibraryName | ライブラリファイル名 (例: mscorlib.dll, system.web.dll)。 | |
| exerciseCourse | locationのサブプロパティ。このアクションが行われたコース。 | |
| exercisePlan | instrument のサブプロパティ。このアクションで使用されたエクササイズプラン。 | |
| exerciseRelatedDiet | instrumentのサブプロパティ。このアクションで使用されたdiet。 | |
| exerciseType | 筋力トレーニング、柔軟性トレーニング、エアロビクス、心臓リハビリテーションなど、運動または活動の種類。 | |
| exifData | このオブジェクトのExifデータ。 | |
| expectedArrivalFrom | 荷物が到着する可能性のある最も早い日付。 | |
| expectedArrivalUntil | パッケージが到着する可能性のある最新の日付。 | |
| expectedPrognosis | 医学的状態の短期または長期的な見込み。 | |
| expectsAcceptanceOf | ユーザーがアクションを実行する前に受け入れる必要のあるオファーです。例えば、ユーザーはそれを視聴する前に映画を購入する必要がある場合があります。 | |
| experienceInPlaceOfEducation | JobPostingが、正式な学歴要件(educationRequirementsで示される)の代わりに、職務経験(OccupationalExperienceRequirementsで示される)を受け入れるかどうかを示します。trueの場合、これらの要件のいずれか一方を満たせば十分であることを示します。 | |
| experienceRequirements | 職務または職種に必要なスキルと経験の説明。 | |
| expertConsiderations | 計画に関連する医学専門家のアドバイス。 | |
| expires | コンテンツが期限切れとなり、もはや有用でなくなったり、利用できなくなったりする日付。例えば、VideoObjectやNewsArticleで、その可用性や関連性が時間的に制限されている場合、またはClaimReviewのファクトチェックで、発行者が特定の期日以降、それがもはや関連性を持たない(または強調する価値がない)可能性があることを示したい場合などです。 | |
| familyName | 名字。アメリカでは、Personのラストネーム。 | |
| fatContent | 脂肪のグラム数。 | |
| faxNumber | ファックス番号。 | |
| featureList | このアプリケーションが提供する機能またはモジュール(および他のアプリケーションで必要となる可能性のあるもの)。 | |
| feesAndCommissionsSpecification | 金融商品クラス、または金融サービス組織によって適用される手数料、手数料、およびその他の条件の説明。 | |
| fiberContent | 食物繊維のグラム数。 | |
| fileFormat | コンテンツのメディアタイプ。通常はMIME形式(IANAサイトを参照)で、例えばSoftwareApplicationバイナリのapplication/zipなどです。CreativeWorkが複数のメディアタイプ表現を持つ場合、「encoding」を使用して、各MediaObjectと特定のfileFormat情報を組み合わせて示すことができます。登録されていない、またはニッチなファイル形式は、代わりに最も適切なURLで示すことができます。例えば、WebページやWikipediaのエントリーを定義します。 | |
| fileSize | アプリケーション / パッケージのサイズ (例: 18MB)。単位 (MB、KBなど) がない場合は、KBとみなします。 | |
| financialAidEligible | プログラムの授業料または手数料の支払いに学生が利用できる財政援助の種類またはプログラム。 | |
| firstAppearance | Claim がある CreativeWork での最初の既知の出現を示します。 | |
| firstPerformance | 作品が初演された日時と場所。 | |
| flightDistance | フライトの距離。 | |
| flightNumber | 航空会社IATAコードを含むフライトの一意な識別子です。例えば、IATAコードが'UA'のユナイテッド航空110便を記述する場合、flightNumberは'UA110'となります。 | |
| floorLevel | 多階建ての建物におけるAccommodationの階数。カウント システムは国際的に異なるため、可能な限り現地のシステムを使用すべきです。 | |
| floorLimit | フロア制限とは、クレジットカード取引が承認されなければならない金額の上限です。 | |
| floorSize | 宿泊施設の広さ(例:平方メートルまたは平方フィート)。 一般的な単位コード:平方メートルはMTK、平方フィートはFTK、平方ヤードはYDKです。 | |
| followee | オブジェクトのサブプロパティ。フォローされている人物または組織。 | |
| follows | 最も一般的な一方向の社会的関係。 | |
| followup | 処置後の典型的な、または推奨される経過観察。 | |
| foodEstablishment | locationのサブプロパティ。アクションが発生した特定の飲食施設。 | |
| foodEvent | locationのサブプロパティ。アクションが発生した特定のフードイベント。 | |
| foodWarning | この薬を服用中に、特定の食品の摂取に関連するあらゆる予防措置、指導、禁忌など。 | |
| founder | この組織を設立した人。 | |
| founders | この組織を設立した人。 | |
| foundingDate | この組織が設立された日付。 | |
| foundingLocation | 組織が設立された場所。 | |
| free | 無料でアクセス可能なアイテム、イベント、または場所であることを示すフラグ。 | |
| freeShippingThreshold | 送料が無料になる金額(またはそれ以上)。これは、このShippingRateSettingsに一致するshippingSettingsLinkを持つOfferShippingDetails経由で使用することを意図しています。 | |
| frequency | 服用頻度(例:「毎日」)。 | |
| fromLocation | locationのサブプロパティ。アクション前のオブジェクトまたはエージェントの元のlocation。 | |
| fuelCapacity | 燃料タンクの容量、または電気自動車の場合はバッテリーの容量。 複数の貯蔵コンポーネントがある場合は、同じ種類の貯蔵の合計を示す必要があります。 一般的な単位コード:リットル用LTR、米国ガロン用GLL、英国/帝国ガロン用GLI、電気自動車用アンペア時間AMH。 |
|
| fuelConsumption | 特定の距離または時間期間を、特定の車両で移動するために消費される燃料の量(例:100kmあたりリットル)。
|
|
| fuelEfficiency | 燃料の使用量あたりの走行距離。最も一般的なのは、1ガロンあたりのマイル数 (mpg) または 1リットルあたりのキロメートル数 (km/L) です。
|
|
| fuelType | 車両のエンジンまたはエンジンに適した燃料の種類。車両にエンジンが1つしかない場合、このプロパティは車両に直接アタッチできます。 | |
| functionalClass | 関節が許容する可動域。 | |
| fundedItem | Grantを通じて資金提供またはスポンサーされた項目を示します。 | |
| funder | 何らかの金銭的な貢献を通じて何かを支援(支援)する個人または組織。 | |
| game | このサーバーでプレイされるビデオゲーム。 | |
| gameItem | アイテムは、ゲーム世界内のオブジェクトであり、プレイヤーまたは、時折、ノンプレイヤーキャラクターによって収集可能です。 | |
| gameLocation | ゲーム(またはゲームの一部)の現実または架空の場所。 | |
| gamePlatform | ビデオゲームをプレイするために使用された電子システム。 | |
| gameServer | ゲームをプレイできるサーバー。 | |
| gameTip | ヒント、戦術などへのリンク {Links to tips, tactics, etc.} | |
| gender | 何かの性別。典型的にはPersonですが、架空のキャラクター、動物なども含まれます。https://schema.org/Male および https://schema.org/Female を使用できますが、バイナリージェンダーを認識しない人々に対しては、テキスト文字列も許容されます。gender プロパティは、スポーツチームの性別など、拡張された意味でも使用できます。個人の性別と同様に、すべての可能性を列挙しようとはしません。混合性別のSportsTeamは、テキスト値 "Mixed" で示すことができます。 | |
| genre | クリエイティブ作品のジャンル、放送チャンネル、またはグループ。 | |
| geo | その場所のジオ座標。 | |
| geoContains | 2つのジオメトリ(またはそれらが表す場所)間の関係を表し、包含するジオメトリと包含されるジオメトリを結びつけます。「a が b を含むのは、b の点が a の外部に存在せず、かつ b の内部の少なくとも1つの点が a の内部に存在する場合である」と定義されます。DE-9IMで定義されています。 | |
| geoCoveredBy | 2つのジオメトリ(またはそれらが表す場所)間の関係を表し、それを覆う別のジオメトリに関連付けます。DE-9IMで定義されています。 | |
| geoCovers | 2つのジオメトリ(またはそれらが表す場所)間の関係を表します。被覆ジオメトリと被覆されるジオメトリを結びつけます。「bのすべての点は、a(内部または境界)の点です」。DE-9IMで定義されています。 | |
| geoCrosses | 2つのジオメトリ(またはそれらが表す場所)間の関係を表します。あるジオメトリが別のジオメトリと交差する場合に適用されます。「a crosses b: それらは一部の内部点が共通しているが、すべてではない。そして、交差の次元は、少なくともどちらか一方の次元よりも小さい」。DE-9IMで定義されています。 | |
| geoDisjoint | 2つのジオメトリ(またはそれらが表す場所)が位相的に分離されている空間関係を表します。それらは共通点を持たず、切断されたジオメトリの集合を形成します。」(DE-9IMで定義される対称的な関係) | |
| geoEquals | 2つのジオメトリ(またはそれらが表す場所)が、DE-9IMで定義されるように、位相的に等しい空間関係を表します。「2つのジオメトリが位相的に等しいとは、それらの内部が交差しており、一方のジオメトリの内部または境界の一部が他方の外部と交差しないこと」を意味します(対称的な関係)。 | |
| geoIntersects | 2つのジオメトリ(またはそれらが表す場所)が少なくとも1つの共通点を持つ空間関係を表します。DE-9IMで定義されています。 | |
| geoMidpoint | GeoShape(例:GeoCircle)の中心のGeoCoordinatesを示します。 | |
| geoOverlaps | 2つのジオメトリ(またはそれらが表す場所)間の関係を表します。あるジオメトリが、地理的に重なる別のジオメトリ、つまり一部の点のみを共有していることを示します。DE-9IMで定義されています。 | |
| geoRadius | GeoCircleの概算半径を示します(距離表記がない限りメートル)。 | |
| geoTouches | 2つのジオメトリ(またはそれらが表す場所)が触れ合っている空間関係を表します。それらは少なくとも1つの境界点を共有しますが、内部点は共有しません。 (DE-9IMで定義される対称的な関係) | |
| geoWithin | 2つのジオメトリ(またはそれらが表す場所)間の関係を表します。あるジオメトリが別のジオメトリに含まれる、つまりその内部にあることを示します。DE-9IMで定義されています。 | |
| geographicArea | オーディエンスに関連付けられた地理的エリア。 | |
| gettingTestedInfo | MedicalCondition の検査を受ける方法に関する情報。例えば、パンデミックの状況下における検査について。 | |
| givenName | 名前. 米国では、Personの最初の名前。 | |
| globalLocationNumber | それぞれの組織、人物、または場所のグローバル・ロケーション・ナンバー(GLN、国際ロケーションナンバーまたはILNとも呼ばれる)です。GLNは、関係者と物理的な場所を識別するために使用される13桁の番号です。 | |
| governmentBenefitsInfo | governmentBenefitsInfo は、SpecialAnnouncement に関連する政府給付金に関する情報を提供します。 | |
| gracePeriod | 債務不履行(不払い)とみなされる前に、借入人がその義務を履行しなければならない期日後の期間。 | |
| grantee | この許可を与えられた人物、組織、連絡先、または対象者。 | |
| greater | この定性値に対する順序関係は、主語が客体よりも大きいことを示します。 | |
| greaterOrEqual | この定性値に対する順序関係は、主語が客体以上であることを示します。 | |
| gtin | グローバル・トレード・アイテム・ナンバー(GTIN)。GTINは、製品やサービスを含む取引品目を、数値識別コードを使用して識別します。gtinプロパティは、以前のgtin8、gtin12、gtin13、およびgtin14プロパティを一般化したものです。GS1 デジタルリンク仕様は、GTINをURLとして表現します。正しいgtin値は、有効なGTINである必要があります。つまり、8桁、12桁、13桁、または14桁のすべて数値の文字列であるか、そのような文字列に基づく「GS1デジタルリンク」URLである必要があります。数値コンポーネントは、有効なGS1チェックディジットを持ち、有効なGTINの他のルールを満たす必要があります。詳細については、GS1のGTIN概要およびWikipediaを参照してください。gtin値の左パディングは必須でも推奨もされません。 | |
| gtin12 | 製品のGTIN-12コード、またはこのオファーが参照する製品。GTIN-12は、U.P.C.企業プレフィックス、アイテムリファレンス、およびチェックディジットで構成される12桁のGS1識別キーであり、取引品目を識別するために使用されます。詳細はGS1 GTIN概要を参照してください。 | |
| gtin13 | 製品のGTIN-13コード、またはオファーが参照する製品。これは13桁のISBNコードおよびEAN UCC-13と同等です。以前の12桁のUPCコードは、先頭にゼロを追加するだけでGTIN-13コードに変換できます。詳細はGS1 GTIN Summaryを参照してください。 | |
| gtin14 | 製品のGTIN-14コード、またはオファーが参照する製品。詳細はGS1 GTIN Summaryをご覧ください。 | |
| gtin8 | 製品のGTIN-8コード、またはオファーが参照する製品。このコードはEAN/UCC-8または8桁のEANとしても知られています。詳細はGS1 GTIN Summaryを参照してください。 | |
| guideline | このエンティティに関連する医療ガイドライン。 | |
| guidelineDate | このガイドラインの推奨が行われた日付。 | |
| guidelineSubject | ガイドラインの対象となる医学的疾患、治療法など。 | |
| handlingTime | 注文受領から、商品が倉庫から発送されるか、あるいは配送方法が現地受け取りの場合には受け取り準備完了までの典型的な遅延時間。典型的なプロパティ:minValue, maxValue, unitCode (d は DAY を意味します)。これは慣例により、営業日を意味するものとみなされます(unitCode が使用されている場合、"d" としてコード化されます)。つまり、通常事業が行われる日のみをカウントします。 | |
| hasBroadcastChannel | 放送サービスの放送チャンネル。 | |
| hasCategoryCode | このコードセットに含まれるカテゴリコード {A Category code}. | |
| hasCourse | 教育 / 職業プログラムを構成する学習機会の一つであるコースまたはクラス。コースが必須であるかオプションであるかについての情報は示唆されず、コースがプログラムの全員に利用可能であるかどうかについての保証もありません。 | |
| hasCourseInstance | 特定の時間と場所、または特定のメディアや学習方法、あるいは特定の学生グループへのコースの提供。 | |
| hasCredential | 個人または組織に授与される資格。 | |
| hasDefinedTerm | この用語集に含まれる定義された用語「{A Defined Term}」。 | |
| hasDeliveryMethod | 配送または発送に使用される方法。 | |
| hasDigitalDocumentPermission | このドキュメントへのアクセスに関連する権限(例:電子ドキュメントの読み取りまたは書き込み権限)。公開ドキュメントの場合、audienceTypeが「public」であるAudienceを持つ受領者を指定してください。 | |
| hasDriveThroughService | 車で利用できるサービスを、ある施設(例:FoodEstablishment、CovidTestingFacility)が提供しているかどうかを示します。CovidTestingFacility の場合、このような施設は、感染の可能性がある他の利用者とのソーシャルディスタンスを保つのに役立つ可能性があります。 | |
| hasEnergyConsumptionDetails | 製品の国際エネルギー効率基準に基づいたエネルギー効率カテゴリ(「クラス」または「レーティング」とも呼ばれます)を定義します。 | |
| hasEnergyEfficiencyCategory | 国際的なエネルギー効率基準に従って、製品のエネルギー効率カテゴリ(値の範囲外の評価、またははい/いいえの認証のいずれか)を定義します。 | |
| hasHealthAspect | 特定の HealthTopicContent で具体的に扱われている側面を示します。例えば、コンテンツが概要であるか、治療、自己管理、治療法、またはそれらの副作用について述べているかを示します。 | |
| hasMap | その場所の地図へのURL。 | |
| hasMeasurement | 製品の測定値、例えばズボンの股下、自転車のホイールサイズ、またはネジのゲージなどです。通常は正確な測定値ですが、ベルトやスキービンディングなど、調整可能な製品の場合は測定値の範囲となることもあります。 | |
| hasMenu | 実際のメニューを構造化された表現、テキスト、またはメニューのURLのいずれか。 | |
| hasMenuItem | メニューまたはメニューセクションに含まれる食品または飲料項目。 | |
| hasMenuSection | メニューのサブグループ化(料理、コース、提供時間帯などによる)。 | |
| hasMerchantReturnPolicy | 適用される可能性のあるMerchantReturnPolicyを示します。 | |
| hasOccupation | その人の職業。過去の職務については、日付を表す場合はRoleを使用してください。 | |
| hasOfferCatalog | この組織、人物、またはサービスに対するオファーカタログのリストを示します。 | |
| hasPOS | 組織または個人によって運営されるポイント・オブ・セールス。 | |
| hasPart | このアイテムまたはクリエイティブワークの一部であるアイテムまたはクリエイティブワークを示します(ある意味で)。 | |
| hasVariant | このProductGroupのメンバーであるProduct(またはProductModel)を示します。 | |
| headline | 記事の見出し。 | |
| healthCondition | 患者、医学研究、またはその他の対象者の健康状態(s)を指定すること。 | |
| healthPlanCoinsuranceOption | 保険共渡りが免責金額の前か後か、など。TODO: これは閉集合ですか? | |
| healthPlanCoinsuranceRate | コインシュランス率が0.0から1.0の間の数値として表されるかどうか。 | |
| healthPlanCopay | 共払い金額は、{The copay amount} です。 | |
| healthPlanCopayOption | 免責金額の有無にかかわらず自己負担額が適用されるかどうかなど。TODO: これは閉集合ですか? | |
| healthPlanCostSharing | このネットワークまたは処方箋集におけるサービスに対する患者の費用は、[The]です。 | |
| healthPlanDrugOption | TODO. | |
| healthPlanDrugTier | この処方箋または保険プランで提供される薬剤のティア(s)。 | |
| healthPlanId | 14桁の、HIOSによって生成されたプランID番号です。(プランIDは、異なる市場間でも一意である必要があります。) | |
| healthPlanMarketingUrl | 特定の標準プランまたはプランバリエーションのプランパンフレットに直接アクセスできるURL。 | |
| healthPlanNetworkId | ネットワークの名前または一意のID。 (ネットワークは、異なる保険プラン間で再利用されることがよくあります。) | |
| healthPlanNetworkTier | このネットワークのティア(s)。 | |
| healthPlanPharmacyCategory | この費用負担に関連する薬局のカテゴリーまたは種類。 | |
| healthcareReportingData | 病院を説明するデータを示します。例えば、CDC CDCPMDRecordや何らかのDatasetなどです。 | |
| height | アイテムの高さ。 | |
| highPrice | 利用可能なすべてのオファーの最高価格。 使用ガイドライン:
|
|
| hiringOrganization | 求人を出している組織。 | |
| holdingArchive | ArchiveOrganization が保有、保管、または維持する ArchiveComponent。 | |
| homeLocation | 個人の居住地の連絡先。 | |
| homeTeam | スポーツイベントのホームチーム。 | |
| honorificPrefix | 人名の前に付く敬称(例:Dr./Mrs./Mr.) | |
| honorificSuffix | 人物の名前の後に続く敬称の接尾辞、例:M.D. /PhD/MSCSW。 | |
| hospitalAffiliation | 医師または診療所が提携している病院。 | |
| hostingOrganization | メンバーシップが作成された組織(航空会社、旅行者クラブなど)。 | |
| hoursAvailable | このサービスまたは連絡先が利用可能な時間帯。 | |
| howPerformed | 手順の実行方法。 | |
| httpMethod | HTTP EntryPoint へのリクエストに適した HTTP メソッドを指定する HTTP メソッド。値は HTTP で使用される大文字の文字列です。 | |
| iataCode | 航空会社または空港の IATA コード。 | |
| icaoCode | 空港のICAO識別子。 | |
| identifier | identifierプロパティは、ISBN、GTINコード、UUIDなど、あらゆる種類のThingの識別子を表します。Schema.orgは、これら多くの識別子をテキスト文字列またはURL(URI)リンクとして表現するための専用プロパティを提供します。詳細は背景資料を参照してください。 | |
| identifyingExam | この兆候を特定できる身体検査。 | |
| identifyingTest | この兆候を特定できる診断テスト。 | |
| illustrator | 本のイラストレーター。 | |
| image | アイテムの画像です。これはURLでも、詳細に記述されたImageObjectでも構いません。 | |
| imagingTechnique | 使用された画像技術。 | |
| inAlbum | この録音に属するアルバム。 | |
| inBroadcastLineup | チャンネルを提供している CableOrSatelliteService。 | |
| inCodeSet | このカテゴリコードを含む CategoryCodeSet。 | |
| inDefinedTermSet | この用語を含む DefinedTermSet。 | |
| inLanguage | コンテンツ、パフォーマンス、またはアクションで使用される言語。IETF BCP 47 標準の言語コードのいずれかを使用してください。availableLanguageも参照してください。 | |
| inPlaylist | この録音に属するプレイリスト。 | |
| inProductGroupWithID | productGroupIDのProductGroupは、この製品のisVariantOfであることを示します。 | |
| inStoreReturnsOffered | 店舗での返品は可能ですか? | |
| inSupportOf | 資格、立候補、学位、論文がサポートする出願。 | |
| incentiveCompensation | 職務におけるボーナスおよびコミッションの報酬に関する説明。 | |
| incentives | 職務におけるボーナスおよびコミッションの報酬に関する説明。 | |
| includedComposition | この作品に含まれる小規模な楽曲構成(例えば、交響曲の中の一楽章など)。 | |
| includedDataCatalog | このデータセットを含むデータカタログ(このプロパティは以前「catalog」でしたが、現在の推奨名は「includedInDataCatalog」です)。 | |
| includedInDataCatalog | このデータセットを含むデータカタログ。 | |
| includedInHealthInsurancePlan | この薬をカバーする保険プラン。 | |
| includedRiskFactor | 計算に含まれる、修正可能または修正不可能なリスク因子。例:年齢、合併症。 | |
| includesAttraction | 目的地にある観光スポット。 | |
| includesHealthPlanFormulary | このプランで対象となる書式帳票。 | |
| includesHealthPlanNetwork | このプランでカバーされるネットワーク。 | |
| includesObject | これは、OfferまたはProductCollectionに含まれる製品の正確な数量を示すノードまたはノードへのリンクです。 | |
| increasesRiskOf | この要因に影響を受ける状態、合併症など。 | |
| industry | 職位に関連する業界。 | |
| ineligibleRegion | ISO 3166-1 (ISO 3166-1 alpha-2) または ISO 3166-2 コード、場所、または、オファーまたは配送料金の仕様が有効でない地理的・政治的地域(複数可)の GeoShape。例えば、取引が許可されていない地域です。 eligibleRegion も参照してください。 |
|
| infectiousAgent | 特定の細菌など、実際の感染因子。 | |
| infectiousAgentClass | その病気を引き起こす感染性病原体(細菌、プリオンなど)のクラス。 | |
| ingredients | レシピで使用される単一の材料、例:砂糖、小麦粉、またはニンニク。 | |
| inker | 鉛筆画が完了した後、鉛筆画をインクでなぞる人。 | |
| insertion | 筋肉の付着部位、または筋肉が動かすもの。 | |
| installUrl | アイテムのURLと異なる場合、アプリがインストールされる可能性のあるURL。 | |
| instructor | CourseInstanceの指導または指導支援を担当する人。 | |
| instrument | 行為者がアクションを実行するのに役立ったオブジェクト。例:Johnはペンを使って本を書きました。 | |
| intensity | 運動における力の程度を測る定量的指標で、例えば1分あたりの心拍数など。運動の速度も含まれる場合があります。 | |
| interactingDrug | この薬の効果に影響を与えたり、患者にリスクをもたらしたりする可能性のある、別の薬。注:疾患との相互作用は通常、禁忌として記録されます。 | |
| interactionCount | このプロパティは非推奨であり、それに依存していたUserInteraction型も同様に非推奨です。 | |
| interactionService | インタラクションが発生した WebSite または SoftwareApplication。 | |
| interactionStatistic | Webサイトまたはソフトウェアアプリケーションを使用してCreativeWorkに対するインタラクションの数。InteractionCounterの最も具体的な子タイプを使用する必要があります。 | |
| interactionType | インタラクションの種類を表すアクション。高評価、+1などにはLikeActionを使用します。低評価にはDislikeActionを使用します。それ以外の場合は、最も具体的なアクションを使用してください。 | |
| interactivityType | 学習リソースがサポートする主な学習モード。有効な値は 'active', 'expositive', または 'mixed' です。 | |
| interestRate | 金融商品に適用される、引き落とされるまたは支払われる利率。注:これは計算された annualPercentageRate とは異なります。 | |
| inventoryLevel | アイテムまたはアイテムの現在の概算在庫レベル。 | |
| inverseOf | あるプロパティとその逆の関係を持つプロパティを結びつけます。逆の関係を持つプロパティは、同じアイテムのペアを互いに関連付けますが、方向が逆になります。例えば、'alumni' と 'alumniOf' プロパティは互いに inverseOf です。明示的な逆を持たないプロパティもあります。これらの状況では、逆プロパティに対するRDFaおよびJSON-LD構文を使用できます。 | |
| isAcceptingNewPatients | プロバイダーが新規患者を受け入れているかどうか。 | |
| isAccessibleForFree | 無料でアクセス可能なアイテム、イベント、または場所であることを示すフラグ。 | |
| isAccessoryOrSparePartFor | この製品の付属品またはスペアパーツとなる別の製品(または複数の製品)へのポインタ。 | |
| isAvailableGenerically | 薬がジェネリック医薬品として入手可能かどうか(名称に関わらず)。 | |
| isBasedOn | この作品の由来、または修正または翻案の元となるリソース。 | |
| isBasedOnUrl | このリソースの作成に使用されたリソース。この用語は、複数のソースに対して繰り返すことができます。例えば、http://example.com/great-multiplication-intro.html。 | |
| isConsumableFor | この製品が消耗品となる別の製品(または複数の製品)へのポインタ。 | |
| isFamilyFriendly | このコンテンツがファミリーフレンドリーかどうかを示します。 | |
| isGift | 購入者以外の方への贈り物として、その申し出は受け入れられましたか? | |
| isLiveBroadcast | 放送がライブイベントであるかどうか。 | |
| isPartOf | このアイテム、またはCreativeWorkが、何らかの形で、どのアイテムまたはCreativeWorkの一部であるかを示します。 | |
| isPlanForApartment | この間取り図が示す宿泊施設の一部を示します。 | |
| isProprietary | このアイテムの名前が、固有名称/ブランド名(ジェネリック名に対して)である場合はTrue。 | |
| isRelatedTo | 別の、何らかの形で関連する製品(または複数の製品)へのポインタ。 | |
| isResizable | 3DModelがサイズ変更を許可するかどうか。例えば、間取りアプリケーションでは、3DModel要素が現実を反映するようにサイズ変更できない場合があります。 | |
| isSimilarTo | 別の、機能的に類似した製品(または複数の製品)へのポインタ。 | |
| isUnlabelledFallback | This can be marked 'true' to indicate that some published DeliveryTimeSettings or ShippingRateSettings are intended to apply to all OfferShippingDetails published by the same merchant, when referenced by a shippingSettingsLink in those settings. It is not meaningful to use a 'true' value for this property alongside a transitTimeLabel (for DeliveryTimeSettings) or shippingLabel (for ShippingRateSettings), since this property is for use with unlabelled settings. [TRANSLATION ERROR - ORIGINAL KEPT] | |
| isVariantOf | これは、この製品がどの種類の製品のバリアントであるかを示します。ProductModel の場合、これは、この製品がバリアントであるベース製品へのポインタ(ProductModel から)です。バリアントは、ローカルで定義されていない限り、ベースモデルのすべての製品機能を継承すると推測しても安全です。これは推移的ではありません。ProductGroup の場合、グループの説明はテンプレートとしても機能し、明示的に定義された特定の次元のみが異なる製品のセットを表します(したがって、バリアントのセットと、それらのバリアントを区別する値を定義します)。ProductGroup と組み合わせて使用する場合、このプロパティはグループに含まれる任意の Product に適用できます。 | |
| isbn | 本のISBN。 | |
| isicV4 | 国際産業分類(ISIC)改訂版4における、特定の組織、事業主、または場所のコード。 | |
| isrcCode | 録音の国際標準録音コード(International Standard Recording Code for the recording)。 | |
| issn | この連続出版物を識別する国際標準雑誌番号(ISSN)。このプロパティを繰り返して、この連続出版物の異なる形式、またはリンキングISSN(ISSN-L)を識別できます。 | |
| issueNumber | 発行の問題を特定します。例えば、"iii" または "2" などです。 | |
| issuedBy | チケットまたは許可証を発行する組織。 | |
| issuedThrough | 許可が与えられたサービスは、{service}です。 | |
| iswcCode | 楽曲の国際標準音楽作品コード(ISWC)。 | |
| item | リストまたはデータフィードのエントリで表されるエンティティ(例:'artists'のリストにおける'artist')。 | |
| itemCondition | OfferItemConditionからの定義済みの値、または製品またはサービスの条件、またはオファーに含まれる製品またはサービスのテキストによる説明。 | |
| itemListElement | itemListElementの値には、単純な文字列(例: "Peter", "Paul", "Mary")、既存のエンティティ、またはListItem. を使用できます。 リストの要素が単純な文字列である場合は、テキスト値が最適です。既存のエンティティは、データの既存のものを単純な順不同リストにするのに最適です。ListItemは、リスト内の要素に関する追加のコンテキストを提供したい場合や、同じ項目が異なるリストの異なる場所に存在する可能性がある場合に、順序付きリストで使用されます。 注: マークアップ内の要素の順序は、要素の順序を示すのに十分ではありません。そのような場合は、'position'プロパティを持つListItemを使用してください。 |
|
| itemListOrder | 並び替えの種類(例:Ascending、Descending、Unordered)。 | |
| itemLocation | アイテムの現在地。 | |
| itemOffered | 提供(または要求)される品目。そのオファーまたは要求の取引的性質は、businessFunction(例:販売、リースなど)を使用して文書化されます。この定義ではいくつかの一般的な期待されるタイプが明示的にリストされていますが、他のタイプも使用できます。ProductまたはProductのサブタイプのような2番目のタイプを使用すると、オファーの性質を明確にすることができます。 | |
| itemReviewed | レビュー/評価対象のアイテム。 | |
| itemShipped | 発送品目。 | |
| itinerary | 旅行を構成する目的地( Place )。 目的地の順序が重要な旅行の場合は、その順序を指定するために ItemList を使用してください (例を参照)。 | |
| jobBenefits | 職務に関連する特典の説明。 | |
| jobImmediateStart | 即日開始可能なポジションがあるかどうかを示す指標。 | |
| jobLocation | 職位に関連付けられた(通常は単一の)地理的な場所。 | |
| jobLocationType | ジョブの勤務地に関する説明(例:テレワークの場合はTELECOMMUTE)。 | |
| jobStartDate | この職種の採用者が就業を開始することが予想される日付。具体的な将来の日付を選択するか、またはjobImmediateStartプロパティを使用して、できるだけ早く人員を補充する必要があることを示してください。 | |
| jobTitle | 担当者の職位(例:Financial Manager)。 | |
| jurisdiction | 法域を示します。例えば、ある法律の管轄区域や、政府サービスが拠点を置く場所などです。 | |
| keywords | このコンテンツを説明するために使用されるキーワードまたはタグ。キーワードリスト内の複数のエントリは通常、カンマで区切られます。 | |
| knownVehicleDamages | 既知の損傷(修理済みおよび未修理の両方)に関するテキストによる説明。 | |
| knows | 最も一般的な双方向のソーシャル/ワーク関係。 | |
| knowsAbout | Personや、よりまれにはOrganizationについて、ある程度知識があるトピックを示すものであり、専門知識の可能性を示唆するものの、それを意味するものではありません。ここではスキルレベルを区別せず、教育コンテンツ、イベント、目的、またはJobPostingの説明に関連付けません。 | |
| knowsLanguage | Person、またはまれにOrganizationの既知の言語を示す。ここでは技能レベルや読み書き、会話、手話などの区別は行わない。IETF BCP 47標準の言語コードを使用すること。 | |
| labelDetails | 薬のラベル詳細へのリンク:{Link to the drug's label details}. | |
| landlord | 参加者のサブプロパティ。不動産の所有者。 | |
| language | instrument のサブプロパティ。このアクションで使用される言語。 | |
| lastReviewed | このウェブページのコンテンツが正確性および/または完全性について最後にレビューされた日付。 | |
| latitude | 場所の緯度。例えば 37.42242 (WGS 84)。 |
|
| layoutImage | 床の間取りレイアウトを示す概略図。 | |
| learningResourceType | 学習リソースを特徴づける主な種類またはタイプ。例えば、'presentation'、'handout'。 | |
| leaseLength | 一部のAccommodationの賃貸期間、特定のOfferに固有である場合もあれば、物件自体に内在している場合もあります。 | |
| legalName | 組織の正式名称、例えば登録された会社名。 | |
| legalStatus | 薬剤またはサプリメントの法的地位、適用される規制薬物スケジュールを含む。 | |
| legislationApplies | この法律(または法律の一部)が、別の法的な文脈において別の法律を何らかの形で移転することを示します。これは情報リンクであり、法的価値はありません。法的拘束力のある移転リンクについては、legislationTransposes プロパティを使用してください。例えば、欧州連合加盟国の統合法は、その中に実装された欧州指令の統合版を「適用」します。 | |
| legislationChanges | この法律が変更する別の法律。これは、修正、置換、修正、廃止、またはその他の種類の変更という概念を包含します。これは、直接的な変更(テキストまたは非テキストの修正)または派生的または間接的な変更である可能性があります。この属性は、変更の結果を示すテキストの統合版の存在ではなく、2つの法律間の変更関係の存在を表現するために使用されます。統合関係については、legislationConsolidates属性を使用してください。 | |
| legislationConsolidates | この統合法が考慮した他の法律を示します(通常、法律を修正する編集プロセスによって作成されるもの)。このプロパティは、元のバージョンまたは以前の統合バージョン、および変更を加える法律の両方を参照するために複数回使用する必要があります。 | |
| legislationDate | 法律の採択または署名の日付。これは、テキストが法律として公式に認められる日付であり、たとえまだ公表または施行されていなくても同様です。 | |
| legislationDateVersion | 法律の説明が有効な時点(例:2016-04-07 (= dateVersion) の法律を参照すると、"National Insurance Contributions Act 2015" の 2015-04-12 の統合版が得られる) | |
| legislationIdentifier | 法律を識別するための識別子です。これは、EUレベルのCELEXやフランスのNORのような文字列ベースの識別子、またはELI(欧州立法識別子)やURN-LexのようなウェブベースのURL/URI識別子のいずれかです。 | |
| legislationJurisdiction | 立法が発令される管轄区域。 | |
| legislationLegalForce | 当該法案が、現在施行中か、施行されていないか、または部分的に施行中か。 | |
| legislationLegalValue | この法律ファイルにおける法的価値。同じ法律が、異なる法的価値を持つ複数のファイルで記述されることがあります。通常、デジタル署名されたPDFは、同じ法律のHTMLファイルよりも「より強い」法的価値を持ちます。 | |
| legislationPassedBy | 法律を最初に可決または制定した者または組織:通常は、一次法の場合は議会、二次法の場合は政府です。これは、法律の物理的な作者ではなく、「法的作者」を示します。 | |
| legislationResponsible | 法律に対して何らかの責任を持つ個人または組織。通常は、法律の策定を担当した、または法律が公布された後にその法律に関する質問を受け付ける省庁などです。 | |
| legislationTransposes | この法律(または法律の一部)が、適切な実施措置を講じることにより、別の法律によって設定された目的を達成することを示します。通常、欧州連合加盟国または地域のいくつかの法律は、欧州指令を国内法に取り込みます。これは、2つの法律間の法的拘束力のある関連性を示します。 | |
| legislationType | 法律の種類。値の例としては、"law", "act", "directive", "decree", "regulation", "statutory instrument", "loi organique", "règlement grand-ducal" など、国によって異なります。 | |
| leiCode | ISO 17442で定義される法的エンティティを一意に識別する組織識別子。 | |
| lender | 参加者のサブプロパティ。借りられているオブジェクトを貸し出す人物。 | |
| lesser | この定性値に対する順序関係は、主語が客体よりも小さいことを示します。 | |
| lesserOrEqual | この定性値に対する順序関係は、主語が客体以下または客体と等しいことを示します。 | |
| letterer | 作品に文字、吹き出し、効果音などを加える人。 | |
| license | このコンテンツに適用されるライセンス文書。通常はURLで示されます。 | |
| line | 線は、2つ以上の点からなる点と点の間の経路です。線は、スペースで区切られた2つ以上の点オブジェクトのシリーズとして表現されます。 | |
| linkRelationship | Web リンクの関係の種類を示します。 | |
| liveBlogUpdate | LiveBlogの更新。 | |
| loanMortgageMandateAmount | 後日、正式な住宅ローンに変換可能な住宅ローン委任額。 | |
| loanPaymentAmount | 一括払い金額。 | |
| loanPaymentFrequency | 支払い頻度、すなわち支払い間の月数。これは頻度として定義され、すなわち一定期間の逆数です。 | |
| loanRepaymentForm | 以前借りたお金を貸し手に返す形態。返済は通常、各支払いごとに元本と利息を含む定期的な支払いという形で行われます。 | |
| loanTerm | 融資または信用契約の期間。 | |
| loanType | ローンまたはクレジットの種類。 | |
| location | 例えば、イベントが開催される場所、組織の所在地、またはアクションが発生する場所。 | |
| locationCreated | CreativeWorkが作成された場所。CreativeWorkで描かれている場所とは異なる場合があります。 | |
| lodgingUnitDescription | 宿泊ユニットの完全な説明。 | |
| lodgingUnitType | ユニットタイプの説明(スイートかルームか、ベッドのサイズなどを含む)。 | |
| logo | 関連するロゴ。 | |
| longitude | 場所の経度。例えば -122.08585 (WGS 84)。 |
|
| loser | 参加者のサブプロパティ。アクションの敗者。 | |
| lowPrice | 利用可能なすべてのオファーの最低価格。 使用ガイドライン:
|
|
| lyricist | 言葉を書いた人。 | |
| lyrics | 歌の歌詞。 | |
| mainContentOfPage | このウェブページ要素が、ページ全体の主要な主題であるかどうかを示します。 | |
| mainEntity | 何らかのページまたはクリエイティブワークで記述されている主要なエンティティを示します。 | |
| mainEntityOfPage | このものが記述している主要なエンティティであるページ(またはその他のCreativeWork)を示します。詳細は背景注記を参照してください。 | |
| maintainer | Dataset、ソフトウェアパッケージ(SoftwareApplication)、またはその他のProjectのメンテナ。メンテナは、何らかの(通常は複雑な)成果物への貢献や公開を管理するPersonまたはOrganizationです。「upstream」ソースに基づいてソフトウェアやデータの配布が行われることはよくあります。maintainerが、特定のDatasetのバージョンやパッケージングなど、何かの特定のバージョンに適用される場合、upstreamソースが異なるメンテナを持つ可能性は常にあります。異なるメンテナンスの役割を明確にするために、そのようなデータセット間の関係を示すためにisBasedOnプロパティを使用できます。同様に、ソフトウェアの場合、パッケージには、Ubuntuなどのソフトウェア配布への統合に取り組む専用のメンテナと、基盤となる作業のupstreamメンテナがいる場合があります。 | |
| makesOffer | 組織または個人が提供する製品またはサービスへのポインタ。 | |
| manufacturer | 製品の製造元。 | |
| map | その場所の地図へのURL。 | |
| mapType | MapCategoryType列挙型からのマップの種類を示します。 | |
| maps | その場所の地図へのURL。 | |
| marginOfError | Observation の marginOfError。 | |
| masthead | NewsMediaOrganization の場合、マストヘッドページまたは主要な編集幹部を掲載したページへのリンク。 | |
| material | 何かから作られる素材、例えば、レザー、ウール、コットン、ペーパー。 | |
| materialExtent | 記述されている材料の量、またはそれらが占める物理的な空間の表現。 | |
| mathExpression | 特定の変数を解いたり、簡略化したり、変換したりできる数学的な表現(例:'x^2-3x=0')。これは、LaTeX、Ascii-Math、またはキーボードで記述する数学のような、さまざまな形式をとることができます。 | |
| maxPrice | 価格が範囲の場合の最高価格。 | |
| maxValue | ある特性または属性の上限値。 | |
| maximumAttendeeCapacity | イベントまたは会場に参加できる個人の総数。 | |
| maximumEnrollment | プログラムに登録できる学生の最大人数。 | |
| maximumIntake | 特定の推奨機関によって定義された、特定の集団に対するこのサプリメントの推奨摂取量。 | |
| maximumPhysicalAttendeeCapacity | Event の eventAttendanceMode が OfflineEventAttendanceMode である場合の最大参加者数(または、MixedEventAttendanceMode の場合はオフライン部分の最大参加者数)。 | |
| maximumVirtualAttendeeCapacity | Event の eventAttendanceMode が OnlineEventAttendanceMode である場合の最大参加者数(または、MixedEventAttendanceMode の場合はオンライン部分の参加者数)。 | |
| mealService | 提供または購入可能な食事の説明。 | |
| measuredProperty | Observationの測定プロパティ。schema.orgプロパティ、W3C RDF Data Cubeなどの他のRDF互換システムからのプロパティ、またはGS1ののようなschema.org拡張です。 | |
| measuredValue | Observation の measuredValue。 | |
| measurementTechnique | Dataset(またはDataDownload、DataCatalog)で使用される技術または技術で、対応する変数(variableMeasuredを使用して記述)を測定するために使用された方法に対応します。これは、科学的および学術的なデータセットの公開を目的としていますが、より広範な適用性を持つ可能性があります。測定の完全な表現としてではなく、データセットの発見のための高レベルの概要として意図されています。 たとえば、variableMeasuredが「分子濃度」の場合、measurementTechniqueは「質量分析」、「NMR分光法」、「比色法」、「免疫蛍光」などになり得ます。 variableMeasuredが「うつ病評価」の場合、measurementTechniqueは「Zung Scale」、「HAM-D」、「Beck Depression Inventory」などになり得ます。 あるデータオブジェクトに対して複数のvariableMeasuredプロパティが記録されている場合は、各variableMeasuredに対してPropertyValueを使用し、対応するmeasurementTechniqueを添付してください。 |
|
| mechanismOfAction | この薬またはサプリメントがその薬理効果を生み出す特定の生化学的相互作用。 | |
| mediaAuthenticityCategory | メディアオブジェクトのメディア操作評価列挙型の分類を示します(公開または共有された状況において)。 | |
| median | 中央値。 | |
| medicalAudience | ページの医療関係者向け対象者。 | |
| medicalSpecialty | プロバイダーの専門分野。 | |
| medicineSystem | このMedicalEntityを含む医学体系。例えば、「evidence-based」、「homeopathic」、「chiropractic」など。 | |
| meetsEmissionStandard | 車両がそれぞれの排出ガス基準を満たしていることを示します。 | |
| member | 組織またはプログラムメンバーシップのメンバーです。組織は組織のメンバーになることができ、プログラムメンバーシップは通常、個人向けです。 | |
| memberOf | この人物または組織が所属する組織(またはプログラムメンバーシップ)。 | |
| members | この組織のメンバー。 | |
| membershipNumber | メンバーシップの一意な識別子。 | |
| membershipPointsEarned | メンバーが獲得した会員ポイント数。必要に応じて、ポイントの発行単位を表現するためにunitTextを使用できます。(例:スター、マイルなど) | |
| memoryRequirements | 最小限のメモリ要件。 | |
| mentions | CreativeWorkが、概念への参照を含むが、必ずしもその概念についてではないことを示します。 | |
| menu | 実際のメニューを構造化された表現、テキスト、またはメニューのURLのいずれか。 | |
| menuAddOn | このメニュー項目に追加できる、サラダの付け合わせやフライドポテトのサイドオーダーなどの追加メニュー項目。さらに、このメニュー項目に対して許可されている追加メニュー項目を含むメニューセクションであることもあります。 | |
| merchant | 「merchant」は「seller」の古い用語です。 | |
| merchantReturnDays | merchantReturnDaysプロパティは、関連するマーチャントの返品ポリシーが適用される日数(購入日から)を示します。 | |
| merchantReturnLink | 製品返品のためのURLによるWebページまたはサービスを示します。 | |
| messageAttachment | メッセージに添付されたCreativeWork。 | |
| mileageFromOdometer | その特定の車両が初期生産以来走行した総距離で、オドメーターから読み取ったもの。 一般的な単位コード:KMT(キロメートル)、SMI(法定マイル) |
|
| minPrice | 価格が範囲の場合の最低価格。 | |
| minValue | ある特性または属性のより低い値。 | |
| minimumPaymentDue | 現時点で必要な最低支払い額。 | |
| missionCoveragePrioritiesPolicy | NewsMediaOrganizationにおける報道優先事項に関する声明、これには公共の議題や問題に対する立場が含まれます。 | |
| model | 製品のモデル。ProductModelのURLまたはモデル識別子のテキスト表現とともに使用します。ProductModelのURLは外部ソースからでも構いません。gtin8/gtin13/gtin14およびmpnプロパティを通じて、強力な製品識別子を追加で提供することを推奨します。 | |
| modelDate | 車両モデルの発売日(同じメーカーとモデルのバージョンを区別するためによく使用されます)。 | |
| modifiedTime | 予約が変更された日時。 | |
| monthlyMinimumRepaymentAmount | 最低支払額は、毎月クレジットカードの請求書で支払う必要のある最低金額です。 | |
| monthsOfExperience | ポジションに必要な最低経験年数を表します。 | |
| mpn | 製品のメーカー部品番号(MPN)、またはオファーが参照する製品。 | |
| multipleValues | プロパティに複数の値が許可されるかどうか。デフォルトはfalseです。 | |
| muscleAction | 筋肉が生み出す動き。 | |
| musicArrangement | 作曲から派生した編曲。 | |
| musicBy | サウンドトラックの作曲者。 | |
| musicCompositionForm | 楽曲の種類(例えば、序曲、ソナタ、交響曲など)。 | |
| musicGroupMember | 音楽グループの一員—例えば、John、Paul、George、またはRingo。 | |
| musicReleaseFormat | このリリース形式(録音媒体の種類、例:コンパクトディスク、デジタルメディア、LPなど)。 | |
| musicalKey | この楽曲で使用されているキー、モード、またはスケール。 | |
| naics | 特定の組織または事業者の北米産業分類システム(NAICS)コード。 | |
| name | アイテムの名前。 | |
| namedPosition | 組織の一員として、個人または組織が担う役割、実行する役割、または埋める地位。例えば、SportsTeamの選手は「Quarterback」というポジションでプレイすることがあります。 | |
| nationality | 人の国籍。 | |
| naturalProgression | 治療されず、自然に進行した場合の病状の予想される経過。 | |
| nerve | 筋肉に関連する基底の神経支配。 | |
| nerveMotor | 筋肉制御に関わる神経経路の伸長。 | |
| netWorth | 資産から負債を差し引いて計算された、その人物の総金融価値。 | |
| newsUpdatesAndGuidelines | ニュース速報とガイドラインを含むページを示します。これは、サイト上のSpecialAnnouncementマークアップを含むメインページであることが多いですが、必須ではありません。 | |
| nextItem | 現在のListItemの後に続くListItemへのリンク。 | |
| noBylinesPolicy | NewsMediaOrganizationまたはニュース関連のOrganization向けに、記事の著者名がバイラインに記載されない理由を説明する声明。 | |
| nonEqual | この定性値に対する順序関係は、主語がオブジェクトと等しくないことを示します。 | |
| nonProprietaryName | この薬またはサプリメントの一般名。 | |
| nonprofitStatus | 非営利ステータスは、非営利組織の主要な事業所における法的ステータスを示します。 | |
| normalRange | 典型的な患者に適用される場合、許容可能な値の範囲。 | |
| nsn | Product の NATO 在庫番号 (nsn) を示します。 | |
| numAdults | ユニットに滞在する成人の人数。 | |
| numChildren | ユニットに滞在する子供の数。 | |
| numConstraints | 特定のStatisticalPopulationに対して定義されている制約の数(populationTypeはカウントしません)を示します。これにより、アプリケーションは、StatisticalPopulationの十分に完全な記述にアクセスできるかどうかを理解するのに役立ちます。 | |
| numTracks | このアルバムまたはプレイリストのトラック数。 | |
| numberOfAccommodationUnits | ApartmentComplex内の宿泊ユニットの総数(利用可能および利用不可を含む)、または特定のFloorPlanの宿泊ユニット数(特定のApartmentComplex内)。numberOfAvailableAccommodationUnitsも参照してください。 | |
| numberOfAirbags | 車両内のエアバッグの数または種類。 | |
| numberOfAvailableAccommodationUnits | ApartmentComplex内の利用可能な宿泊ユニット数、または特定のFloorPlan(その特定のApartmentComplex内)の宿泊ユニット数を示します。numberOfAccommodationUnitsも参照してください。 | |
| numberOfAxles | 車軸の数。 一般的な単位コード: C62 |
|
| numberOfBathroomsTotal | The total integer number of bathrooms in a some Accommodation, following real estate conventions as documented in RESO: "The simple sum of the number of bathrooms. For example for a property with two Full Bathrooms and one Half Bathroom, the Bathrooms Total Integer will be 3.". See also numberOfRooms. [TRANSLATION ERROR - ORIGINAL KEPT] | |
| numberOfBedrooms | ある Accommodation、ApartmentComplex、または FloorPlan におけるベッドルームの総整数数。 | |
| numberOfBeds | ホテルルーム、スイート、ハウス、またはアパートメントで利用可能な、指定されたベッドタイプの数量。 | |
| numberOfCredits | コースによって付与される、または教育職業プログラムを修了するために必要な単位数またはクレジット数。 | |
| numberOfDoors | ドアの数。 標準ユニットコード:C62 |
|
| numberOfEmployees | 組織における従業員数、例えばビジネス。 | |
| numberOfEpisodes | このシーズンまたはシリーズのエピソード数。 | |
| numberOfForwardGears | 車両のトランスミッションシステムの利用可能な前進ギアの総数。 一般的な単位コード:C62 |
|
| numberOfFullBathrooms | フルバスルームの数 - Accommodation内のフルバスルームと3/4バスルームの合計数。これはRESOのBathroomsFullフィールドに対応します。 | |
| numberOfItems | ItemList内のアイテム数。ただし、一部の説明ではリスト内のすべてのアイテムを完全に記述していない場合があります(例:複数ページへのページネーション)。そのような場合、numberOfItemsはリスト全体に対するものになります。 | |
| numberOfLoanPayments | ローンの返済のために、当初契約時に義務付けられている支払い回数。月払いのローンでは、契約上の最初の支払い日から満期日までの月数です。 | |
| numberOfPages | 本のページ数。 | |
| numberOfPartialBathrooms | 部分的なバスルームの数 - Accommodationにある、半分のバスルームと¼のバスルームの合計数。これは、RESOのBathroomsPartialフィールドに対応します。 | |
| numberOfPlayers | このゲームは、何人でプレイできますか(最小人数、最大人数、または範囲)。 | |
| numberOfPreviousOwners | 車両の所有者数(現在所有者を含む)。 一般的な単位コード:C62 |
|
| numberOfRooms | 宿泊施設または宿泊事業における部屋数(バスルームとクローゼットを除く)。 典型的なユニットコード:部屋の場合はROM、ユニットがない場合はC62。部屋の種類は、QuantitativeValueのunitTextプロパティに記述できます。 | |
| numberOfSeasons | このシリーズのシーズンの数。 | |
| numberedPosition | 組織における役割に関連付けられた番号。例えば、運動選手のジャージの番号など。 | |
| nutrition | レシピまたはメニュー項目の栄養情報。 | |
| object | 作用が及ぶ対象であり、その状態が維持されるか、変化します。また、状態が変化する「患者」「被影響者」「作用を受ける者」や、変化しない「主題」としても知られています。例:John read a book。 | |
| observationDate | Observation の observationDate。 | |
| observedNode | Observation の observedNode、しばしば StatisticalPopulation。 | |
| occupancy | 宿泊施設における宿泊可能人数(乳幼児などを含む)。個別の宿泊施設の場合、必ずしも法的な最大人数ではありませんが、契約上の利用条件を定義します(例:シングル利用のダブルルーム)。 一般的なユニットコード:C62 for person | |
| occupationLocation | この職業記述が適切である地域/国。教育要件および資格は、管轄区域によって異なる場合があることに注意してください。 | |
| occupationalCategory | 職務を説明するカテゴリで、BLS O*NET-SOC、ISCO-08または類似のタクソノミーからの用語を使用することが望ましい。該当する各値に対してプロパティを繰り返す。理想的には、タクソノミーを特定し、カテゴリのテキストラベルと正式なコードの両方を提供すること。 注:歴史的な理由により、リテラルとして提供されたテキストラベルと正式なコードは、O*NET-SOCからのものとみなされる場合があります。 |
|
| occupationalCredentialAwarded | このコースまたはプログラムを修了した結果として授与される資格、賞、証明書、卒業証書、またはその他の職業資格の説明。 | |
| offerCount | 製品のオファー数。 | |
| offeredBy | オファーを行う組織または個人へのポインタ。 | |
| offers | このアイテムを提供する申し出—例えば、製品の販売、映画のDVDのレンタル、サービスの実行、イベントへのチケットの配布などです。提供される取引の種類(販売、リースなど)を示すためにbusinessFunctionを使用してください。このプロパティはDemandを記述するためにも使用できます。このプロパティは多くの一般的なタイプで期待されるものとしてリストされていますが、他のタイプでも使用できます。その場合、ProductまたはProductのサブタイプなどの別のタイプを使用することで、申し出の内容を明確にすることができます。 | |
| offersPrescriptionByMail | 処方箋が郵送で配達可能かどうか。 | |
| openingHours | 事業の一般的な営業時間です。営業時間は、曜日から始まり、その日の時間帯として週ごとの時間範囲として指定できます。複数の曜日はカンマ「,」で区切って列挙できます。曜日または時間範囲はハイフン「-」を使用して指定します。
|
|
| openingHoursSpecification | ある場所の営業時間。 | |
| opens | 指定された曜日における、場所またはサービスの開店時間。 | |
| operatingSystem | サポートされているオペレーティングシステム (Windows 7, OSX 10.6, Android 1.6)。 | |
| opponent | 参加者のサブプロパティ。このアクションの対戦相手。 | |
| option | オブジェクトのサブプロパティ。このアクションの対象となるオプション。 | |
| orderDate | 注文日。 | |
| orderDelivery | この注文または注文品目に関連する荷物の配達。 | |
| orderItemNumber | 注文項目の識別子。 | |
| orderItemStatus | 注文項目の現在のステータス。 | |
| orderNumber | トランザクションの識別子。 | |
| orderQuantity | 注文されたアイテムの数。プロパティが設定されていない場合は、数量を1と想定します。 | |
| orderStatus | 注文の現在のステータス。 | |
| orderedItem | 注文されたアイテム。 | |
| organizer | イベントの主催者。 | |
| originAddress | 差出人の住所。 | |
| originatesFrom | 血管系およびリンパ構造が起源となる、または流入する。 | |
| overdosage | 薬物の過剰摂取に関する情報(兆候や症状、治療法、緊急対応の連絡先など)を含むもの。 | |
| ownedFrom | 製品の取得日時。 | |
| ownedThrough | 製品の所有権放棄の日時。 | |
| ownershipFundingInfo | Organization(しばしば、しかし必ずしもではないNewsMediaOrganization)について、組織の所有構造、資金調達、および助成金の説明。ニュース/メディア環境においては、特に編集の独立性に関してです。funderも利用可能であり、基本的な資金提供者情報を機械可読にすることができます。 | |
| owns | 組織または個人が所有する製品。 | |
| pageEnd | 作品が終了するページ。例えば「138」または「xvi」。 | |
| pageStart | 作業を開始するページ。例えば「135」または「xiii」。 | |
| pagination | ページ開始とページ終了に区切られていないページの記述。例えば、"1-6, 9, 55" や "10-12, 46-49" など。 | |
| parent | この人物の親。 | |
| parentItem | 質問、回答、または一般的な項目の親。 | |
| parentOrganization | この組織が属する、もしあれば、より大きな組織subOrganization。 | |
| parentService | 全国チャンネルの地域バリエーションなど、放送サービスが属する可能性のある放送サービス。 | |
| parents | その人の両親。 | |
| partOfEpisode | このクリップが属するエピソード。 | |
| partOfInvoice | 注文は、参照されている請求書の一部として支払われています。 | |
| partOfOrder | この配送に含まれていたアイテムの全体的な注文順序。 | |
| partOfSeason | このエピソードが属する季節。 | |
| partOfSeries | このエピソードまたはシーズンが属するシリーズ。 | |
| partOfSystem | この構造が属する解剖学的または器官系。 | |
| partOfTVSeries | このエピソードまたはシーズンが属するテレビシリーズ。 | |
| partOfTrip | このTripが、別のTripのサブTripであることを識別します。例えば、複数日の旅行の1日目、2日目などです。 | |
| participant | 間接的にその行動に参加した他の共犯者。例:ジョンはスティーブと本を書きました。 | |
| partySize | 予約で対応する人数。 | |
| passengerPriorityStatus | セキュリティまたは搭乗のために乗客に割り当てられた優先ステータス(例:FastTrackまたはPriority)。 | |
| passengerSequenceNumber | 航空会社によって割り当てられた乗客のシーケンス番号。 | |
| pathophysiology | この活動または状態に関連する、通常の機械的、物理的、および生化学的機能の変化。 | |
| pattern | 何かが持つ模様のことです。例えば、「水玉」、「縞模様」、「カナダの国旗」などです。値は通常テキストで表現されますが、管理された値体系へのリンクもサポートされています。 | |
| payload | 乗客と貨物の許容重量で、空車両の重量は除く。 一般的な単位コード: KGM (キログラム), LBR (ポンド)
|
|
| paymentAccepted | 現金、クレジットカード、暗号通貨、地域通貨取引システムなど | |
| paymentDue | お支払い期日。 | |
| paymentDueDate | お支払い期日。 | |
| paymentMethod | 注文のクレジットカード名またはその他の支払い方法。 | |
| paymentMethodId | 支払い方法に使用された識別子(例:クレジットカードの最後の4桁)。 | |
| paymentStatus | 支払状況。請求書が支払われたかどうか。 | |
| paymentUrl | 支払い送信用のURL。 | |
| penciler | 主要な物語のイラストを描く人物。 | |
| percentile10 | 10パーセンタイル値。 | |
| percentile25 | 25パーセンタイル値。 | |
| percentile75 | 75パーセンタイル値。 | |
| percentile90 | 90パーセンタイル値。 | |
| performTime | 指示または方向を実行するのにかかる時間(備品を準備する時間は含まない)、ISO 8601 duration形式で。 | |
| performer | イベントの出演者—例えば、プレゼンター、ミュージシャン、音楽グループ、または俳優など。 | |
| performerIn | この人物がパフォーマーまたは参加者として関わるイベント。 | |
| performers | イベントの主な出演者、例えば、プレゼンター、ミュージシャン、または俳優。 | |
| permissionType | 許可が与えられた人物、組織、または対象者の種類。 | |
| permissions | アプリを実行するために必要な権限(例えば、モバイルアプリは完全なインターネットアクセスが必要な場合や、Wi-Fiでのみ実行される場合があります)。 | |
| permitAudience | この許可の対象者。 | |
| permittedUsage | 宿泊施設の許可された使用に関する指示。 | |
| petsAllowed | 宿泊施設または宿泊事業所へのペットの立ち入りを許可するかどうかを示します。より詳細な情報は、テキスト値に入力できます。 | |
| phoneticText | テキスト textValue を指定された speechToTextMarkup で表現します。例えば、ヒューストンの都市名はIPAで: /ˈhjuːstən/。 | |
| photo | この場所の写真。 | |
| photos | この場所の写真。 | |
| physicalRequirement | 職務に関連する身体活動の種類の説明です。O*netなどの定義された用語を使用できますが、定義された用語を使用する際には、その能力レベルや性質を特定する方法がないことに注意してください。 | |
| physiologicalBenefits | プランに関連する具体的な生理学的利点。 | |
| pickupLocation | タクシーが乗客を乗せる場所、またはレンタカーが引き渡される場所。 | |
| pickupTime | タクシーが乗客を迎えに来る時、またはレンタカーが受け取れる時。 | |
| playMode | このゲームがマルチプレイヤー、協力プレイ、またはシングルプレイヤーであるかどうかを示します。ゲームは、マルチプレイヤー、協力プレイ、シングルプレイヤーのすべてとして同時にマークできます。 | |
| playerType | プレイヤーの種類が必要です—例えば、FlashまたはSilverlight。 | |
| playersOnline | サーバー上のプレイヤー数。 | |
| polygon | 多角形は、始点と終点が同じ点と点をつなぐ経路によって囲まれた領域です。多角形は、最初の点と最後の点が同一である、スペースで区切られた4つ以上の点のシリーズとして表現されます。 | |
| populationType | StatisticalPopulation のすべてのメンバーに共通する populationType を示します。 | |
| position | シリーズまたはアイテムのシーケンスにおけるアイテムのポジション。 | |
| possibleComplication | 医学的状態の予期せぬ、および好ましくない進展の可能性。合併症には、疾患の兆候または症状の悪化、他の臓器系への状態の拡大などが含まれる場合があります。 | |
| possibleTreatment | この状態、兆候、または症状に対処するための可能な治療法。 | |
| postOfficeBoxNumber | POボックス宛先の私書箱番号。 | |
| postOp | このデバイスの手術後の手順、ケア、および/またはフォローアップの説明。 | |
| postalCode | 郵便番号。例えば、94043。 | |
| postalCodeBegin | 範囲内の最初の郵便番号(含む)。 | |
| postalCodeEnd | 範囲に含まれる最後の郵便番号。postalCodeBeginより後にする必要があります。 | |
| postalCodePrefix | 共通のテキストプレフィックスで示される郵便番号の定義された範囲。英国のような数値システム以外で使用されます。 | |
| postalCodeRange | 定義された郵便番号の範囲。 | |
| potentialAction | 潜在的なアクションを示します。これは、このものが「対象」の役割を果たす理想化されたアクションを記述します。 | |
| preOp | このデバイスをインプラントする前に必要な、術後のケア、検査、およびその他の準備の説明。 | |
| predecessorOf | 製品の以前の、しばしば廃止されたバリアントから、その新しいバリアントへのポインタ。 | |
| pregnancyCategory | この薬の妊娠カテゴリー。 | |
| pregnancyWarning | この薬の妊娠中の使用に関連するあらゆる予防措置、指導、禁忌など。 | |
| prepTime | 指示または方向で使用するアイテムを準備するのにかかる時間、ISO 8601 duration形式で。 | |
| preparation | 患者が処置を受ける前に必ず行うべき一般的な準備。 | |
| prescribingInfo | 薬剤の添付文書へのリンク:{Link to prescribing information for the drug}. | |
| prescriptionStatus | 薬剤処方のステータスを示します。例:ローカルカタログの分類、または薬剤が処方箋で入手可能か、市販薬であるかなど。 | |
| previousItem | 現在のListItemの前に来るListItemへのリンク。 | |
| previousStartDate | イベントの再スケジュールまたはキャンセルされた場合に、eventStatusと組み合わせて使用します。このプロパティには、以前にスケジュールされていた開始日が含まれます。再スケジュールされたイベントの場合、新たにスケジュールされた開始日にはstartDateプロパティを使用する必要があります。イベントが複数回延期および再スケジュールされた(まれな)場合、このフィールドが繰り返されることがあります。 | |
| price | 製品の提示価格、またはPriceSpecificationとそのサブタイプに付随する価格コンポーネントの価格。 使用ガイドライン:
|
|
| priceComponent | このプロパティは、CompoundPriceSpecificationノードに並行して適用されるすべてのUnitPriceSpecificationノードにリンクします。 | |
| priceComponentType | オファーの合計金額の一部である価格コンポーネント(例えば、請求書上の明細項目)を識別します。 | |
| priceCurrency | 価格の通貨、またはPriceSpecificationとそのサブタイプにアタッチされた価格コンポーネント。 標準フォーマットを使用します: ISO 4217通貨フォーマット 例: "USD"; ティッカーシンボル 仮想通貨の場合、例: "BTC"; ローカルエクスチェンジトレーディングシステム (LETS) およびその他の通貨タイプについては、よく知られている名前を使用します。例: "Ithaca HOUR"。 |
|
| priceRange | ビジネスの価格帯は、例えば $$$ です。 |
|
| priceSpecification | 単価および配送または支払い料金を示す、1つ以上の詳細な価格仕様。 | |
| priceType | 提示された製品の価格の種類を定義します。例えば、希望小売価格、(一時的な)セール価格、またはメーカー推奨小売価格などです。オファーに複数の価格が指定されている場合、priceTypeプロパティを使用して、それぞれの指定された価格の種類を識別できます。priceTypeの値は、列挙型PriceTypeEnumerationからの値として、またはPriceTypeEnumerationにすでに定義されていない価格タイプに対して、自由形式のテキスト文字列として指定できます。 | |
| priceValidUntil | 価格が利用できなくなる日付。 | |
| primaryImageOfPage | ページ上のメイン画像を示します。 | |
| primaryPrevention | 初期の疾患発生を予防するために使用される予防療法、例えばワクチン接種など。 | |
| printColumn | 印刷版でNewsArticleが掲載されるコラムの番号。 | |
| printEdition | NewsArticle が掲載される印刷物の版。 | |
| printPage | このNewsArticleが印刷物として現れた場合、このフィールドは記事が掲載されているページ名を示します。このフィールドは正確なページ名(例:A5、B18)を意図していることにご注意ください。 | |
| printSection | このNewsArticleが印刷物で掲載された場合、このフィールドはその記事が掲載された印刷セクションを示します。 | |
| procedure | デバイスのセットアップ、使用、および/またはインストールに関する手順の説明。 | |
| procedureType | 処置の種類、例えば Surgical、Noninvasive、または Percutaneous。 | |
| processingTime | このチャンネルを使用したサービスの推定処理時間。 | |
| processorRequirements | アプリケーションを実行するために必要なプロセッサアーキテクチャ (例: IA64)。 | |
| producer | 作品(例:音楽アルバム、映画、テレビ/ラジオシリーズなど)を制作した個人または組織。 | |
| produces | サービスによって生成される有形物、例えばパスポート、許可証など。 | |
| productGroupID | ProductGroupのテキスト識別子を示します。 | |
| productID | 製品識別子、例えばISBNなどです。例:meta itemprop="productID" content="isbn:123-456-789"。 |
|
| productSupported | このサポート連絡先が関連する製品またはサービス(特定の製品ラインの製品サポートなど)。これは特定の製品または製品ライン(例:「iPhone」)または製品やサービスの一般的なカテゴリ(例:「スマートフォン」)である可能性があります。 | |
| productionCompany | アイテム(シリーズ、ビデオゲーム、エピソードなど)の制作会社またはスタジオ。 | |
| productionDate | 車両など、製品の製造日。 | |
| proficiencyLevel | このコンテンツに必要な熟練度:想定される値:'Beginner', 'Expert'。 | |
| programMembershipUsed | 予約に適用されている、頻繁なフライト、ホテルロイヤリティプログラムなど、あらゆる会員資格。 | |
| programName | メンバーシップを提供するプログラム。 | |
| programPrerequisites | プログラムへの登録要件。 | |
| programType | 教育または職業訓練プログラムの種類。例えば、教室、インターンシップ、オルターナンスなど。 | |
| programmingLanguage | コンピュータプログラミング言語。 | |
| programmingModel | APIが管理対象か、未管理かを示します。 | |
| propertyID | プロパティが表す特性を識別するための一般的に使用される識別子。例えば、プロパティの製造元または標準コードなどです。propertyIDは、(1) 製品プロパティの標準で使用されることを主な目的としたプレフィックス付き文字列、(2) サイト固有のプレフィックスなし文字列(例:プロパティの主キーまたはベンダー固有のID)、または(3) 外部ボキャブラリ、またはプロパティを記述するWebリソース(例:用語集のエントリ)を指すURLとすることができます。標準化団体は、自社の標準からのプロパティの識別子に対して標準のプレフィックスを推奨すべきです。 | |
| proprietaryName | 食事プランに与えられる固有名称で、通常は発案者または作成者によって付けられます。 | |
| proteinContent | タンパク質のグラム数。 | |
| provider | サービスプロバイダー、サービスオペレーター、またはサービス実行者;商品の生産者。別の当事者(販売者)が、プロバイダーの代わりにそれらのサービスまたは商品を提供することがあります。プロバイダーが販売者として機能することも可能です。 | |
| providerMobility | サービスが提供される可動性を示します (例: 'static', 'dynamic')。 | |
| providesBroadcastService | このチャンネルで提供されているBroadcastService。 | |
| providesService | このチャンネルが提供するサービス。 | |
| publicAccess | Place が一般公開されていることを示すフラグ。このプロパティが省略された場合、デフォルトのブール値は想定されません。 | |
| publicTransportClosuresInfo | 公共交通機関の閉鎖に関する情報。 | |
| publication | アイテムに関連する出版イベント。 | |
| publicationType | 米国 NLM MeSH 出版タイプカタログから取得した医学記事のタイプです。MeSH ドキュメントも参照してください。 | |
| publishedBy | 出版イベントに関連付けられたエージェント。 | |
| publishedOn | 出版イベントに関連する放送サービス。 | |
| publisher | クリエイティブ作品の出版社。 | |
| publisherImprint | 漫画を出版した出版部門。 | |
| publishingPrinciples | publishingPrinciplesプロパティは、(通常はURL経由で)Organization(または個人、例えばブログを書いているPerson)の出版者としての活動に関連する編集原則を記述するドキュメントを示します。例えば、倫理や多様性に関するポリシーなどです。CreativeWork(例えばNewsArticle)に適用される場合、原則はCreativeWorkの作成に主に責任を持つ当事者の原則となります。 このようなポリシーは通常、自然言語で表現されますが、関連情報(例えばfunderを示すなど)はschema.org用語を使用して表現されることもあります。 |
|
| purchaseDate | 現在の所有者が当該品(例:車両)を購入した日付。 | |
| qualifications | この役割または職種に必要な具体的な資格。 | |
| quarantineGuidelines | パンデミックなどの状況における、隔離規則に関するガイドライン。 | |
| query | instrument のサブプロパティ。このアクションで使用されたクエリ。 | |
| quest | 報酬を得るために、プレイヤーが操作するキャラクター、またはキャラクターグループが完了できるタスク。 | |
| question | オブジェクトのサブプロパティ。質問。 | |
| rangeIncludes | プロパティの値を期待される型(の1つ)を構成するクラスに、プロパティを関連付けます。 | |
| ratingCount | 評価の総数。 | |
| ratingExplanation | 結論に至った背景やその他の情報を提供する短い説明(例えば、1~2文)。これは特に、ClaimReviewを使用した「ファクトチェック」マークアップに関連する評価に適用されます。 | |
| ratingValue | コンテンツの評価。 使用ガイドライン:
|
|
| readBy | オーディオブックを読む(朗読する)人。 | |
| readonlyValue | プロパティが変更可能かどうか。デフォルトはfalseです。このプロパティに値も指定すると、HTMLフォームの「hidden」入力のように動作します。 | |
| realEstateAgent | 参加者のサブプロパティ。アクションに関与した不動産業者。 | |
| recipe | instrument のサブプロパティ。アクションを実行するために使用されるレシピ/指示。 | |
| recipeCategory | レシピのカテゴリー—例えば、前菜、メインディッシュなど。 | |
| recipeCuisine | レシピの料理の種類(例えば、フランス料理やエチオピア料理など)。 | |
| recipeIngredient | レシピで使用される単一の材料、例:砂糖、小麦粉、またはニンニク。 | |
| recipeInstructions | レシピ作成における手順で、単一の項目(ドキュメント、ビデオなど)または HowToStep や/または HowToSection 項目を含む順序付きリストの形式をとります。 | |
| recipeYield | レシピで生成される量(例えば、提供人数、サービング数など)。 | |
| recipient | 参加者のサブプロパティ。アクションの受信側である参加者。 | |
| recognizedBy | 資格の有効性、価値、または有用性を認める組織。注記:認定には、品質保証または認証のプロセスが含まれる場合があります。 | |
| recognizingAuthority | 該当する場合は、このエンティティをその承認された医療システムの一部として正式に認定する組織。 | |
| recommendationStrength | ガイドラインの推奨の強さ(例:「クラスI」)。 | |
| recommendedIntake | 特定の推奨機関によって定義された、特定の集団に対するこのサプリメントの推奨摂取量。 | |
| recordLabel | リリースを発行したラベル。 | |
| recordedAs | 作品の音声記録。 | |
| recordedAt | CreativeWorkが記録されたEvent。CreativeWorkは、そのEventの全部または一部を捉える可能性があります。 | |
| recordedIn | このイベントの全部または一部を捉えたCreativeWork。 | |
| recordingOf | このトラックが録音されている作曲は、{composition}です。 | |
| recourseLoan | 債務不履行の場合に資金を取り戻せる唯一の方法は、担保です。レコースとは、残りの資金について、依然として借り手に請求できる機会があることです。 | |
| referenceQuantity | 特定の価格が適用される基準数量。例:電気4 kWhあたり1 EUR。このプロパティは、価格が標準単位に関連しない高度なケースにおいて、unitOfMeasurementの代替として使用されます。 | |
| referencesOrder | この請求書に関連する注文(Order)は以下の通りです。1つまたは複数の注文(Order)が、1つの請求書にまとめられる場合があります。 | |
| refundType | 列挙型リストからの refundType。 | |
| regionDrained | この血管が排水する解剖学的または器官系。一般的には、器官の特定の部位を指します。 | |
| regionsAllowed | メディアが許可されている地域。指定されていない場合は、どこでも許可されているとみなされます。国をISO 3166形式で指定してください。 | |
| relatedAnatomy | 表層解剖学に関連する解剖学的システムまたは構造。 | |
| relatedCondition | この解剖学に関連する医学的状態。 | |
| relatedDrug | この薬に関連する他の薬、例えば一般的に処方される代替薬。 | |
| relatedLink | このウェブページに関連するリンク、例えば他の関連ウェブページへのリンクです。 | |
| relatedStructure | そのシステムの一部ではないが、関連または接続する関連解剖学的構造、例えば臓器系に関連する血管束など。 | |
| relatedTherapy | この解剖学に関連する医学的治療法。 | |
| relatedTo | 最も一般的な家族関係。 | |
| releaseDate | 製品または製品モデルの発売日。これは、製品の正確なバリアントを区別するために使用できます。 | |
| releaseNotes | このバージョンの変更点の説明。 | |
| releaseOf | このアルバムがリリースされるアルバムです。 | |
| releasedEvent | PublicationEventとして表現される、リリースが発行された場所と時間。 | |
| relevantOccupation | JobPostingの職種。 | |
| relevantSpecialty | 該当する場合、このエンティティに関連する医学分野。 | |
| remainingAttendeeCapacity | イベントで未割り当ての参加者枠の数。 | |
| renegotiableLoan | 融資期間中に、利息の支払い条件が再交渉可能かどうか。 | |
| repeatCount | 繰り返しのEventが起こる回数を定義します。 | |
| repeatFrequency | Events が Schedule に従って発生する頻度を定義します。イベント間の間隔は、Duration の時間として定義されるべきです。 | |
| repetitions | 活動を繰り返すべき回数。 | |
| replacee | オブジェクトのサブプロパティ。置き換えられているオブジェクト。 | |
| replacer | オブジェクトのサブプロパティ。置換するオブジェクト。 | |
| replyToUrl | 指定されたUserCommentに対して返信を投稿できるURL。 | |
| reportNumber | 報告書に発行組織によって割り当てられた番号またはその他の固有の識別子。 | |
| representativeOfPage | この画像がページのコンテンツを代表しているかどうかを示します。 | |
| requiredCollateral | 融資や信用供与の返済を担保するために必要な資産。第三者による質権設定、物品、金融商品(現金、有価証券など)の形をとることがあります。 | |
| requiredGender | 性別によって定義されたオーディエンス。 | |
| requiredMaxAge | 人の最大年齢で定義されたオーディエンス。 | |
| requiredMinAge | 年齢の最小値によって定義されたオーディエンス。 | |
| requiredQuantity | 必要な数量は{item(s)}です。 | |
| requirements | アプリケーションのコンポーネント依存要件。これには、アプリケーション配布パッケージに含まれていないものの、アプリケーションの実行に必要なランタイム環境や共有ライブラリが含まれます(例:DirectX、Javaまたは.NETランタイム)。 | |
| requiresSubscription | メディアの使用にサブスクリプション(有料または無料)が必要かどうかを示します。有効な値はtrueまたはfalseです(以前のバージョンでは「yes」、「no」を使用していました)。 |
|
| reservationFor | {thing} の予約。 | |
| reservationId | 予約の一意な識別子。 | |
| reservationStatus | 予約の現在の状況。 | |
| reservedTicket | 予約に関連付けられたチケット。 | |
| responsibilities | この役割または職務に関連する責任。 | |
| restPeriods | 活動からどのくらいの頻度で休憩を取るべきか。 | |
| result | アクションで生成された結果。例:John wrote a book。 | |
| resultComment | 結果のサブプロパティ。このアクションの結果として作成または送信されたComment。 | |
| resultReview | 結果のサブプロパティ。アクションの実行につながったレビュー。 | |
| returnFees | マーチャント返品ポリシーの返品手数料ポリシーを、列挙型オプションで示します (via enumerated options)。 | |
| returnPolicyCategory | returnPolicyCategory は、いくつかの列挙された種類の返品のうち、最大で 1 つを表現します。 | |
| review | アイテムのレビュー。 | |
| reviewAspect | このレビューまたは評価は、レビュー対象のアイテムのこの部分または側面に関連します。 | |
| reviewBody | レビューの本文です。 | |
| reviewCount | レビューの総数。 | |
| reviewRating | このレビューで与えられた評価です。レビュー自体が評価される場合があることに注意してください。reviewRatingは、レビューによって与えられた評価に適用されます。aggregateRatingプロパティは、創造的作品としてのレビュー自体に適用されます。 |
|
| reviewedBy | このウェブページのコンテンツの正確性および/または完全性をレビューした人々または組織。 | |
| reviews | 商品のレビュー。 | |
| riskFactor | この状態を発症する患者のリスクを高める、変更可能または変更不可能な要因。例:年齢、併存疾患。 | |
| risks | 食事計画に関連する特定の生理学的リスク。 | |
| roleName | 人物または組織が演じる、実行する、または担う役割。例えば、漫画の制作チームは「インカー」、「ペンシル担当」、「レタラー」という役割を担うかもしれません。あるいは、スポーツチームの選手は「クォーターバック」というポジションでプレーするかもしれません。 | |
| roofLoad | 車両の上部(例えば、ルーフレックなど)に積載できる貨物と設置物の許容総重量。 一般的な単位コード:KGM(キログラム)、LBR(ポンド)
|
|
| rsvpResponse | RSVPへの回答(はい、いいえ、たぶん)。 | |
| runsTo | 血管系とリンパ構造が走行する、または流出する場所。 | |
| runtime | 実行プラットフォームまたはスクリプトインタープリタの依存関係 (例 - Java v1, Python2.3, .Net Framework 3.0)。 | |
| runtimePlatform | 実行プラットフォームまたはスクリプトインタープリタの依存関係 (例 - Java v1, Python2.3, .Net Framework 3.0)。 | |
| rxcui | RXNORMからのRxCUI薬剤識別子。 | |
| safetyConsideration | サプリメントに関連する可能性のある安全性に関する懸念事項。 他の薬や食品との相互作用、妊娠、授乳、既知の有害反応、およびサプリメントの文書化された有効性が含まれる場合があります。 | |
| salaryCurrency | この求人情報またはこの従業員の主な給与情報に使用される通貨(ISO 4217でコード化) | |
| salaryUponCompletion | トレーニング完了時の予想年収。 | |
| sameAs | アイテムの同一性を明確に示す参照WebページのURL。例:アイテムのWikipediaページ、Wikidataエントリ、または公式ウェブサイトのURL。 | |
| sampleType | コードサンプルの種類:完全(コンパイル可能)なソリューション、コードスニペット、インラインコード、スクリプト、テンプレート。 | |
| saturatedFatContent | 飽和脂肪酸のグラム数。 | |
| scheduleTimezone | Schedule に示された時間を示すタイムゾーンを示します。提供される値は、IANA タイムゾーンデータベースにリストされているもののいずれかでなければなりません。 | |
| scheduledPaymentDate | 請求書が支払われる予定の日付。 | |
| scheduledTime | オブジェクトがスケジュールされている時間。 | |
| schemaVersion | 特定のCreativeWorkで使用されているスキーマのバージョンを(URLまたは文字列で)示します。このプロパティは主に、特定のschema.orgリリース、例えば10.0を単純な文字列として、またはより明示的にURL、https://schema.org/docs/releases.html#v10.0として示すために作成されました。他のスキーマがこの方法で参照されることが有用な状況があるかもしれません。例えばhttp://dublincore.org/specifications/dublin-core/dces/1999-07-02/ですが、コミュニティでは十分に検討されていません。 |
|
| schoolClosuresInfo | 学校閉鎖に関する情報。 | |
| screenCount | 映画館のスクリーン数。 | |
| screenshot | アプリのスクリーンショット画像のリンク。 | |
| sdDatePublished | 現在の構造化データが生成/公開された日付を示します。通常、sdPublisherと組み合わせて使用されます。 | |
| sdLicense | この構造化データに適用されるライセンスドキュメント。通常はURLで示されます。 | |
| sdPublisher | 現在の構造化データマークアップを生成および公開する責任当事者を示します。これは、構造化データが既存の公開コンテンツから自動的に派生したが、別のサイトで公開されている場合に一般的です。たとえば、学生プロジェクトやオープンデータイニシアチブは、多くの場合、既存のコンテンツをより明示的な構造化メタデータとともに再公開します。sdPublisher プロパティは、そのような慣行をより明示的にするのに役立ちます。 | |
| season | メディアシリーズのシーズン。 | |
| seasonNumber | 季節の順序付けられたグループ内での季節の位置。 | |
| seasons | メディアシリーズのシーズン。 | |
| seatNumber | 予約席の位置(例:27)。 | |
| seatRow | 予約席の行の位置(例:B)。 | |
| seatSection | 予約席の座席位置(例:オーケストラ)。 | |
| seatingCapacity | 座席数(例えば車両内など)、物理的なスペースの有無と、法的な制限の両方の観点から。 一般的な単位コード:人数に対してC62 |
|
| seatingType | 座席のタイプ/クラス。 | |
| secondaryPrevention | 初回のエピソード後、その疾患の再発を予防するために使用される予防療法です。 | |
| securityClearanceRequirement | 職務に関するセキュリティクリアランスの要件の説明。 | |
| securityScreening | 乗客が受けるセキュリティ検査の種類。 | |
| seeks | 組織または個人が求める製品またはサービスへのポインタ(需要)。 | |
| seller | サービス/商品を供給(販売/リース/貸与/融資)する主体。販売者はプロバイダーでもある場合があります。 | |
| sender | 参加者のサブプロパティ。アクションの送信側である参加者。 | |
| sensoryRequirement | 業務遂行に必要な感覚要件およびレベルの説明(聴覚および視覚を含む)。O*netなどの定義済みの用語を使用できますが、定義済みの用語を使用する場合、能力のレベルと性質の両方を指定する方法はありません。 | |
| sensoryUnit | 脳または脊髄への情報を入力し送信する神経経路の伸長。 | |
| serialNumber | 特定の製品のシリアル番号または英数字識別子。オファーに添付された場合、それはオファーに含まれる製品のシリアル番号へのショートカットです。 | |
| seriousAdverseOutcome | この治療法の可能性のある重篤な合併症および/または重篤な副作用。重篤な有害事象には、生命を脅かすもの、死亡、障害、または永続的な損傷をもたらすもの、入院を必要とするか、既存の入院を延長するもの、先天性異常または先天性欠損症を引き起こすもの、または患者を危険にさらす可能性があり、この定義におけるいずれかの結果を防ぐために医療または外科的介入が必要となるものが含まれます。 | |
| serverStatus | ゲームサーバーの状況。 | |
| servesCuisine | レストランの料理。 | |
| serviceArea | サービスが提供される地理的エリア。 | |
| serviceAudience | このサービスをご利用いただける対象者。 | |
| serviceLocation | サービスを利用できる場所(例:公共施設、商店など)。 | |
| serviceOperator | 提供者と異なる運営組織。これにより、ある組織によって提供され、下請け業者など別の組織によって運営されるサービスを表現できます。 | |
| serviceOutput | サービスによって生成される有形物、例えばパスポート、許可証など。 | |
| servicePhone | サービスにアクセスするために使用する電話番号。 | |
| servicePostalAddress | サービスへの郵送アクセス先住所。 | |
| serviceSmsNumber | サービスにSMSでアクセスするための番号。 | |
| serviceType | 提供されているサービスのタイプ、例:退役軍人向けの給付金、緊急支援など。 | |
| serviceUrl | サービスにアクセスするためのウェブサイト。 | |
| servingSize | 提供量、容量または質量における数値で表したもの。 | |
| sharedContent | この投稿の一部として共有された画像、動画、または音声クリップなどのCreativeWork。 | |
| shippingDestination | 出荷先(複数可)を示します。これらは、郵便番号範囲など、いくつかの方法で定義できます。 | |
| shippingDetails | Offerに関連する配送ポリシーとオプションに関する情報を示します。 | |
| shippingLabel | OfferShippingDetails と ShippingRateSettings に一致するラベル (shippingSettingsLink の相互参照の文脈内)。 | |
| shippingRate | 送料は、指定された宛地への送料です。通常、MonetaryAmountのmaxValueとcurrencyの値が最も適切です。 | |
| shippingSettingsLink | ShippingRateSettingsとDeliveryTimeSettingsの詳細が記載されているページへのリンク。 | |
| sibling | その人の兄弟姉妹。 | |
| siblings | その人の兄弟姉妹。 | |
| signDetected | テストで検出されたサイン。 | |
| signOrSymptom | この状態の兆候または症状。 兆候は、医学的状態の客観的または物理的に観察可能な現れであり、症状は医学的状態の主観的な経験です。 | |
| significance | 表層解剖学に関連する重要性。例えば、表層解剖学の特徴が、基礎となる医学的状態や治療方針を示唆する可能性があるという点です。 | |
| significantLink | ページ上のより重要なURLの一つです。通常、これらは最もクリックされるナビゲーション以外のリンクです。 | |
| significantLinks | ページで最も重要なURLです。通常、最もクリックされるナビゲーション以外のリンクです。 | |
| size | 製品またはクリエイティブ作品の標準サイズで、単純なテキスト文字列(例: 'XL', '32Wx34L')、unitCode を持つ QuantitativeValue、または包括的で構造化された SizeSpecification によって指定されます。その他の場合、width, height, depth, weight プロパティがより適切である場合があります。 | |
| sizeGroup | 製品のサイズに対するサイズグループ(「サイズタイプ」とも呼ばれます)。サイズグループは、ファッション業界でウェアラブル製品のサイズセグメントと推奨対象者を定義するためによく使用されます。複数の値を組み合わせることも可能です。例:「men's big and tall」、「petite maternity」、または「regular」 | |
| sizeSystem | 製品のサイズを識別するために使用されるサイズシステム。通常は、標準(例: "GS1" または "ISO-EN13402")、国コード(例: "US" または "JP")、または測定システム(例: "Metric" または "Imperial")のいずれかです。 | |
| skills | この役割を果たす、またはこの職務に従事するために必要または求められる能力、スキル、知識、タスク、またはその他の能力を表明する声明。 | |
| sku | 在庫管理ユニット(SKU)、すなわち、商品またはサービスに対するマーチャント固有の識別子、またはオファーが参照する商品。 | |
| slogan | アイテムに関連付けられたスローガンまたはモットー。 | |
| smokingAllowed | その場所(レストラン、ホテル、または客室など)で喫煙が許可されているかどうかを示します。 | |
| sodiumContent | ナトリウムのミリグラム数。 | |
| softwareAddOn | ソフトウェアアプリケーションの追加コンテンツ。 | |
| softwareHelp | ソフトウェアアプリケーションヘルプ。 | |
| softwareRequirements | アプリケーションのコンポーネント依存要件。これには、アプリケーション配布パッケージに含まれていないものの、アプリケーションの実行に必要なランタイム環境や共有ライブラリが含まれます(例:DirectX、Javaまたは.NETランタイム)。 | |
| softwareVersion | ソフトウェアインスタンスのバージョン。 | |
| sourceOrganization | 制作者が勤務していた組織。 | |
| sourcedFrom | ニューロンを発症する神経経路。 | |
| spatial | 「spatial」プロパティは、より具体的なプロパティ(例:locationCreated、spatialCoverage、contentLocation)が適切かどうか不明な場合に利用できます。 | |
| spatialCoverage | CreativeWorkのspatialCoverageは、コンテンツの焦点となっている場所を示します。これは、より技術的で詳細な資料を対象としたcontentLocationのサブプロパティです。例えば、Datasetの場合、そのDatasetが記述している地域を示します。ニューヨークの気象データセットであれば、spatialCoverageは場所、つまりニューヨーク州となります。 | |
| speakable | Webページの特に「読み上げ可能」なセクションを示します。これは、テキスト読み上げ変換に特に適しているとして強調表示されることを意味します。ページの他のセクションも、特定の状況下で有用に読み上げられる場合があります。「読み上げ可能」プロパティは、一般的に読み上げに役立つ可能性が最も高い部分を示すために使用されます。 speakable プロパティは、3種類の可能な「コンテンツ・ロケーター」値を用いて、任意の回数だけ繰り返すことができます。 1.) id-value URL参照 - アノテーションされているページの要素の id-value を使用します。speakable の最も単純な使用法は、(相対的である可能性のある)URL値であり、対象ドキュメントの識別されたセクションを参照します。 2.) CSSセレクター - クラス属性などを介して、アノテーションされたページのコンテンツをアドレス指定します。cssSelector プロパティを使用します。 3.) XPaths - コンテンツのXMLビューを想定して、XPathsを介してコンテンツをアドレス指定します。xpath プロパティを使用します。 単純なID参照を超えて、読み上げ可能なセクションをより高度にマークアップするには、CSSセレクターまたはXPath式を使用して、ドキュメントのセクションを読み上げ可能として選択します。これには、speakable プロパティの可能な値として定義される、サポートタイプ SpeakableSpecification を定義します。 |
|
| specialCommitments | この求人に関連する特別なコミットメント。有効なエントリには、VeteranCommit、MilitarySpouseCommitなどがあります。 | |
| specialOpeningHoursSpecification | 特定の場所の特別な営業時間。 これは、openingHoursSpecificationまたはopeningHoursによって範囲内に取り込まれた一般的な営業時間を明示的に上書きするために使用します。 |
|
| specialty | このウェブページの内容が適用されるドメインの専門分野の1つ。 | |
| speechToTextMarkup | マークアップの形式。例:SSML または IPA。 | |
| speed | 車両の速度範囲。車両がエンジンで駆動されている場合、速度範囲の上限(maxValueで示される)は、通常条件下で達成可能な最大速度であるべきです。 一般的な単位コード:KMH(km/h)、HM(時速、0.447 04 m/s)、KNT(ノット) *注1:範囲を示すにはminValueとmaxValueを使用します。通常、最小値はゼロです。 * 注2:速度範囲の測定方法にはさまざまなものがあります。valueReferenceプロパティを使用して、与えられた値がどのように決定されたかに関する情報へのリンクを貼ることができます。 |
|
| spokenByCharacter | 引用が帰属する、包含するクリエイティブワーク内の人物、組織、または(例えば架空の)キャラクター。 | |
| sponsor | ある物事を誓約、約束、または金銭的な貢献によって支援する個人または組織。例:医学研究のスポンサー、またはイベントの企業スポンサー。 | |
| sport | スポーツの一種(例:Baseball)。 | |
| sportsActivityLocation | location のサブプロパティ。このアクションが発生したスポーツ活動の場所。 | |
| sportsEvent | locationのサブプロパティ。このアクションが発生したスポーツイベント。 | |
| sportsTeam | 参加者のサブプロパティ。このアクションに参加したスポーツチーム。 | |
| spouse | その人の配偶者。 | |
| stage | 状態の段階、該当する場合。 | |
| stageAsNumber | ステージを数値で表したものです。例:3。 | |
| starRating | 宿泊施設または飲食店の公式評価であり、例えば、全国団体や標準化団体によるものです。評価機関を示すには、authorプロパティを使用してください。例えば、HOTREC、DEHOGA、WHR、Hotelstarsなどの名前を持つOrganizationとしてください。 | |
| startDate | アイテムの開始日時(ISO 8601日付形式)。 | |
| startOffset | 作品の開始からの秒数で表されるクリップの開始時間。 | |
| startTime | 何かのstartTime。予約されたイベントまたはサービス(例:FoodEstablishmentReservation)の場合、開始が予想される時間です。一定期間にわたるアクションの場合、アクションが実行された時間です。例:ジョンは1月から12月まで本を執筆しました。メディア(オーディオやビデオを含む)の場合、より大きなファイル内のクリップの開始位置の時間オフセットです。 Eventは、日付と時刻を記述する場合でも、startTime/endTimeではなくstartDate/endDateを使用することに注意してください。この状況は将来の改訂で明確になる可能性があります。 |
|
| status | 研究のステータス(列挙型)。 | |
| steeringPosition | ステアリングホイールまたはそれに類似する装置(主に自動車用)の位置。 | |
| step | 単一のステップ項目(HowToStep、テキスト、ドキュメント、ビデオなど)またはHowToSection。 | |
| stepValue | stepValue 属性は、PropertyValueSpecification 内の値に期待される(そして要求される)粒度を示します。 | |
| steps | 単一のステップ項目(HowToStep、テキスト、ドキュメント、ビデオなど)またはHowToSection(元々は「steps」と誤って名付けられていましたが、「step」が推奨されます)。 | |
| storageRequirements | ストレージ要件(必要な空き容量)。 | |
| streetAddress | 住所。例えば、1600 Amphitheatre Pkwy. | |
| strengthUnit | 有効成分の強度の単位、例:mg。 | |
| strengthValue | 有効成分の強度の値、例:325。 | |
| structuralClass | 骨が物理的に互いに接続される方法に与えられた名前。 | |
| study | このエンティティに関連する医学研究または臨床試験。 | |
| studyDesign | 観察研究のデザインに関する詳細(列挙)。 | |
| studyLocation | 研究が行われた/行われている場所。 | |
| studySubject | 研究の対象、すなわち研究によって調査された医学的疾患、治療法、デバイス、薬物などの一つ。 | |
| subEvent | このイベントの一部であるイベント。例えば、カンファレンスイベントには多くのプレゼンテーションが含まれており、それぞれがカンファレンスのsubEventです。 | |
| subEvents | このイベントを構成するイベント。例えば、カンファレンスイベントには多くのプレゼンテーションが含まれており、それぞれがカンファレンスのsubEventsです。 | |
| subOrganization | 2つの組織間の関係で、最初の組織が2番目の組織を含むもの。例:子会社など。また、より具体的な「department」プロパティも参照してください。 | |
| subReservation | パッケージに含まれる個々の予約。通常は繰り返しプロパティです。 | |
| subStageSuffix | サブステージ、例:ステージIIIaの「a」。 | |
| subStructure | この解剖学的構造を構成する構成要素(サブ)構造物。 | |
| subTest | パネルのコンポーネントテスト。 | |
| subTrip | この Trip のサブ Trip である Trip を識別します。例えば、複数日の旅行の 1日目、2日目などです。 | |
| subjectOf | このThingに関するクリエイティブワークまたはイベント。 | |
| subtitleLanguage | 字幕/キャプションが利用可能な言語は、IETF BCP 47標準形式です。 | |
| successorOf | 製品の新しいバリアントから、以前の、しばしば廃止された前身へのポインタ。 | |
| sugarContent | 砂糖のグラム数。 | |
| suggestedAge | 対象となる視聴者または対象者の年齢、または年齢層。例えば、乳児の場合は3~12ヶ月、幼児の場合は1~5歳です。 | |
| suggestedAnswer | 質問に対する回答(複数ある可能性があり、誤っている可能性もある)、例えば、質問/回答サイト上での回答。 | |
| suggestedGender | 対象となる人物または視聴者の想定される性別、例えば「male」、「female」、または「unisex」。 | |
| suggestedMaxAge | 対象者またはユーザーの推奨最大年齢(年)。 | |
| suggestedMeasurement | 対象となるオーディエンスまたは人物の推奨される身体測定範囲の例として、股下32~34インチ、または身長170~190cmなどがあります。通常、着用型製品のサイズチャートに記載されています。 | |
| suggestedMinAge | 対象者またはユーザーに対する推奨最低年齢(歳)。 | |
| suitableForDiet | レシピまたはメニュー項目が適している食事制限またはガイドラインを示します。例:糖尿病患者向け、ハラールなど。 | |
| superEvent | このイベントが属するイベント。例えば、個々の音楽パフォーマンスは、それぞれ音楽フェスティバルをsuperEventとして持つことがあります。 | |
| supersededBy | ある用語(例:プロパティ、クラス、または列挙型)を、それを代替する用語に関連付けます。 | |
| supply | instrumentのサブプロパティ。指示または方向を実行する際に消費される供給物。 | |
| supplyTo | 動脈が血液を供給する領域。 | |
| supportingData | SoftwareApplicationのサポートデータ。 | |
| surface | あるアート作品の表面として使用される素材。例:Canvas, Paper, Wood, Boardなど。 | |
| target | アクションのターゲット EntryPoint を示します。 | |
| targetCollection | オブジェクトのサブプロパティ。アクションのコレクション対象。 | |
| targetDescription | 確立された教育的枠組みにおけるノードの説明。 | |
| targetName | 確立された教育的枠組みにおけるノードの名前。 | |
| targetPlatform | アプリ開発の種類:phone、Metroスタイル、デスクトップ、XBoxなど。 | |
| targetPopulation | この対象となる、または通常使用する人口の特性、例:「大人」。 | |
| targetProduct | コードが適用されるターゲットOS / 製品。 複数のバージョンに適用される場合は、製品名のみを使用できます。 | |
| targetUrl | 確立された教育フレームワークにおけるノードのURL。 | |
| taxID | 組織または個人の税務識別番号(米国におけるTINやスペインにおけるCIF/NIFなど)。 | |
| teaches | 記述されている品物は、参照されている用語で定義された能力または学習成果の習得を支援することを目的としています。 | |
| telephone | 電話番号。 | |
| temporal | 「temporal」プロパティは、より具体的なプロパティ(例:temporalCoverage、dateCreated、dateModified、datePublished)が適切かどうか不明な場合に利用できます。 | |
| temporalCoverage | CreativeWorkのtemporalCoverageは、コンテンツが適用される期間、すなわち記述する期間を示します。これは、DateTimeまたはISO 8601時間間隔形式のテキスト文字列として表現されます。Datasetの場合、通常は関連する期間を正確な表記(例:2011年の国勢調査データセットの場合、2011年は「2011/2012」と記述されます)で示します。 ScholarlyArticle、Book、TVSeries、TVEpisodeなどの他のコンテンツ形式は、temporalCoverageをより広い範囲で示すことがあります。テキストまたは周知のURLを使用します。
書籍などの著作物は、正確なtemporalCoverageを持つこともあります。例えば、1939年から1945年を舞台にした作品は、ISO 8601間隔形式で「1939/1945」と示すことができます。 終了日が不明な日付範囲は、「..」で終了日を置き換えて記述できます。例えば、「2015-11/..」は、2015年11月から開始し、終了日が指定されていない範囲を示します。これは暫定的なものであり、ISO 8601が公式に更新された際に更新される可能性があります。 |
|
| termCode | DefinedTermSet 内のこの DefinedTerm を識別するコード | |
| termDuration | 機関によって定義される学期の期間。学期とは、学生が1つまたは複数の授業を受ける期間のことです。セメスターやクォーターは、学期の一般的な単位です。 | |
| termsOfService | 人間が読める利用規約ドキュメント。 | |
| termsPerYear | 1年間に学習期間が提供される回数。学期と四半期は、学習期間の一般的な単位です。例えば、学生が1年でプログラムを2学期しか履修できない場合、termsPerYearは2になります。 | |
| text | このCreativeWorkのテキストコンテンツ。 | |
| textValue | 注釈付けられているテキスト値。 | |
| thumbnail | 画像または動画のサムネイル画像。 | |
| thumbnailUrl | Thingに関連するサムネイル画像。 | |
| tickerSymbol | 法人オブジェクトに関連付けられた取引所取引証券。ティッカーシンボルは、スペース文字で区切られた取引所と銘柄名で表されます。ティッカーシンボル属性の取引所コンポーネントについては、ISO15022で指定された市場識別コード(MIC)の管理語彙を使用することを推奨します。 | |
| ticketNumber | チケットの一意な識別子。 | |
| ticketToken | 入場可能なアセットへの参照(例:バーコード、QRコード画像、またはPDF)。 | |
| ticketedSeat | チケットに関連付けられた座席。 | |
| timeOfDay | プログラムが通常実行される時間帯。例えば、「evenings」。 | |
| timeRequired | この学習リソースに取り組む、または学習するための、典型的な対象者にとってのおおよその時間、例: 'PT30M', 'PT1H25M'。 | |
| timeToComplete | プログラムをフルタイムで受講した場合の修了までの予想期間。 | |
| tissueSample | 検査に必要な組織サンプルの種類。 | |
| title | 求人のタイトル。 | |
| titleEIDR | EIDR (Entertainment Identifier Registry) identifier は、最も一般的/抽象的なレベルで、映画またはテレビ作品を表します。 例えば、「ゴーストバスターズ」という映画には、タイトルEIDRとして "10.5240/7EC7-228A-510A-053E-CBB8-J" があります。このタイトル(または作品)には、EIDRが「編集」と呼ぶ複数のバリアントが存在します。editEIDR を参照してください。 schema.org のタイプ (Movie や TVEpisode) は、作品とそれらの複数の表現の両方に使用できるため、一般的な説明には titleEIDR のみを使用するか、より編集に特化した説明には editEIDR と共に使用することが可能です。 |
|
| toLocation | locationのサブプロパティ。アクション後のオブジェクトまたはエージェントの最終的な場所。 | |
| toRecipient | 受信者のサブプロパティ。メッセージが直接送信された受信者。 | |
| tocContinuation | HyperTocEntry は、tocContinuation を示すことができ、それは次に再生またはレンダリングする既定の HyperTocEntry です。 | |
| tocEntry | HyperToc 内の HyperTocEntry を示します。 | |
| tongueWeight | 車両に連結されたトレーラーの許容垂直荷重(TWR)。タング荷重定格(TLR)または垂直荷重定格(VLR)とも呼ばれます 一般的な単位コード:KGM(キログラム)、LBR(ポンド)
|
|
| tool | instrument のサブプロパティ。指示または方向を実行する際に使用される(ただし消費されない)オブジェクト。 | |
| torque | 車両エンジンのトルク(回転力)。 一般的な単位コード:ニュートンメートル(N m)の場合はNU、ポンドフィートの場合はF17、ポンドインチの場合はF48
|
|
| totalJobOpenings | この求人広告で募集しているポジションの数。正の整数を使用してください。ポジションの数が不明または不明な場合は使用しないでください。 | |
| totalPaymentDue | お支払い総額。 | |
| totalPrice | 予約またはチケットの合計金額(適用される税金、送料などを含む) 使用ガイドライン:
|
|
| totalTime | 指示または方向を実行するために必要な合計時間(備品を準備する時間を含む)、ISO 8601 期間形式で。 | |
| tourBookingPage | 何らかのPlace(例えば不動産設定におけるAccommodationやApartmentComplexなど)のツアー予約方法に関する情報を提供するページ。必要に応じて、その他の種類のツアーについても説明します。 | |
| touristType | 観光客のタイプ(例:子供、特定の国からの訪問者など)に適した観光スポット。 | |
| track | 音楽録音(トラック)—通常は単一の楽曲です。ItemListが与えられた場合、そのリストにはMusicRecordingタイプのアイテムが含まれている必要があります。 | |
| trackingNumber | 差出人追跡番号。 | |
| trackingUrl | 荷物の配達状況追跡URL:{Tracking url}。 | |
| tracks | 音楽録音(トラック)—通常は1曲。 | |
| trailer | 映画やテレビ/ラジオシリーズ、シーズン、エピソードなどの予告編。 | |
| trailerWeight | 車両に牽引されるトレーラーの許容重量。 一般的な単位コード: KGM (キログラム), LBR (ポンド) * 注記 1: QuantitativeValue ノードの name に追加情報を記載できます。 * 注記 2: valueReference を使用して、追加情報を提供する QualitativeValue ノードにリンクすることもできます。 * 注記 3: minValue と maxValue を使用して範囲を示すことができることに注意してください。 |
|
| trainName | 列車の名前(例:The Orient Express)。 | |
| trainNumber | 列車のユニークな識別子。 | |
| trainingSalary | プログラム期間中に得られる推定給与。 | |
| transFatContent | トランス脂肪酸のグラム数。 | |
| transcript | このMediaObjectがAudioObjectまたはVideoObjectの場合、そのオブジェクトのトランスクリプトです。 | |
| transitTime | 注文が配送のために送信され、商品が最終顧客に届くまでの典型的な遅延。典型的なプロパティ:minValue, maxValue, unitCode (d は DAY を意味します)。 | |
| transitTimeLabel | OfferShippingDetails と DeliveryTimeSettings に一致するラベル (shippingSettingsLink の相互参照の文脈内)。 | |
| translationOfWork | この作品が翻訳された元となる作品。例:物種起源は“On the Origin of Species”のtranslationOfです。 | |
| translator | ターゲット市場の言語、地域差、技術的要件に合わせて創造的な作品を適応させる組織または個人、または何らかのイベントで翻訳を行う人。 | |
| transmissionMethod | 疾患がどのように広がるか、経路または媒介体として、例えば「直接接触」、「Aedes aegypti」など。 | |
| travelBans | パンデミックなどの状況における渡航禁止に関する情報。 | |
| trialDesign | 試験デザインに関する詳細(列挙)。 | |
| tributary | 静脈が流れ込む解剖学的または器官系。静脈が接続するより大きな構造。 | |
| typeOfBed | BedDetailが参照するベッドの種類、すなわち、数量「quantity」で示される数量で利用可能なベッドの種類。 | |
| typeOfGood | この構造化データが参照している製品は、{product}です。 | |
| typicalAgeRange | 典型的な予想される年齢層、例:'7-9'、'11-'。 | |
| typicalCreditsPerTerm | フルタイムの学生が1学期に履修すると予想される単位数またはクレジット数ですが、「学期」の定義は各機関によって異なります。 | |
| typicalTest | この状態の場合に通常行われる医療検査。 | |
| underName | 予約またはチケットの対象者または団体。 | |
| unitCode | UN/CEFACT共通コード(3文字)またはURLを使用して与えられた測定単位。UN/CEFACT共通コード以外のコードは、プレフィックスの後にコロンを付けて使用できます。 | |
| unitText | 測定単位を示す文字列またはテキスト。unitCodeの標準単位コードを提供できない場合に役立ちます。 | |
| unnamedSourcesPolicy | Organization(通常はNewsMediaOrganization)向けの、匿名の情報源の使用に関する方針と、意思決定プロセスに関する声明。 | |
| unsaturatedFatContent | 不飽和脂肪のグラム数。 | |
| uploadDate | このメディアオブジェクトがこのサイトにアップロードされた日付。 | |
| upvoteCount | この質問、回答、またはコメントがコミュニティから受け取ったアップボートの数。 | |
| url | 商品のURL。 | |
| urlTemplate | アクションの実行ターゲットを構築するために使用される URL テンプレート (RFC6570)。 | |
| usageInfo | schema.orgのusageInfoプロパティは、CreativeWorkに関する付加的な情報を示します。このプロパティは、自由に利用可能な作品と、支払いまたはその他の取引が必要な作品の両方に適用されます。好ましいリンクと引用慣例に関するコミュニティの期待や、購入の詳細など、追加の情報への参照を含めることができます。商業的にライセンス供与できるものの場合、usageInfoは、リソース固有のライセンスオプションに関する詳細情報を提供できます。 このプロパティは、コンテンツに適用されるライセンスを示すlicenseプロパティと組み合わせて使用できます。usageInfoプロパティは、非営利的なクリエイティブ・コモンズ・ライセンスでも利用可能な画像の商用利用権を取得するなど、他のライセンスオプションに関する情報を提供できます。 |
|
| usedToDiagnose | テストが診断に使用される状態。 | |
| userInteractionCount | Webサイトまたはソフトウェアアプリケーションを使用してCreativeWorkに対するインタラクションの数。 | |
| usesDevice | テストに使用したデバイス。 | |
| usesHealthPlanIdStandard | Plan IDの解釈の標準。推奨は「HIOS」です。詳細はCenters for Medicare & Medicaid Servicesを参照してください。 | |
| utterances | メディアオブジェクトの特定のセクションで発生する発話(話し言葉、歌詞など)のテキストを、HyperTocEntryとして表現したもの。 | |
| validFor | 許可証またはそれに類するものの有効期間。 | |
| validFrom | アイテムが有効になる日付。 | |
| validIn | 許可証またはそれに類するもの**が有効な地理的範囲**。 | |
| validThrough | アイテムが無効になる日付後。例えば、オファーの終了、給与期間、または営業時間期間などです。 | |
| validUntil | アイテムが無効になる日付。 | |
| value | 定量値またはプロパティ値ノードの値。
|
|
| valueAddedTaxIncluded | 価格仕様に、適用される付加価値税(VAT)が含まれるかどうかを指定します。 | |
| valueMaxLength | リテラル値の文字数の許容範囲を指定します。 | |
| valueMinLength | リテラル値の文字数の最小許容範囲を指定します。 | |
| valueName | URLテンプレートおよびフォームエンコーディングで、HTMLのinput@nameと同様の方法で使用するPropertyValueSpecificationの名前を示します。 | |
| valuePattern | HTML仕様に従ってリテラル値をテストするための正規表現を指定します。 | |
| valueReference | 元の値に関する追加情報を提供する二次的な値。例えば、基準温度や測定の種類などです。 | |
| valueRequired | アクションを完了するために、プロパティが入力される必要があるかどうか。デフォルトはfalseです。 | |
| variableMeasured | variableMeasuredプロパティは、あるデータセットで測定される変数を、テキストとして、またはPropertyValueを使用した識別子と説明のペアとして示すことができます(必要に応じて繰り返します)。 | |
| variantCover | 号が変形版の場合の表紙の説明です。例えば、「Bryan Hitch 変形版カバー」または「第2刷変形版」などです。 | |
| variesBy | ProductGroup 内のバリアントがどのように異なるかを示すプロパティ(サイズ、色など)。Schema.org プロパティは、短縮名(例: "color")で参照できます。他の場所で定義された用語は、URI で参照できます。 | |
| vatID | 組織または個人の付加価値税ID。 | |
| vehicleConfiguration | 車両の構成を示す短いテキスト、例: '5dr hatchback ST 2.5 MT 225 hp' または 'limited edition'。 | |
| vehicleEngine | 車両のエンジンまたはエンジンに関する情報。 | |
| vehicleIdentificationNumber | 車両識別番号(VIN)は、自動車業界で使用される個々の自動車を識別するための固有のシリアル番号です。 | |
| vehicleInteriorColor | 車両内装の色または色の組み合わせ。 | |
| vehicleInteriorType | 車両内装の種類または素材(例:合成繊維、レザー、木材など)。ほとんどの内装タイプは使用されている素材によって特徴づけられますが、内装タイプは車両の使用目的やターゲット層に基づいている場合もあります。 | |
| vehicleModelDate | 車両モデルの発売日(同じメーカーとモデルのバージョンを区別するためによく使用されます)。 | |
| vehicleSeatingCapacity | 車両に座席を設けられる乗客数。物理的なスペースの有無と、法的な制限の両方を含みます。 一般的な単位コード:人数に対してはC62です。 |
|
| vehicleSpecialUsage | 車両が、レンタカー、教習車、タクシーなど、特別な目的で使用されていたかどうかを示します。多くの国の法律では、自動車を販売する際にこの情報を開示することが義務付けられています。 | |
| vehicleTransmission | 回転動力源から車輪またはその他の関連するコンポーネント(「ギアボックス」車の場合)へ動力を伝達するために使用されるコンポーネントの種類。 | |
| vendor | 'vendor' は 'seller' の古い用語です。 | |
| verificationFactCheckingPolicy | NewsMediaOrganizationまたはその他のファクトチェックを行うOrganizationの検証およびファクトチェックプロセスの開示。 | |
| version | 指定されたリソースによって具現化されたCreativeWorkのバージョン。 | |
| video | 埋め込まれたビデオオブジェクト。 | |
| videoFormat | 上映またはビデオ放送の種類(例:IMAX、3D、SD、HDなど)。 | |
| videoFrameSize | ビデオのフレームサイズ。 | |
| videoQuality | 動画の品質。 | |
| volumeNumber | 出版物または複数巻本の巻数を示します。例えば、「iii」または「2」です。 | |
| warning | 薬に関するFDAまたはその他の警告(テキストまたはURL)。 | |
| warranty | オファーに含まれる保証の約束(たち)。 | |
| warrantyPromise | オファーに含まれる保証の約束(たち)。 | |
| warrantyScope | 保証の範囲。 | |
| webCheckinTime | オンラインでフライトにチェックインできる時間。 | |
| webFeed | フィードのURL、例えばポッドキャストシリーズ、ブログ、または日付付き更新のシリーズに関連付けられたもの。通常はRSSまたはAtomです。 | |
| weight | 製品または人の重さ。 | |
| weightTotal | 積載車両の許容総重量(乗員、貨物、および車両自体の重量を含む)。 一般的な単位コード:KGM(キログラム)、LBR(ポンド)
|
|
| wheelbase | 前輪と後輪の中心間の距離。 一般的な単位コード:CMT(センチメートル)、MTR(メートル)、INH(インチ)、FOT(フィート) |
|
| width | アイテムの幅。 | |
| winner | 参加者のサブプロパティ。アクションの勝者。 | |
| wordCount | 条項の本文に含まれる単語数。 | |
| workExample | このクリエイティブ作品の概念の例/インスタンス/実現/派生。例:ペーパーバック版、初版、またはeBook。 | |
| workFeatured | 何らかのイベントに掲載された作品、例えば ExhibitionEvent で展示されたもの。 workPerformed(例えば劇)や workPresented(ScreeningEvent での上映作品である映画)に対して、特定のサブプロパティが利用可能です。 | |
| workHours | この仕事の標準的な勤務時間(例:1st shift、night shift、8am-5pm)。 | |
| workLocation | 個人の勤務地の連絡先。 | |
| workPerformed | 何らかのイベントで実行される作品。例えば、TheaterEventで実行される劇。 | |
| workPresented | このイベントで上映された映画。 | |
| workTranslation | この作品の内容を翻訳した作品。例:西遊記には、英語のworkTranslation “Journey to the West”、ドイツ語のworkTranslation “Monkeys Pilgerfahrt”、ベトナム語の翻訳 Tây du ký bình khảo がある。 | |
| workload | 運動の生理的出力の定量的な測定値。また、エネルギー消費量とも呼ばれます。 | |
| worksFor | 人が勤務する組織。 | |
| worstRating | この評価システムで許可される最小値です。worstRatingが省略された場合、1とみなされます。 | |
| xpath | SpeakableSpecificationまたはWebPageElementのXPath。後者の場合、ページ内の複数のマッチは、単一の概念的な「Webページ要素」を構成することがあります。 | |
| yearBuilt | Accommodation が建設された年。これはRESOの YearBuilt フィールドに対応します。 | |
| yearlyRevenue | 年間売上高における事業規模。 | |
| yearsInOperation | ビジネスの年齢。 | |
| yield | 指示を実行した結果生じる量。例えば、紙飛行機、{10}個のパーソナライズされたキャンドル。 |
タイプ
| Type | Description | Meta information |
|---|---|---|
| 3DModel | 3Dモデルは、何らかの3Dコンテンツを表し、1つ以上のMediaObject内にencodingsを持つ可能性があります。多くの3D形式が利用可能です(例:Wikipediaを参照);特定のエンコーディング形式は、関連するMediaObjectに適用されたencodingFormatプロパティを使用して表現できます。Zip圧縮後に公開された単一ファイルの場合、encodingFormatに'+zip'を付加する規約を使用できます。地理空間、AR/VR、芸術/アニメーション、ゲーム、エンジニアリング、科学的なコンテンツはすべて3DModelを使用して表現できます。 | |
| AMRadioChannel | AM放送局。 | |
| APIReference | アプリケーションプログラミングインターフェース (API) の参照ドキュメント。 | |
| Abdomen | 腹部の臨床検査。 | |
| AboutPage | ウェブページのタイプ: Aboutページ。 | |
| AcceptAction | オブジェクトへのコミット/採用行為。 関連アクション:
|
|
| Accommodation | 宿泊施設とは、ホテルの一室、キャンプ場、会議室など、人間が滞在できる場所のことです。多くの宿泊施設は一泊滞在を目的としていますが、必須要件ではありません。
schema.orgで定義されていないより具体的な種類の宿泊施設については、外部ボキャブラリーとともにadditionalTypeを使用できます。
ホテルやその他の宿泊施設のマークアップにおけるschema.orgの使用に関する専用ドキュメントも参照してください。 |
|
| AccountingService | 会計事業。 LocalBusiness としては、1つ以上の Service(s) の provider と記述できます。 |
|
| AchieveAction | 以前の努力によって何かを成し遂げる行為。それは継続的なプロセスではなく、瞬間的な行動である。 | |
| Action | 直接的な主体と間接的な参加者によって直接目的語に対して行われるアクション。オプションで、不活発な道具の助けを借りて特定の場所で発生します。アクションの実行は結果を生み出す可能性があります。具体的なアクションサブタイプドキュメントは、各引数/役割に対する正確な期待を規定します。 関連項目:ブログ投稿およびアクション概要ドキュメント。 |
|
| ActionAccessSpecification | アクションを実行するために満たされなければならない要件のセット。 | |
| ActionStatusType | アクションのステータス。 | |
| ActivateAction | デバイスまたはアプリケーションを開始またはアクティブにする行為(例:タイマーを開始したり、フラッシュライトを点灯させたりすること)。 | |
| ActivationFee | 提供された製品の総価格のうち、例えば携帯電話契約における、初期費用部分を表します。 | |
| ActiveActionStatus | 進行中のアクション(例:映画を見ている間、またはどこかへ車で行く間など)。 | |
| ActiveNotRecruiting | アクティブですが、新規参加者はいずれも募集していません。 | |
| AddAction | コレクションにオブジェクトを追加することで行う編集作業。 | |
| AdministrativeArea | 特定の政府の管轄下にある地理的な地域。 | |
| AdultEntertainment | 大人の娯楽施設。 | |
| AdvertiserContentArticle | 外部主体が掲載または仕様に基づいて制作するために費用を支払ったArticle。広告記事、スポンサードコンテンツ、ネイティブアド、その他の有料コンテンツが含まれます。 | |
| AerobicActivity | 比較的低強度の身体活動で、主に有酸素的なエネルギー生成プロセスに依存するもの。活動中、有酸素代謝は運動中のエネルギー需要を適切に満たすために酸素を利用します。 | |
| AggregateOffer | 単一の製品が複数のオファーと関連付けられている場合(例えば、同じペアの靴が異なる販売業者から提供されている場合)、AggregateOfferを使用できます。 注:AggregateOfferは通常、すべて同じ定義されたbusinessFunction値を持つ複数のオファーを関連付けることが期待されます。businessFunctionが明示的に定義されていない場合は、http://purl.org/goodrelations/v1#Sellがデフォルトになります。 |
|
| AggregateRating | 複数の評価またはレビューに基づく平均評価。 | |
| AgreeAction | 対象との意見の一貫性の表明という行為。エージェントは、参加者と共に、対象(命題、話題、またはテーマ)に同意する/について合意する。 | |
| Airline | 乗客のためにフライトを提供する組織。 | |
| Airport | 空港。 | |
| AlbumRelease | AlbumRelease. | |
| AlignmentObject | 学習リソースと教育フレームワークのノードとの整合性を記述する非物理的な項目。 この整合性の性質を単純なプロパティで記述できる場合は使用しないでください。例えば、リソースがコンピテンシーをteachesまたはassessesと表現する場合などです。 |
|
| AllWheelDriveConfiguration | オールホイールドライブは、エンジンが車輪4つすべてを駆動するトランスミッションのレイアウトです。 | |
| AllergiesHealthAspect | 健康トピックに関するアレルギー関連の側面についてのコンテンツ。 | |
| AllocateAction | タスク/オブジェクト/イベントにリソースを関連付けて整理する行為。 | |
| AmpStory | オンライン、特にモバイルデバイスで閲覧することを意図した、視覚的なストーリーテリング形式のクリエイティブワーク。 | |
| AmusementPark | 遊園地。 | |
| AnaerobicActivity | 高強度の物理的活動であり、体の嫌気性代謝を利用します。 | |
| AnalysisNewsArticle | 分析ニュース記事は、事実に基づいた報道を基にしながらも、著者/プロデューサーの専門知識を取り入れ、解釈と結論を提供するNewsArticleです。 | |
| AnatomicalStructure | 人体のあらゆる部分で、通常は解剖学的システムの構成要素です。臓器、組織、細胞はすべて解剖学的構造です。 | |
| AnatomicalSystem | 解剖学的システムは、特定のタスクを実行するために協力して機能する解剖学的構造のグループです。臓器系のような解剖学的システムは、解剖学の組織化原理の一つであり、循環器系、消化器系、内分泌系、皮膚系、免疫系、リンパ系、筋肉系、神経系、生殖器系、呼吸器系、骨格系、泌尿器系、前庭系、およびその他のシステムを含みます。 | |
| Anesthesia | 麻酔薬とその応用の研究を扱う医学の一分野。 | |
| AnimalShelter | 動物保護シェルター。 | |
| Answer | 質問に対する答え。正しいかもしれないし、意見が含まれているか、間違っているかもしれません。 | |
| Apartment | アパート(アメリカ英語)またはフラット(イギリス英語)は、建物の一部のみを占有する自立した住宅ユニット(住宅不動産の一種)です(出典:Wikipedia、フリー百科事典、http://en.wikipedia.org/wiki/Apartment)。 | |
| ApartmentComplex | 居住形態: アパートメント。 | |
| Appearance | 臨床検査を伴う外観評価。 | |
| AppendAction | 順序付けられたコレクションの末尾に挿入する行為。 | |
| ApplyAction | 組織/サービスへの登録行為で、それを受け取る保証がない場合。 関連アクション:
|
|
| ApprovedIndication | 規制当局によって正式に指定または承認された、医療治療法の適応症。例えば、米国FDAは米国におけるほとんどの医薬品の適応症を承認します。 | |
| Aquarium | 水族館。 | |
| ArchiveComponent | あらゆるアーカイブコンテンツに適用される非具象的な型で、アーカイブアイテムおよびコレクションを記述するために必要な一連のプロパティを伴います。 | |
| ArchiveOrganization | 公文書館などの資料を保管する組織。資料を保管・保存し、一般に公開する組織。 | |
| ArriveAction | 場所に到着する行為。エージェントは、参加者と一緒に、またはそうでない状態で、fromLocationから目的地に到着します。 | |
| ArtGallery | 美術館。 | |
| Artery | 心臓から血液を運び出す特定の種類の血管。 | |
| Article | 記事、例えばニュース記事や調査報道の文章。新聞や雑誌には様々な種類の記事があり、これらはそれら全てを網羅することを意図しています。 関連項目 ブログ記事。 |
|
| AskAction | 誰かに質問 / 頼み事をすること。 関連するアクション:
|
|
| AskPublicNewsArticle | NewsArticle は、報道目的で、ある問題に関して一般市民から意見、洞察、明確化、逸話、資料などを求める NewsMediaOrganization による公開呼びかけを表現するものです。 | |
| AssessAction | 意見、反応、または感情を形成する行為。 | |
| AssignAction | あるアクション/イベント/タスクを、ある宛先(誰かまたは何か)に割り当てる行為。 | |
| Atlas | 主題を説明する地図、海図、図版、または表のコレクションまたは綴じられた本。 | |
| Attorney | 専門サービス:弁護士。 このタイプは非推奨です - LegalService の方が包括的で曖昧性が低いです。 |
|
| Audience | アイテムの対象読者、すなわち、そのアイテムが作成された対象グループ。 | |
| AudioObject | 音声ファイル。 | |
| Audiobook | オーディオブック。 | |
| AudiobookFormat | 書籍フォーマット: Audiobook。これは、bookFormatプロパティで使用するための列挙値です。bib拡張にも、Audiobook固有のプロパティを含むタイプ 'Audiobook' が存在します。 | |
| AuthoritativeLegalValue | ドキュメントの出版に関して、出版社が何らかの特別な地位を与えていることを示します(英国議会法案の「The Queens Printer」バージョン、またはEU官報局が発行した指令のPDFバージョンなど)。「Authoritative(権威ある)」ものは、またOfficialLegalValueと見なされます。 | |
| AuthorizeAction | オブジェクトに許可を与える行為。 | |
| AutoBodyShop | 自動車修理工場。 | |
| AutoDealer | 自動車販売店。 | |
| AutoPartsStore | 自動車部品店。 | |
| AutoRental | レンタカー事業。 | |
| AutoRepair | 自動車修理業。 | |
| AutoWash | 洗車ビジネス。 | |
| AutomatedTeller | ATM/キャッシュマシン。 | |
| AutomotiveBusiness | 自動車修理、販売、または部品。 | |
| Ayurvedic | 数千年前からインドで発祥し、身体、心、精神の統合とバランスに焦点を当てた医学体系。 | |
| BackOrder | 在庫切れですが、バックオーダー可能です。 | |
| BackgroundNewsArticle | 特定のトピック(別名「解説」または「背景資料」)に関する歴史的背景、定義、詳細を提供するNewsArticle。例えば、気候変動や欧州連合などのテーマに関する詳細な記事や、よくある質問(FAQ)文書。ニュース以外の環境からの背景資料は、特にScholarlyArticleを用いてBookまたはArticleと表現されることが多い。学習/教育の観点からの関連語彙については、NewsArticleも参照のこと。 | |
| Bacteria | 細菌感染を引き起こす病原菌。 | |
| Bakery | パン屋。 | |
| Balance | 姿勢とバランスを維持するために行われる身体活動。 | |
| BankAccount | 銀行が提供する商品またはサービスで、お金を入金、引き出し、または送金でき、場合によっては利息が支払われるもの。 | |
| BankOrCreditUnion | 銀行または信用組合。 | |
| BarOrPub | バーまたはパブ。 | |
| Barcode | バーコードやQRコードなどの視覚的に機械可読なコードの画像。 | |
| BasicIncome | BasicIncome: これはベーシックインカムのための給付金です。 | |
| Beach | ビーチ。 | |
| BeautySalon | 美容院。 | |
| BedAndBreakfast | ベッド&ブレックファスト。
また、ホテルやその他の宿泊施設をマークアップするためのschema.orgの使用に関する専用ドキュメントも参照してください。 |
|
| BedDetails | 利用可能なベッドタイプに関する詳細情報を持つエンティティ。例えば、ホテルの部屋にあるツインベッドの数量などです。特定のタイプのベッドが1つしかない場合は、テキスト付きのベッドを直接使用できます。BedType(開発中)も参照してください。 | |
| BedType | ベッドの種類。宿泊施設で利用可能なベッドまたはベッド数を示すために使用されます。 | |
| BefriendAction | 誰か(対象)と相互に/双方向に/対称的に個人的な繋がりを築く行為。 関連するアクション:
|
|
| BenefitsHealthAspect | トピックの利用または活用に関する利点と優位性についての内容。 | |
| BikeStore | 自転車店。 | |
| Blog | ブログ。 | |
| BlogPosting | ブログ投稿。 | |
| BloodTest | 患者の血液サンプルに対して行われた医学検査。 | |
| BoardingPolicyType | 航空会社で使用される搭乗ポリシーの一種。 | |
| BoatReservation | ボート旅行の予約。 注:これは実際の予約に関する情報用です(例:確認メールや個々の予約確認ページ)。チケットのオファーの場合は、Offerを使用してください。 |
|
| BoatTerminal | ボート、船、その他の水上車両用のターミナル。 | |
| BoatTrip | 商業フェリー航路での旅行。 | |
| BodyMeasurementArm | 腕の長さ(腕の交差部分/肩のラインと目立つ手首の骨の間で測定)。例えば、シャツのサイズ合わせに使用されます。 | |
| BodyMeasurementBust | バストの最大周囲長。例えば、婦人服のスーツのサイズ合わせに使用されます。 | |
| BodyMeasurementChest | 胸囲の最大値。例えば、紳士服のサイズ合わせなどに使用されます。 | |
| BodyMeasurementFoot | 足の長さ(最も突出したつま先の端と最も突出したかかとの部分の間で測定)。例えば、靴下を測るために使用されます。 | |
| BodyMeasurementHand | 最大手囲(親指を除き、右手の拳の上の部分を測る)。例えば、手袋のサイズ合わせに使用されます。 | |
| BodyMeasurementHead | 頭の耳上の最大周囲長。例えば、帽子をフィットさせるために使用されます。 | |
| BodyMeasurementHeight | 身長(頭頂から足の裏までの長さ)。例えば、ジャケットのサイズ合わせなどに使用されます。 | |
| BodyMeasurementHips | ヒップの周囲(お尻周りの寸法)。例えば、スカートのサイズ合わせに使用されます。 | |
| BodyMeasurementInsideLeg | 股下(股から足の裏までの長さ)。例えば、ズボンを合わせるために使用されます。 | |
| BodyMeasurementNeck | 首回り。例えば、シャツのサイズ合わせなどに使用されます。 | |
| BodyMeasurementTypeEnumeration | 人の体の測定値の種類(または寸法)を列挙します。例えば、衣服の試着のために使用します。 | |
| BodyMeasurementUnderbust | バスト直下の胴囲。例えば、婦人用水着のサイズ合わせに使用されます。 | |
| BodyMeasurementWaist | 自然なウエストラインの周囲(股骨と下部肋骨の間)。例えば、ズボンを合わせるために使用されます。 | |
| BodyMeasurementWeight | 体重。例えば、ストッキングのサイズを測るために使用されます。 | |
| BodyOfWater | 海、海洋、湖などの水域。 | |
| Bone | 人体の骨格構造を構成する硬い結合組織。 | |
| Book | 本。 | |
| BookFormatType | 本の出版形式。 | |
| BookSeries | 書籍のシリーズです。含まれる書籍は hasPart プロパティで示すことができます。 | |
| BookStore | 書店。 | |
| BookmarkAction | エージェントがオブジェクトをブックマーク/フラグ/ラベル/タグ付け/マークします。 | |
| Boolean | ブール値: True または False。 | |
| BorrowAction | 合意の下で後日返すことを条件に、ある物を得る行為。LendActionの逆。 関連するアクション:
|
|
| BowlingAlley | ボウリング場。 | |
| BrainStructure | 感覚および知的活動、神経活動の調整機能を持つ軟質な神経組織に関連するあらゆる解剖学的構造。 | |
| Brand | ブランドとは、組織または事業者が製品、製品群、または類似品にラベルを付けるために使用する名称です。 | |
| BreadcrumbList | BreadcrumbListは、通常、そのURLと名前で記述され、現在のページで終わる、リンクされたWebページのチェーンで構成されるItemListです。 positionプロパティは、BreadcrumbList内の項目の順序を再構築するために使用されます。慣例として、BreadcrumbリストはitemListOrderがItemListOrderAscending(値が小さいものが最初にリストされる)を持ち、このリストの最初の項目は、サイトまたはセクションのホームページなど、Breadcrumbトレイルの「上部」または開始部分に対応します。'position'の具体的な値はBreadcrumbListに対して意味が割り当てられませんが、整数である必要があります。たとえば、リストの最初の項目の場合、'1'から始めるなどです。 |
|
| Brewery | 醸造所。 | |
| Bridge | 橋。 | |
| BroadcastChannel | CableOrSatelliteServiceのラインナップにおけるBroadcastServiceのユニークなインスタンス。 | |
| BroadcastEvent | 空中またはオンラインの放送イベント。 | |
| BroadcastFrequencySpecification | 特定のBroadcastServiceで使用される周波数(MHz)と変調方式。 | |
| BroadcastRelease | BroadcastRelease. | |
| BroadcastService | 放送またはオンラインを通じてコンテンツを提供する配信サービス。 | |
| BrokerageAccount | 投資家が資金を預け入れ、認可されたブローカーまたは証券会社に投資注文を出せる口座。 | |
| BuddhistTemple | お寺。 | |
| BusOrCoach | バス(またはオムニバス、オートバス)は、乗客を輸送するように設計された道路車両です。コーチは高級バスで、通常は長距離旅行で使用されます。 | |
| BusReservation | バス旅行の予約。 注:これは実際の予約に関する情報用です(例:確認メールや個々の予約確認ページ)。チケットのオファーの場合は、Offerを使用してください。 |
|
| BusStation | バス停。 | |
| BusStop | バス停。 | |
| BusTrip | 商業バス路線の旅行。 | |
| BusinessAudience | 企業に属する特性の集合体、例えば、アイテムのターゲットオーディエンスを構成する人々。 | |
| BusinessEntityType | 事業体タイプは、組織または事業者の法的形態、規模、主な事業内容、バリューチェーンにおける位置、またはそれらの組み合わせを表現する概念的なエンティティです。 一般的に使用される値:
|
|
| BusinessEvent | イベントタイプ: ビジネスイベント。 | |
| BusinessFunction | ビジネス機能は、オファーを通じて組織または事業者が提供する活動またはアクセス(すなわち、権利の束)のタイプを特定します。典型的なものとしては、販売、賃貸またはリース、保守または修理、製造/生産、リサイクル/廃棄、エンジニアリング/建設、または設置があります。アクセスの権利に関する独自の仕様も、このクラスのインスタンスです。 一般的に使用される値:
|
|
| BusinessSupport | BusinessSupport: これは、事業を支援するメリットです。 | |
| BuyAction | 商品またはサービスと引き換えに、売り手に金銭を支払う行為。エージェントは、価格に対して、売り手からオブジェクト、製品、またはサービスを購入します。SellActionの逆。 | |
| CDCPMDRecord | CDCPMDRecordは、病院データ報告に使用されるCDCの表形式データ形式におけるレコードを表すデータ構造です。詳細はドキュメントを参照し、信頼できる定義のソースとして使用されている、リンクされたCDC資料もご確認ください。 | |
| CDFormat | CDFormat. | |
| CT | エックス線コンピュータ断層撮影。 | |
| CableOrSatelliteService | テレビやラジオなどのメディア番組へのアクセスを提供するサービスです。アクセスはケーブルまたは衛星経由で行われる場合があります。 | |
| CafeOrCoffeeShop | カフェまたはコーヒーショップ。 | |
| Campground | キャンプ場、campsite、または Campground は、屋外での一晩の滞在に使用される場所で、通常は個別の CampingPitch があります。 イギリス英語では、campsite は、テント、キャンパーバン、キャラバンを使用して一晩キャンプできる区画に分割されたエリアを指します。このイギリス英語での単語の使用は、アメリカ英語の campground と同義です。アメリカ英語では、campsite という用語は、通常、個人、家族、グループ、または軍隊がテントを張ったり、キャンパーを駐車したりできるエリアを指します。キャンプ場には多くの campsite が含まれる場合があります (出典: Wikipedia 参照 https://en.wikipedia.org/wiki/Campsite)。 ホテルやその他の宿泊施設をマークアップするための schema.org の使用に関する専用の ドキュメントも参照してください。 |
|
| CampingPitch | CampingPitch は、屋外での一晩の滞在のための個別の場所であり、通常はより大きなキャンプ場、または Campground の一部です。 イギリス英語では、キャンプ場、またはキャンプグラウンドは、テント、キャンパーバン、キャラバンを使用して一晩キャンプできる区画に分割されたエリアを指します。このイギリス英語での単語の使用は、アメリカ英語のキャンプグラウンドという表現と同義です。アメリカ英語では、キャンプサイトという用語は、個人、家族、グループ、または軍隊がテントを張ったり、キャンパーを駐車したりできるエリアを一般的に指します。キャンプグラウンドには多くのキャンプサイトが含まれる場合があります。 (出典: Wikipedia 参照 https://en.wikipedia.org/wiki/Campsite). ホテルやその他の宿泊施設をマークアップするためのschema.orgの使用に関する専用の ドキュメントも参照してください。 |
|
| Canal | パナマ運河のような運河。 | |
| CancelAction | 将来のイベント/アクションがもう起こらないと主張する行為。 関連アクション:
|
|
| Car | 車は、輸送のために使用される車輪付きの自走式自動車です。 | |
| CarUsageType | 車の特別な使用状況を示す値。例えば、商用レンタカー、教習所、またはタクシーとして使用する場合など。 | |
| Cardiovascular | 心臓および血管系の障害の診断と治療に関わる医学の特定の分野。 | |
| CardiovascularExam | 臨床検査による心血管系評価。 | |
| CaseSeries | 症例報告(臨床症例報告としても知られる)は、特定の曝露歴を持つ患者を追跡し、同様の治療を受けた患者を追跡するか、曝露と結果について医療記録を調査する医学研究です。症例報告は、回顧的または前向きであり、通常、より強力なケースコントロール研究やランダム化比較試験よりも少ない数の患者を対象とします。症例報告は、報告者への一定期間の症例のすべてが含まれているか、または選択されたものかによって、連続的または非連続的になる場合があります。 | |
| Casino | カジノ。 | |
| CassetteFormat | カセット形式。 | |
| CategoryCode | カテゴリコード。 | |
| CategoryCodeSet | カテゴリコード値のセット。 | |
| CatholicChurch | カトリック教会。 | |
| CausesHealthAspect | トピックが生じた原因と主な行動に関する情報。 | |
| Cemetery | 墓地。 | |
| Chapter | 本が分割される区分の一つ。章には通常、節番号または名前が付けられます。 | |
| CharitableIncorporatedOrganization | CharitableIncorporatedOrganization: 慈善団体を指す非営利型法人(英国)。 | |
| CheckAction | エージェントは、あるオブジェクトの正確性、品質、状態、または状況を検査、判断、調査、問い合わせ、または検証します。 | |
| CheckInAction | エージェント(サービスプロバイダー、ソーシャルメディアなど)が、以前に予約したサービス(例:フライトチェックイン)または場所(例:ホテル)に登録/確認することで、到着を伝達する行為。結果(搭乗券など)を伴う場合もある。 関連アクション:
|
|
| CheckOutAction | エージェント(サービスプロバイダー、ソーシャルメディアなど)が、以前に予約していたサービス(例:フライトチェックイン)または場所(例:ホテル)からの退去を伝達する行為。 関連アクション:
|
|
| CheckoutPage | Webページの種類: チェックアウトページ。 | |
| ChildCare | 保育園。 | |
| ChildrensEvent | イベントタイプ: Children's event. | |
| Chiropractic | 体の構造、主に脊椎と、その機能との関係性に焦点を当てた医学体系。 | |
| ChooseAction | オプションまたは大規模または無制限の選択肢/オプションのセットから優先順位を表現する行為。 | |
| Church | 教会。 | |
| City | 市または町。 | |
| CityHall | 市役所。 | |
| CivicStructure | タウンホールやコンサートホールなどの公共施設。 | |
| Claim | Schema.orgにおけるClaimは、特定の事実に基づいた主張を表し、ClaimReviewにおけるitemReviewedとなりえます。主張の内容はtextプロパティで要約できます。よく知られた主張のバリエーションは、sameAsリンクで共通のアイデンティティを示すことができ、nameで要約できます。理想的には、Claimの説明には、曖昧さや不明確さのリスクを最小限に抑えるために十分なコンテキスト情報が含まれている必要があります。実際には、多くの主張は、それらが現れるコンテキストや、主張レビューによって提供される解釈の中でより良く理解されます。 ClaimReviewを超えて、Claimタイプは関連するクリエイティブ作品に関連付けられる可能性があります。たとえば、ScholarlyArticleやQuestionは、あるClaimについてaboutである可能性があります。 現時点では、Schema.orgは主張間の関係のタイプを定義していません。これは将来の探求の自然な領域です。 |
|
| ClaimReview | あるクリエイティブな作品(itemReviewedで参照)に含まれる主張(または報告)に対するファクトチェックのレビュー。 | |
| Class | クラス。しばしば「Type」とも呼ばれ、rdfs:Class と同等です。 | |
| CleaningFee | 提供された製品(例えば、バケーションレンタルなど)の総価格のうち、清掃費部分を表します。 | |
| Clinician | 臨床医、すなわち臨床実践に従事する医師やその他の医療専門家。 | |
| Clip | 短いテレビまたはラジオ番組、または番組のセグメント/一部。 | |
| ClothingStore | 衣料品店。 | |
| CoOp | プレイモード:CoOp。友達と同じチームでプレイする協力ゲームです。 | |
| Code | コンピュータプログラミングのソースコード。例:完全(コンパイル可能)な解答、コードスニペットのサンプル、スクリプト、テンプレート。 | |
| CohortStudy | パネルスタディとしても知られています。コホート研究は、医学および社会科学で使用される縦断研究の一種です。これは研究デザインの一種であり、横断研究と比較する必要があります。コホートとは、特定の期間内に共通の特徴または経験を共有する人々のグループ(例:出生、学校退学、失業、薬物またはワクチンへの曝露など)のことです。比較グループは、コホートが抽出された一般人口である場合もあれば、調査対象の物質への曝露がほとんどまたは全くないと考えられている別のコホートである場合もあります。あるいは、コホート内のサブグループ同士を比較することもできます。 | |
| Collection | 作品や製品などのアイテムのコレクション。 | |
| CollectionPage | Webページの種類: コレクションページ。 | |
| CollegeOrUniversity | 大学、あるいはその他の高等教育機関。 | |
| ComedyClub | コメディクラブ。 | |
| ComedyEvent | イベントタイプ: コメディイベント。 | |
| ComicCoverArt | コミックの表紙の絵柄。 | |
| ComicIssue | 個々のコミックは、より大きなシリーズの一部として連続的に出版されます。一貫性を保つため、読み切り号であっても、単一号で構成されるシリーズに属します。すべてのコミックは、以下の組み合わせによって一意に識別できます:コミックが属するシリーズの名前と巻数、号数、およびコミックのバリアントの説明(存在する場合)。 | |
| ComicSeries | 一連のコミックストーリーの連続出版で、例えば「The Amazing Spider-Man」や「Groo the Wanderer」のように、統一されたタイトルを持つものです。 | |
| ComicStory | 「ストーリー」という用語は、コミックの分割不可能な、再印刷可能な 単位であり、内部ストーリー、表紙、およびバックマターが含まれます。 ほとんど のコミックには少なくとも2つのストーリーがあります:表紙(ComicCoverArt)と内部ストーリー。 | |
| Comment | アイテムに関するコメント - 例えば、ブログ投稿へのコメントなど。コメントの内容はtextプロパティで、話題はaboutプロパティで表現されます。これらはすべてのCreativeWorkで共有されるプロパティです。 | |
| CommentAction | ある主題についてのコメントを生成する行為。 | |
| CommentPermission | ドキュメントにコメントを追加する権限。 | |
| CommunicateAction | 情報やメッセージを、会話、メール、電話などのコミュニケーション手段(器具)を通して他者に伝える行為。 | |
| CommunityHealth | 特定の集団の健康特性を、その地理的または環境領域との関連において改善することに焦点を当てた公衆衛生の分野。 | |
| CompilationAlbum | コンピレーションアルバム。 | |
| CompleteDataFeed | CompleteDataFeed は、フィード内の現在すべてのアイテムのコンテンツを標準表現に含んでいる DataFeed です。 これは、Feed Paging and Archiving RFC 5005 で定義されている Atom の要素と同等です。たとえば(Atom で定義されているように)、時間とともに変化するアイテムのコレクションを表すフィード(例:「トップ20レコード」)を使用する場合、新しいエントリを古い、廃止されたエントリと混在させる必要はありません。このフィードを CompleteDataFeed としてマークすることで、フィードが更新されたときに古いエントリを安全に破棄できます。なぜなら、フィードが現在すべてのアイテムの説明を提供していると想定できるからです。 |
|
| Completed | 完了しました。 | |
| CompletedActionStatus | 既に発生したアクション。 | |
| CompoundPriceSpecification | 複合価格仕様は、消費の異なる側面に対して組み合わせて適用される複数の価格をまとめたものです。価格コンポーネントの側面(例: "electricity" または "final cleaning")を示すには、添付された単価仕様のnameプロパティを使用してください。 | |
| ComputerLanguage | このタイプは、SchemeやLispなどのコンピュータプログラミング言語、およびその他の言語に似たコンピュータ表現を扱います。自然言語は、Languageタイプで最も適切に表現されます。 | |
| ComputerStore | コンピュータ店。 | |
| ConfirmAction | 将来のイベント/アクションが予想通りに起こることを誰かに通知する行為。 関連アクション:
|
|
| Consortium | コンソーシアムは、メンバーが通常、組織であるOrganizationの会員組織です。 | |
| ConsumeAction | 情報/リソース/食物の摂取行為。 | |
| ContactPage | Webページの種類: 問い合わせページ。 | |
| ContactPoint | 連絡窓口—たとえば、お客様相談部など。 | |
| ContactPointOption | ContactPointに関連する列挙型オプション。 | |
| ContagiousnessHealthAspect | トピックに関する伝播メカニズムと感染性に関する情報。 | |
| Continent | 大陸のいずれか(例えば、ヨーロッパまたはアフリカ)。 | |
| ControlAction | エージェントがデバイスまたはアプリケーションを制御します。 | |
| ConvenienceStore | コンビニエンスストア。 | |
| Conversation | 特定のトピックに関する組織または個人間の1つ以上のメッセージ。個々のメッセージは、isPartOfまたはhasPartプロパティを使用して会話にリンクできます。 | |
| CookAction | 食料の生産/準備の行為。 | |
| Corporation | 組織: 株式会社。 | |
| CorrectionComment | comment が CreativeWork を修正する。 | |
| Country | 国。 | |
| Course | 教育コースは、異なる時点、異なる場所、または異なるメディアや学習方法で提供される別個のインスタンスとして提供される可能性があります。教育コースとは、学習者の知識、能力、または技能の構築を目的とする、1つ以上の教育イベントおよび/または創作物のシーケンスです。 | |
| CourseInstance | Courseのインスタンスであり、他のインスタンスと異なり、時間、場所、メディア、学習方法、または特定の学生セクションが異なることで区別されます。 | |
| Courthouse | 裁判所。 | |
| CoverArt | CreativeWorkのアウターサーフェスにあるアートワーク。 | |
| CovidTestingFacility | CovidTestingFacility は、COVID-19 Coronavirus 疾患の検査が利用可能な MedicalClinic です。施設が確立された Pharmacy、Hotel、またはその他の非医療機関から提供されている場合、複数のタイプをリストできます。これにより、その場所に関する既存の schema.org 情報(連絡先情報、住所、営業時間など)を再利用しやすくなります。ただし、緊急時には、そのような情報が常に信頼できるとは限りません。 | |
| CreateAction | エージェントから意図的に結果を創造/生成/構築すること。 | |
| CreativeWork | 書籍、映画、写真、ソフトウェアプログラムなど、最も一般的な種類の創作物。 | |
| CreativeWorkSeason | メディアシーズン、例:テレビ、ラジオ、ビデオゲームなど。 | |
| CreativeWorkSeries | schema.orgにおけるCreativeWorkSeriesは、関連する項目のグループであり、通常は同じ種類ですが、必ずしもそうである必要はありません。CreativeWorkSeriesは通常、何らかの順序で整理され、多くの場合、時系列順になります。ItemListとは異なり、これはあらゆる種類のリストのための汎用データ構造ですが、CreativeWorkSeriesは、出版物(書籍や雑誌などの著作物、またはテレビ、ラジオ、ゲームなどのメディア)に重点を置いています。 TVSeries、RadioSeries、MovieSeries、BookSeries、Periodical、およびVideoGameSeriesを記述するための特定のサブタイプが用意されています。各ケースにおいて、hasPart / isPartOfプロパティを使用して、CreativeWorkSeriesとその構成要素を関連付けることができます。一般的なCreativeWorkSeriesタイプは、これらのより具体的で実用的なサブタイプを整理するために主に役立ちます。 シリーズの項目に適用可能なプロパティを、包含するグループに役立つ形で適用することは一般的です。Schema.orgはこれらのケースの一部を予測しようとしますが、出版社は、適切と思われる場合は、シリーズの構成要素のプロパティをシリーズ全体に適用しても構いません。 |
|
| CreditCard | 特定のブランドまたは名称のカード決済方法。特定の決済方法および/またはカード口座を提供する金融商品/サービスをマークアップするために使用されます。 一般的に使用される値:
|
|
| Crematorium | 火葬場。 | |
| CriticReview | CriticReview は、レビュー活動で認められた情報源によって書かれたり公開されたりする、より専門的なレビュー形式です。これには、オンラインコラム、旅行およびフードガイド、テレビおよびラジオ番組、ブログ、その他の独立系ウェブサイトが含まれます。CriticReview は通常、より詳細でプロフェッショナルに書かれています。よりシンプルで、カジュアルに書かれたユーザー/訪問者/視聴者/顧客のレビューの場合は、UserReview タイプを使用する方が適切です。Metacriticのようなレビュー集計サイトは、すでにサイトのユーザーレビューと、サードパーティの情報源から派生した厳選された批評家のレビューを分けています。 | |
| CrossSectional | 既存のデータ(通常は「スナップショット」調査から得られたもの)に基づいて行われた研究。例えば、国勢調査局によって収集されたデータなど。しばしば有病率調査とも呼ばれる。 | |
| CssSelectorType | CSSセレクターを表すテキスト。 | |
| CurrencyConversionService | ある通貨から別の通貨へ資金を変換するサービス。 | |
| DDxElement | 鑑別診断プロセスにおいて、通常後期に考慮される、密接に関連する代替の状態と、それを区別するために使用される徴候。 | |
| DJMixAlbum | DJMixAlbum. | |
| DVDFormat | DVDFormat. | |
| DamagedCondition | 商品が破損していることを示します。 | |
| DanceEvent | イベントタイプ:社交ダンス。 | |
| DanceGroup | ダンスグループ―例えば、アルビン・エイリー・ダンス・シアターやリバーダンスなど。 | |
| DataCatalog | データセットのコレクション。 | |
| DataDownload | ダウンロード可能な形式のデータセット。 | |
| DataFeed | 1つまたは複数のエンティティまたはトピックに関する構造化情報を提供する単一のフィード。 | |
| DataFeedItem | より大きなデータフィード内の単一の項目。 | |
| DataType | 整数、文字列などの基本的なデータ型 | |
| Dataset | あるトピック(s)に関心のある、構造化された情報の集合。 | |
| Date | ISO 8601日付形式の日付値。 | |
| DateTime | ISO 8601 の第 5.4 章を参照してください。[-]CCYY-MM-DDThh:mm:ss[Z|(+|-)hh:mm] の形式の日付と時刻の組み合わせ。 | |
| DatedMoneySpecification | DatedMoneySpecificationは、オプションの開始日と終了日を持つ金額を表します。例えば、これは特定の期間における従業員の給与を表すことができます。注: このタイプはMonetaryAmountに置き換えられました。そのタイプの使用を推奨します。 | |
| DayOfWeek | 曜日。例えば、OpeningHoursSpecificationの営業時間を示す曜日を指定するために使用されます。 当初は、GoodRelationsからのURLが使用されていました(Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sundayに加え、PublicHolidays用の特別なエントリもありました)。これらは現在、schema.orgに直接統合されています。 |
|
| DaySpa | デイスパ。 | |
| DeactivateAction | デバイスまたはアプリケーションを停止または無効化する行為(例:タイマーを停止したり、フラッシュライトをオフにしたりすること)。 | |
| DecontextualizedContent | MediaReview内で「文脈の欠如」とコード化されたコンテンツは、公開または共有された状況を考慮して判断されます。 VideoObjectが「文脈の欠如」であるとは:映像を改変せずに不正確な方法で提示し、映像の内容を誤って表現すること。例えば、誤った日付や場所を使用したり、トランスクリプトを改変したり、視聴者を誤解させるために長い動画から短いクリップを共有したりすること。(「オリジナル」と評価された動画も文脈が欠如している可能性があります。) ImageObjectが「文脈の欠如」であるとは:画像を改変せずに不正確な方法で提示し、画像の内容を誤って表現し、視聴者を誤解させること。例えば、一般的な戦術として、改変されていない画像を使用し、それが別の時間または場所から来たものだと主張することが挙げられます。(「オリジナル」と評価された画像も文脈が欠如している可能性があります。) 埋め込みテキストを持つImageObjectが「文脈の欠如」であるとは:画像を改変せずに不正確な方法で提示し、画像の内容を誤って表現し、視聴者を誤解させること。例えば、一般的な戦術として、改変されていない画像を使用し、それが別の時間または場所から来たものだと主張することが挙げられます。(不正確なテキストを持つ「オリジナル」の画像は、一般的にこのカテゴリに該当します。) AudioObjectが「文脈の欠如」であるとは:音声を改変せずに不正確な方法で提示し、その内容を誤って表現すること。例えば、誤った日付や場所を使用したり、視聴者を誤解させるために長い録音から短いクリップを共有したりすること。(「オリジナル」と評価された音声も文脈が欠如している可能性があります。) |
|
| DefenceEstablishment | 軍や海軍基地のような防衛施設。 | |
| DefinedRegion | DefinedRegionは、政治的、行政的、または自然な地理的基準ではなく、任意の基準で定義された地理的領域です。郵便番号のセットを参照して領域を定義するためのプロパティが提供されます。 例:オンラインショッピングの配送先。地域価格が設定されている地域。 要件1: 国:US 州: "NY", "CA" 要件2: 国:US 郵便番号セット:{ [94000-94585], [97000, 97999], [13000, 13599]} { [12345, 12345], [78945, 78945], } Region = 州、カントン、県、自治州… |
|
| DefinedTerm | 正式な定義を持つ単語、名前、頭字語、句など。多くの場合、カテゴリまたは主題の分類、用語集や辞書、製品またはクリエイティブ作品の種類などの文脈で使用されます。定義されている用語にはnameプロパティを使用し、用語に英数字コードが割り当てられている場合はtermCodeを使用し、用語の定義にはdescriptionを使用します。 | |
| DefinedTermSet | 定義済みの用語のセット。例えば、カテゴリのセット、分類方式、用語集、辞書、または列挙。 | |
| DefinitiveLegalValue | 法的に拘束力のある、法律の内容を決定的に示す文書を示します。(例:電子署名された公報のバージョン。) 「決定的な」ものは、またAuthoritativeLegalValueと見なされます。 | |
| DeleteAction | 受信者をそのオブジェクトの1つを削除することで編集する行為。 | |
| DeliveryChargeSpecification | 特定の配送方法を利用したオファーの配送にかかる価格。 | |
| DeliveryEvent | アイテムの配送を含むイベント。 | |
| DeliveryMethod | 配送方法は、顧客が選択した配送先へ製品またはサービスを移送するための標準化された手順です。配送方法は、使用される輸送手段と、発送組織または個人との契約当事者である組織またはグループによって特徴付けられます。 一般的に使用される値:
|
|
| DeliveryTimeSettings | DeliveryTimeSettings は、配送のタイミングに関する再利用可能な配送情報のまとまりを表します。これは、OfferShippingDetails の shippingSettingsLink プロパティを通じて参照される可能性のある URL で公開されるように設計されています。複数のインスタンスを公開でき、それらは transitTimeLabel の異なる値によって区別(および識別/参照)されます。 | |
| Demand | 需要エンティティは、組織または個人による、特定の種類の商品またはサービスを求める、必ずしも拘束力がない、必ずしも排他的でない、公的な発表を表します。このタイプを使用して需要を記述するには、オファーに使用されるのと同じプロパティを適用します。 | |
| DemoAlbum | DemoAlbum. | |
| Dentist | 歯科医。 | |
| Dentistry | 歯科医療に関わる医学の一分野。 | |
| DepartAction | 場所からの出発という行為。エージェントは、fromLocationから目的地へ、オプションで参加者と共に移動します。 | |
| DepartmentStore | デパート。 | |
| DepositAccount | 利息やその他の特典を得るために資金を預け入れることを主な目的とする銀行口座の一種。 | |
| Dermatologic | 皮膚科に関する、または皮膚科を実践する何か。 | |
| Dermatology | 皮膚の疾患の診断と治療に関わる医学の一分野。 | |
| DiabeticDiet | 糖尿病の方に適した食事。 | |
| Diagnostic | 診断目的で使用される医療機器。 | |
| DiagnosticLab | オンサイトまたはオフサイトの診断サービスを提供する臨床検査施設。 | |
| DiagnosticProcedure | 診断を主な目的とした、治療を目的としない医療処置。 | |
| Diet | 特定の健康関連の目標を達成または維持するために、食物摂取量を調整する戦略。 | |
| DietNutrition | 医学専門分野としての栄養学および食事療法。 | |
| DietarySupplement | 口から摂取し、食事を補完することを目的とした栄養成分を含む製品。栄養成分には、ビタミン、ミネラル、ハーブまたはその他の植物、アミノ酸、および酵素、臓器組織、腺、代謝物などの物質が含まれる場合があります。 | |
| DigitalAudioTapeFormat | デジタルオーディオテープフォーマット. | |
| DigitalDocument | 電子ファイルまたはドキュメント。 | |
| DigitalDocumentPermission | 特定の人物またはグループが特定のファイルにアクセスするための許可。 | |
| DigitalDocumentPermissionType | デジタルドキュメントにアクセスするために付与できる権限のタイプ。 | |
| DigitalFormat | デジタルフォーマット。 | |
| DisabilitySupport | 障害者支援: これは障害者支援の給付金です。 | |
| DisagreeAction | 対象に対して意見の相違を表明する行為。主体は、参加者と共に、対象(命題、話題、またはテーマ)に反対/について意見を異にする。 | |
| Discontinued | 製品は廃番となりました。 | |
| DiscoverAction | 物体の発見/見つけ出す行為。 | |
| DiscussionForumPosting | ディスカッションフォーラムへの投稿。 | |
| DislikeAction | 対象について否定的な感情を表明する行為。主体は、参加者と共に、対象(命題、話題、またはテーマ)を嫌悪する。 | |
| Distance | 距離を値として取るプロパティは、'<Number> <Length unit of measure>' の形式です。例: '7 ft'。 | |
| DistanceFee | 提示された製品の総価格のうち、距離料金(例えば、1kmまたは1マイルあたりの価格)の部分を表します。例として、レンタカーなどがあります。 | |
| Distillery | 蒸留所。 | |
| DonateAction | 対価なしに商品、サービス、またはお金を提供する行為で、しばしば慈善的な理由によるものです。 | |
| DoseSchedule | 薬またはサプリメントの特定の投与スケジュール。 | |
| DoubleBlindedTrial | 研究者も患者も、患者に無作為に割り当てられた治療の詳細を知らない試験デザイン。 | |
| DownloadAction | オブジェクトをダウンロードする行為。 | |
| Downpayment | 頭金(前払い)価格を、分割払いがある提供された製品の総価格の構成要素として表します。 | |
| DrawAction | 物体を、通常はペン/鉛筆と紙を道具として、視覚的/図形的な表現として作り出す行為。 | |
| Drawing | 鉛筆、ペン、またはクレヨンを使って描かれた絵や図、絵の具ではなく。 | |
| DrinkAction | 液体の嚥下。 | |
| DriveWheelConfigurationValue | トルクが供給されるロードホイールを示す値。 | |
| DrivingSchoolVehicleUsage | 運転教習車の使用を示します。 | |
| Drug | 生物に生理的な影響を与える、医療療法として使用される化学物質または生物学的物質。ここで「薬」という用語は「医薬品」という用語と互換的に使用されますが、臨床的な知識はそれらの間に明確な違いを設けます。 | |
| DrugClass | 医薬品のクラス、例えばスタチン。クラスは、一般的な薬理学的クラス、共通の作用機序、共通の生理学的効果などを表すことができます。 | |
| DrugCost | 医薬品1単位あたりの費用。このタイプは、販売される医薬品の価格を表すことを意図していません。販売タイプを参照してください。このタイプは通常、医薬品の卸売価格または平均小売価格、または最大限の払い戻し可能な費用をタグ付けするために使用されます。医薬品の費用は、支払い方法や場所によって大きく異なるため、このタイプは変数をいくつか捉えますが、このスキーマのマークアップの消費者は費用を注意して使用する必要があります。 | |
| DrugCostCategory | 医療用医薬品費用の列挙されたカテゴリー。 | |
| DrugLegalStatus | 医薬品の法的利用可能性ステータス。 | |
| DrugPregnancyCategory | 妊娠中に母親が指示どおりに使用した薬または医薬品によって胎児に傷害が生じるリスクの評価を表すカテゴリー。 | |
| DrugPrescriptionStatus | この薬が処方箋で入手可能か、または市販薬であるかを示します。 | |
| DrugStrength | 特定の国で医薬品が利用可能な特定の強度。 | |
| DryCleaningOrLaundry | クリーニング店。 | |
| Duration | 数量: 期間 (ISO 8601 期間形式を使用)。 | |
| EBook | 書籍の形式:Ebook. | |
| EPRelease | EPRelease。 | |
| EUEnergyEfficiencyCategoryA | EUエネルギー効率クラスAを、EUエネルギー表示規制で定義されているものとして表します。 | |
| EUEnergyEfficiencyCategoryA1Plus | EUのエネルギー効率クラスA+を、EUのエネルギー表示規制で定義されているものとして表します。 | |
| EUEnergyEfficiencyCategoryA2Plus | EUエネルギー効率クラスA++を、EUエネルギー表示規制で定義されているものとして表します。 | |
| EUEnergyEfficiencyCategoryA3Plus | EUのエネルギー効率クラスA+++を表します。EUのエネルギー表示規制で定義されています。 | |
| EUEnergyEfficiencyCategoryB | EUエネルギー効率クラスBを、EUエネルギー表示規制で定義されているものとして表します。 | |
| EUEnergyEfficiencyCategoryC | EUエネルギー効率クラスCを、EUエネルギー表示規制で定義されているものとして表します。 | |
| EUEnergyEfficiencyCategoryD | EUエネルギーラベル規制で定義されているEUエネルギー効率クラスDを表します。 | |
| EUEnergyEfficiencyCategoryE | EUエネルギー効率クラスEを、EUのエネルギー表示規制で定義されているものとして表します。 | |
| EUEnergyEfficiencyCategoryF | EUエネルギー効率クラスFを表します。EUのエネルギー表示規制で定義されています。 | |
| EUEnergyEfficiencyCategoryG | EUエネルギーラベル規制で定義されているEUエネルギー効率クラスGを表します。 | |
| EUEnergyEfficiencyEnumeration | EU指令2017/1369で定義されているEUのエネルギー効率クラスA-G、およびA+、A++、A+++を列挙します。 | |
| Ear | 臨床検査による耳機能評価。 | |
| EatAction | 固形物を飲み込む行為。 | |
| EditedOrCroppedContent | MediaReview内で「編集またはトリミングされたコンテンツ」とコード化され、公開または共有された状況を考慮したもの。 VideoObjectが「編集またはトリミングされたコンテンツ」である場合:動画が編集または再構成されていること。このカテゴリは、時間編集、複数の動画を編集して語られるストーリーを変えたり、動画から大きな部分を編集したりする場合に適用されます。 ImageObjectが「編集またはトリミングされたコンテンツ」である場合:視聴者を誤解させるために、より大きな全体の一部として画像を表示すること。 埋め込みテキストを持つImageObjectが「編集またはトリミングされたコンテンツ」である場合:視聴者を誤解させるために、より大きな全体の一部として画像を表示すること。 AudioObjectが「編集またはトリミングされたコンテンツ」である場合:オーディオが編集または再構成されていること。このカテゴリは、時間編集、複数のオーディオクリップを編集して語られるストーリーを変えたり、録音から大きな部分を編集したりする場合に適用されます。 |
|
| EducationEvent | イベントタイプ: 教育イベント。 | |
| EducationalAudience | EducationalAudience. | |
| EducationalOccupationalCredential | 教育または職業的な資格。資格発行者によって定義された要件を満たす人物またはその他のエンティティに授与される可能性のある卒業証書、学術的な学位、認定、資格、バッジなど。 | |
| EducationalOccupationalProgram | ある機関が提供するプログラムで、学位や資格などの成果を達成するための学習進捗を決定するものです。これは、明確な開始、終了、要件のセットを持ち、新しい就業機会(例:仕事、コース)への移行を構成する、離散的な機会のセット(例:仕事、コース)を定義します。または、時には高等教育の機会(例:高度な学位)となることもあります。 | |
| EducationalOrganization | 教育機関。 | |
| EffectivenessHealthAspect | 健康トピックに関する有効性関連の側面についての内容。 | |
| Electrician | 電気技師。 | |
| ElectronicsStore | 電気店。 | |
| ElementarySchool | 小学校。 | |
| EmailMessage | メールメッセージ。 | |
| Embassy | 大使館。 | |
| Emergency | 外傷または急病によって引き起こされる医学的状態の評価と初期治療を扱う医学の一分野。 | |
| EmergencyService | 火災署や救急病院のような緊急サービス。 | |
| EmployeeRole | 従業員関係を記述するために使用されるOrganizationRoleのサブクラス。 | |
| EmployerAggregateRating | 組織の雇用主としての役割に関連する集計評価。 | |
| EmployerReview | EmployerReview は、ある Organization が雇用主としての役割について、その組織の現従業員または元従業員によって書かれたレビューです。 | |
| EmploymentAgency | 雇用 agency. | |
| Endocrine | 内分泌腺とその分泌物の障害の診断と治療に関わる医学の特定の分野。 | |
| EndorseAction | エージェントがオブジェクトを承認/認証/好き/サポート/承認する。 | |
| EndorsementRating | EndorsementRating は、ある程度の支持を示す評価であり、例えば「批評家の選択」ブログへの掲載や、ソーシャルネットワークでの「いいね!」や「+1」などが挙げられます。これは、ある agent によって object が肯定的に評価された EndorseAction の result と見なすことができます。schema.org の他の場所と同様に、このようなアクションの結果を Action を明示的に記述せずに説明する方が便利な場合があります。 EndorsementRating は、数値スケールまたは整理されたシステムの一部である可能性がありますが、必須ではありません。数値スケールがない場合に、肯定的な支持評価を示す明示的なタイプを持つことは、消費者が評価が概ね肯定的であることを理解するのに役立つため特に役立ちます。 |
|
| Energy | エネルギーを値として取るプロパティは、'<Number> <Energy unit of measure>' の形式です。 | |
| EnergyConsumptionDetails | EnergyConsumptionDetailsは、エネルギーを消費する製品のエネルギー効率に関する情報を示します。提供できる情報は、例えばEU指令2017/1369のようなエネルギー表示に関する国際的な規制や、米国におけるエネルギー政策・保全法(EPCA)に基づくエネルギー表示規則に基づいています。 | |
| EnergyEfficiencyEnumeration | いくつかの国際的なエネルギー効率基準に含まれる、エネルギー効率レベル(「クラス」または「評価」としても知られています)と認証を列挙します。 | |
| EnergyStarCertified | EnergyStar認証を表します。 | |
| EnergyStarEnergyEfficiencyEnumeration | EnergyStar認証を受けている製品かどうかを示すために使用されます。 | |
| EngineSpecification | 車両のエンジンに関する情報。車両は複数のエンジンを持つことができ、それらは複数のエンジン仕様エンティティによって表現されます。 | |
| EnrollingByInvitation | 招待制での参加者募集。 | |
| EntertainmentBusiness | 娯楽を提供するビジネス。 | |
| EntryPoint | Webベースのプロトコル内におけるエントリーポイント。 | |
| Enumeration | リストまたは列挙—たとえば、料理や音楽ジャンルのリストなど。 | |
| Episode | シリーズまたはシーズンの一部となりうるメディアのエピソード(例:テレビ、ラジオ、ビデオゲーム)。 | |
| Event | ある特定の時間と場所で開催されるイベント(コンサート、講演会、フェスティバルなど)。チケット情報はoffersプロパティを通じて追加できます。繰り返されるイベントは、個別のEventオブジェクトとして構造化できます。 | |
| EventAttendanceModeEnumeration | EventAttendanceModeEnumerationの値は、イベントを組織する可能性のある複数のモードのいずれかであり、オンラインかオフラインかに関係します。 | |
| EventCancelled | イベントはキャンセルされました。イベントに複数のstartDateの値がある場合、すべてキャンセルされたものとみなされます。startDateまたはpreviousStartDateのいずれかを使用して、イベントのキャンセル日を指定できます。 | |
| EventMovedOnline | イベントがオンライン参加に対応できるよう変更されました。現在のオンライン開催状況(完全オンラインか、部分的なオンラインか)については、eventAttendanceMode をご確認ください。 | |
| EventPostponed | イベントは延期され、新たな日付は設定されていません。イベントのpreviousStartDateを設定してください。 | |
| EventRescheduled | イベントは再スケジュールされました。イベントのpreviousStartDateは古い日付に設定し、startDateはイベントの新しい日付に設定してください。(イベントが複数回再スケジュールされた場合、previousStartDateプロパティが繰り返される場合があります。) | |
| EventReservation | コンサート、スポーツイベント、または講演会などのイベントの予約。 注:このタイプは、予約確認メールや個々の予約確認が記載されたHTMLページなど、実際の予約に関する情報用です。チケットのオファーについては、Offerを使用してください。 |
|
| EventScheduled | イベントは、予定通り startDate に開催されました、または開催されています。この値の使用は任意であり、デフォルトで想定されています。 | |
| EventSeries | 一連のEvent。含まれるイベントは、superEventプロパティを使用してシリーズに関連付けることができます。 EventSeriesは、何らかの共通の特徴を共有するイベントのコレクションです。例えば、「オリンピック競技大会」は定期的に繰り返されるシリーズです。「2012年ロンドンオリンピック」は、シリーズ「オリンピック競技大会」におけるEventとして、また、多数のスポーツ競技をイベントとして含んだEventSeriesとして提示できます。 EventSeries内のイベント間の関連性の性質は様々ですが、典型的な例としては、テーマのあるイベントシリーズ(例:特定の話題のミートアップやクラス)や、場所、参加者グループ、および/または主催者を共有する一連の定期的なイベントなどが挙げられます。 EventSeriesは、発行者がイベントのコンテキストで使用しやすく、どの種類のシリーズがイベントと呼ぶのに十分なイベントらしいかを心配せずに済むように、イベントの一種として定義されています。一般に、EventSeriesは、期間が短く、場所などの側面が固定されている場合に、よりイベントらしく見えますが、長期的なシリーズをイベントとして記述することが役立つ場合もあります。 |
|
| EventStatusType | EventStatusType は、Event が持つ可能性のある複数の状態を表す列挙型です。 | |
| EventVenue | イベント会場。 | |
| EvidenceLevelA | 複数のランダム化比較試験またはメタアナリシスから得られたデータ。 | |
| EvidenceLevelB | 単一のランダム化試験、または非ランダム化研究から得られたデータ。 | |
| EvidenceLevelC | 専門家の合意意見、症例研究、または標準治療のみ。 | |
| ExchangeRateSpecification | 為替レートを表す構造化された値。 | |
| ExchangeRefund | A ExchangeRefund ... | |
| ExerciseAction | 健康とフィットネスを改善することを目的とした、精力的な活動に参加する行為。 | |
| ExerciseGym | ジム。 | |
| ExercisePlan | 特定の健康関連の目的のために設計されたフィットネス関連の活動で、定義された運動ルーチンや臨床医によって処方された活動を含むもの。 | |
| ExhibitionEvent | イベントタイプ:展示イベント、例:博物館、図書館、公文書館、展示会、… | |
| Eye | 眼または眼科的機能評価と臨床検査。 | |
| FAQPage | FAQPage は、1つまたは複数の「よくある質問」を提示する WebPage です(QAPage も参照)。 | |
| FDAcategoryA | 米国FDAによる指定で、妊娠の第一三半期において胎児へのリスクが十分に制御された研究で証明されなかったことを意味し(後期三半期にリスクの証拠はない)。 | |
| FDAcategoryB | 米国FDAによる指定で、動物生殖研究で胎児へのリスクが示されず、妊娠中の女性における適切なかつ管理された研究が存在しないことを意味します。 | |
| FDAcategoryC | 米国FDAによる指定で、動物生殖研究で胎児に有害な影響が示されており、ヒトでの適切なかつ管理された研究がないものの、潜在的な利益が妊娠中の女性における薬剤の使用を潜在的なリスクにかかわらず正当化する可能性があることを意味します。 | |
| FDAcategoryD | 米国FDAによる指定で、調査または市販後の経験、またはヒトでの研究からの有害反応データに基づいてヒト胎児へのリスクの陽性証拠があることを示すものですが、潜在的なリスクにもかかわらず、妊娠中の女性における薬剤の使用が潜在的な利益によって正当化される可能性があります。 | |
| FDAcategoryX | 米国FDAによる指定で、動物またはヒトでの研究で胎児の異常が示された、および/または調査または市販後の経験からの有害反応データに基づいてヒトの胎児へのリスクの陽性証拠があり、妊娠中の女性における薬剤の使用に伴うリスクが潜在的な利益を明確に上回ることを意味します。 | |
| FDAnotEvaluated | 米国FDAによって、問題の薬剤に妊娠カテゴリー指定が割り当てられていないという指定。 | |
| FMRadioChannel | FMを使用するラジオチャンネル。 | |
| FailedActionStatus | 処理が完了に失敗しました。処理のエラープロパティとHTTPリターンコードには、失敗に関する詳細情報が含まれています。 | |
| False | ブール値のfalse。 | |
| FastFoodRestaurant | ファストフードレストラン。 | |
| Female | 女性の性別。 | |
| Festival | イベントタイプ: Festival. | |
| FilmAction | フィルム、ビデオ、またはデジタルで音と動画像を記録する行為。 | |
| FinancialProduct | 金融機関(銀行、保険会社、証券会社、消費者金融会社、投資会社など)が提供する金融サービス業界を構成する、消費者および企業向けの製品。 | |
| FinancialService | 金融サービス事業。 | |
| FindAction | 物体の発見行為。 関連するアクション:
|
|
| FireStation | 消防署。消防士と。 | |
| Flexibility | 関節と筋肉の柔軟性を向上させるために行われる身体活動。 | |
| Flight | 航空便。 | |
| FlightReservation | 航空旅行の予約。 注:これは実際の予約に関する情報用です(例:確認メールや個々の予約確認ページ)。チケットのオファーの場合は、Offerを使用してください。 |
|
| Float | データ型: 浮動小数点数。 | |
| FloorPlan | FloorPlan は、類似した宿泊施設の集合を明示的に表現するものであり、共通情報(部屋数、サイズ、レイアウト図)および賃貸または販売のオファーを提供することを可能にします。 通常の使用では、ある ApartmentComplex が accommodationFloorPlan を持ち、それは FloorPlan です。 FloorPlan は常に、より大きな ApartmentComplex または単一の Apartment の特定の場所の文脈にあります。 床計画の視覚的/空間的側面(すなわち、部屋のレイアウト、wikipedia を参照) は、image を使用して示すことができます。 | |
| Florist | 花屋。 | |
| FollowAction | 誰か/何か(オブジェクト)と一方的/非対称的に個人的な繋がりを築き、更新をポーリングすること。 関連アクション:
|
|
| FoodEstablishment | 食品関連のビジネス。 | |
| FoodEstablishmentReservation | 飲食店での予約。 注記:これは実際の予約に関する情報用です。例えば、確認メールや個々の予約確認ページなど。 |
|
| FoodEvent | イベントタイプ: Food event. | |
| FoodService | 朝食、昼食、夕食のような食品サービス。 | |
| FourWheelDriveConfiguration | 四輪駆動は、エンジンが主に2つの車輪を駆動し、パートタイムの四輪駆動機能を持つトランスミッションレイアウトです。 | |
| Friday | 木曜日と土曜日の間の曜日。 | |
| FrontWheelDriveConfiguration | フロントホイールドライブは、エンジンが前輪を駆動するトランスミッションのレイアウトです。 | |
| FullRefund | A FullRefund ... | |
| FundingAgency | 資金提供機関は、1つまたは複数のFundingSchemeを実施し、助成プロセス(通常はMonetaryGrantsであるGrantsを介して)を管理する組織です。
助成資金を得るために資金提供機関が常に必要というわけではありません。例えば、慈善寄付、企業スポンサーシップなどがあります。 資金提供機関の例としては、ERC、REA、NIH、ビル&メリンダ・ゲイツ財団などがあります。 |
|
| FundingScheme | 資金調達スキームは、助成金ベースの資金調達の組織的、プロジェクト的、政策的側面を組み合わせたものであり、 他の種類のプロジェクトや活動を支援するためのガイドライン、原則、メカニズムを設定します。 資金調達は通常、Grant 資金調達を通じて組織されます。資金調達スキームの例:スイス優先プログラム(SPP);EUフレームワーク7(FP7);Horizon 2020;NIH-R01助成金プログラム;ウェルカム機関戦略的支援基金。大規模な公共部門の資金調達の場合、助成金の管理と運営は、多くの場合、他の専用組織 - FundingAgency(ERC、REAなど)によって処理されます。 | |
| Fungus | 病原性真菌。 | |
| FurnitureStore | 家具店。 | |
| Game | ゲームのタイプは、ゲームを表すものです。これらは通常、ルールに基づいた娯楽活動であり、例えば、プレイヤーが架空の設定でキャラクターの役割を担うロールプレイングゲームなどがあります。 | |
| GamePlayMode | このゲームがマルチプレイヤー、協力プレイ、またはシングルプレイヤーであるかどうかを示します。 | |
| GameServer | マルチプレイヤーゲームにおけるゲームインタラクションを提供するサーバー。 | |
| GameServerStatus | ゲームサーバーの状況。 | |
| GardenStore | 庭園店。 | |
| GasStation | ガソリンスタンド。 | |
| Gastroenterologic | 消化器系の疾患の診断と治療に関わる医学の特定の分野。 | |
| GatedResidenceCommunity | 居住形態: ゲート付きコミュニティ。 | |
| GenderType | 性別の列挙。 | |
| GeneralContractor | 一般請負業者。 | |
| Genetic | 遺伝的特徴および疾患の遺伝的伝達と変異に関わる医学の一分野。 | |
| Genitourinary | 臨床検査による泌尿生殖器系機能評価。 | |
| GeoCircle | GeoCircleは、円形の地理的領域を表すGeoShapeです。GeoShapeであるため、単純なテキストプロパティ「circle」を提供しますが、geoRadiusと郵便番号(postalCode)の組み合わせも可能です。 円の中心は、「geoMidpoint」プロパティで示すか、または「address」、「postalCode」を使用してより概算で示すことができます。 | |
| GeoCoordinates | 場所またはイベントの地理座標。 | |
| GeoShape | 場所の地理的な形状。GeoShapeは、緯度/経度のペアに基づく値を持ついくつかのプロパティを使用して記述できます。緯度と経度を区切るには、空白またはカンマを使用できます。複数のポイントのリストを記述する場合は、空白を使用する必要があります。 | |
| GeospatialGeometry | (最終的に定義される) GeoShapeのスーパータイプで、Geo-Spatialのベストプラクティスからの定義に対応するように設計されています。 | |
| Geriatric | 高齢者の病気、虚弱、およびケアの診断と治療を扱う医学の特定の分野。 | |
| GettingAccessHealthAspect | 特定の種類の医療サービスへのアクセス(例えば、ワクチンの流通メカニズムなど)に関する実践的および政策的な側面を議論するコンテンツ。 | |
| GiveAction | オブジェクトの所有権を宛先へ移転する行為。TakeActionの逆操作。 関連アクション:
|
|
| GlutenFreeDiet | グルテンを含まない限定的な食事。 | |
| GolfCourse | ゴルフコース。 | |
| GovernmentBenefitsType | GovernmentBenefitsType は、COVID-19 の状況を支援するための様々な政府給付金を列挙します。この構造が提供されているすべての給付金を網羅しているわけではないことに注意してください。 | |
| GovernmentBuilding | 政府の建物。 | |
| GovernmentOffice | 政府機関—たとえば、IRSやDMVのオフィスなど。 | |
| GovernmentOrganization | 政府機関または代理店。 | |
| GovernmentPermit | 政府機関によって発行された許可証。 | |
| GovernmentService | 政府機関が提供するサービス、例:食料切手、退役軍人手当など。 | |
| Grant | 資源の助成金。通常は金銭的またはその他の定量的なものです。通常、funderがOrganizationまたはPersonにMonetaryAmountを助成し、
必ずしも専用または長期的なProjectを介してではなく、その結果、1つ以上の成果物またはfundedItemが生じます。金銭的な支援の場合、MonetaryGrantのfunderを示してください。金銭以外の支援の場合、資源(例えばオフィススペース)のGrantのsponsorを示してください。 助成金は、合意された共通の目標に向けた活動を支援します。しばしばProjectとして組織されますが、常にそうではありません。長期的なプロジェクトは、時間の経過とともにさまざまな助成金によって支援されることがありますが、プロジェクトが単一の助成金に関連付けられることもよくあります。 Grantの金額は、amountとしてMonetaryAmountで表されます。 |
|
| GraphicNovel | 書籍形式: GraphicNovel。ComicIssueインスタンスの束を表す場合があります。 | |
| GroceryStore | 食料品店。 | |
| GroupBoardingPolicy | 航空会社は、チェックイン時間、優先度などに基づいてグループごとに搭乗します。 | |
| Guide | Guide は、特定の製品またはサービス、あるいはある物事の側面をユーザーが検討するために推奨するページまたは記事です。Guide は、購入ガイドを表し、ユーザーが検討すべき製品またはサービスの側面を詳細に説明する場合があります。Guide は、製品ガイドを表し、特定の製品またはサービスを推奨する場合があります。Guide は、ランキング付きリストを表し、ランキング付きで特定の製品またはサービスを推奨する場合があります。 | |
| Gynecologic | 女性の健康、特に女性の生殖器系に影響を与える疾患の診断と治療に関わる医学の一分野。 | |
| HVACBusiness | 暖房、換気、空調サービスを提供するビジネス。 | |
| Hackathon | ハッカソンイベント。 | |
| HairSalon | 美容院。 | |
| HalalDiet | イスラム教の食事規定に準拠した食事。 | |
| Hardcover | 書籍の形式:ハードカバー。 | |
| HardwareStore | 金物店。 | |
| Head | 頭部評価と臨床検査。 | |
| HealthAndBeautyBusiness | 健康と美。 | |
| HealthAspectEnumeration | HealthAspectEnumeration は、オンラインの健康コンテンツのいくつかの側面を列挙するものであり、それぞれが hasHealthAspect と HealthTopicContent を使用して記述される可能性があります。 | |
| HealthCare | HealthCare: これは医療費の給付です。 | |
| HealthClub | 健康クラブ。 | |
| HealthInsurancePlan | PPO、EPO、HMOを含む、米国型の健康保険プラン。 | |
| HealthPlanCostSharingSpecification | ネットワークまたは処方箋に基づいて患者に発生する費用の説明。 | |
| HealthPlanFormulary | 特定の健康保険プランにおける、処方箋薬の費用と補償に関する仕様。 | |
| HealthPlanNetwork | 米国型健康保険プランネットワーク。 | |
| HealthTopicContent | HealthTopicContent は、何らかの健康トピック(例えば、病状、その症状、または治療法)に関する WebContent です。このようなコンテンツは、複数の部分やセクションで構成され、さまざまな種類のメディアを使用する場合があります。複数の WebContent (したがって HealthTopicContent) は、何らかのコンテンツ階層が存在する場合、hasPart / isPartOf を使用して関連付けることができ、その内容は about および mentions で記述されます。例えば、既存の MedicalCondition 語彙に基づいて構築されます。 | |
| HearingImpairedSupported | 聴覚障害のあるユーザーを支援するためにデバイスを使用します。 | |
| Hematologic | 血液および血液生成臓器の疾患の診断と治療に関わる医学の特定の分野。 | |
| HighSchool | 高校。 | |
| HinduDiet | ヒンドゥー教の食事習慣に準拠した食事、特に牛肉は含まない。 | |
| HinduTemple | ヒンドゥー教の寺院。 | |
| HobbyShop | 様々な趣味に役立つ、または必要な材料を販売するお店。 | |
| HomeAndConstructionBusiness | 建設業。 HomeAndConstructionBusinessは、住宅や建物に関するサービスを提供するLocalBusinessです。 LocalBusinessとして、1つ以上のService(s)のproviderとして記述できます。 |
|
| HomeGoodsStore | ホームグッズ店。 | |
| Homeopathic | 健康な人に同様の症状を引き起こす物質によって病気が治癒できるという原理に基づいた医学体系。 | |
| Hospital | 病院。 | |
| Hostel | ホステル - 安価な宿泊施設で、しばしば共同のドミトリー形式です。
ホテルやその他の宿泊施設をマークアップするためのschema.orgの使用に関する専用ドキュメントも参照してください。 |
|
| Hotel | ホテルは、短期の有料宿泊施設を提供する施設です(出典:Wikipedia, the free encyclopedia, 参照:http://en.wikipedia.org/wiki/Hotel)。
ホテルやその他の宿泊施設をマークアップするためのschema.orgの使用に関する専用ドキュメントも参照してください。 |
|
| HotelRoom | ホテルの客室は、ホテル内の一室です。
ホテルやその他の宿泊施設をマークアップするためのschema.orgの使用に関する専用ドキュメントも参照してください。 |
|
| House | 家屋とは、人間や他の生物が居住するために使用できる建物または構造物のことです(出典:Wikipedia、フリー百科事典、http://en.wikipedia.org/wiki/House)。 | |
| HousePainter | 家の塗装サービス。 | |
| HowItWorksHealthAspect | 特定の健康関連のトピックがどのように機能するか、例えばメカニズムや根底にある科学の観点から議論し説明するコンテンツ。 | |
| HowOrWhereHealthAspect | トピックを見つける方法や場所に関する情報。また、トピックが観察された場合に助けを求める場所として使用できる位置データも含まれる場合があります。 | |
| HowTo | 結果を達成するために一連のステップを実行する方法を説明する手順。 | |
| HowToDirection | 結果を達成するための指示における、単一の行動を示す方向性。 | |
| HowToItem | 結果を達成するための指示を実行する際に、道具または消耗品として使用されるアイテム。 | |
| HowToSection | 結果を達成するための指示におけるステップのサブグループ化(例:パイのレシピ内のパイ生地を作るためのステップ)。 | |
| HowToStep | 結果を達成するための指示におけるステップ。HowToDirectionおよび/またはHowToTip項目を含む順序付きリストです。 | |
| HowToSupply | 結果を達成するための指示を実行する際に消費される供給物。 | |
| HowToTip | 結果を達成するための手順の説明。テクニック、材料、著者の好みなどに関する補足情報を提供します。何ができるか、または何をしてはいけないかを説明できますが、何をすべきかを特定はしません(HowToDirectionを参照)。 | |
| HowToTool | 結果を達成するための指示を実行する際に使用される(しかし消費されない)道具。 | |
| HyperToc | HyperToc は、VideoObject や AudioObject などの複雑なメディアオブジェクトのハイパーテキスト目次を表します。目次内の項目は tocEntry プロパティで示され、型付きの HyperTocEntry となります。同じ大きな作品が複数のファイルに分割されている場合は、個々の HyperTocEntry 項目に associatedMedia を使用できます。 | |
| HyperTocEntry | HyperToEntryは、HyperToc内のアイテムであり、VideoObjectやAudioObjectのような複雑なメディアオブジェクトのハイパーテキスト目次を表します。メディアオブジェクト自体はassociatedMediaを使用して示されます。そのコンテンツ内の関心のある各セクションは、HyperTocEntryとともに、関連するstartOffsetとendOffsetで記述できます。複数のエントリがすべて同じファイルから来た場合、associatedMediaは包括的なHyperTocEntryで使用されます。コンテンツが複数のファイルに分割されている場合は、各HyperTocEntryのassociatedMediaを使用して参照できます。 | |
| IceCreamShop | アイスクリーム店。 | |
| IgnoreAction | 対象を意図的に無視する行為。エージェントは対象を無視します。 | |
| ImageGallery | Webページの種類: 画像ギャラリーページ。 | |
| ImageObject | 画像ファイル。 | |
| ImagingTest | 診断目的で一般的に使用されるあらゆる医用画像診断モダリティ。 | |
| InForce | 法律が施行中であることを示します。 | |
| InStock | 在庫ありを示します。 | |
| InStoreOnly | 実店舗のみでの取り扱いとなります。 | |
| IndividualProduct | 単一の識別可能な製品インスタンス(例:特定のシリアル番号を持つラップトップ)。 | |
| Infectious | 医学において、細菌、ウイルス、真菌、または寄生虫感染によって引き起こされる感染症に関連する何か。 | |
| InfectiousAgentClass | 感染症を媒介するエージェントまたは病原体のクラス。列挙型。 | |
| InfectiousDisease | 感染症とは、病原性のあるウイルス、細菌、真菌、原生動物、多細胞寄生虫、プリオンなどの病原性微生物の存在に起因する、臨床的に明らかになったヒトの疾患です。感染症とみなされるためには、そのような病原体がこの疾患を引き起こす可能性があることが知られている必要があります。 | |
| InformAction | 相手にとって関連のある情報を、返信を期待せずに通知する行為。 | |
| IngredientsHealthAspect | 健康トピックに関連する成分に関する議論。 | |
| InsertAction | 順序付けられたコレクションの特定の場所への追加行為。 | |
| InstallAction | アプリケーションのインストール行為。 | |
| Installment | 提供された製品の総価格に対する分割払い価格コンポーネントを表します。 | |
| InsuranceAgency | 保険代理店。 | |
| Intangible | 数量、構造化された値など、多くの「非実体的な」ものの傘となるユーティリティクラスです。 | |
| Integer | データ型: Integer. | |
| InteractAction | 別の人または組織との相互作用の行為。 | |
| InteractionCounter | このCreativeWorkに対するユーザーのインタラクションの概要です。ほとんどの場合、著者は特定のインタラクションの種類を指定するためにサブタイプを使用します。 | |
| InternationalTrial | 国際的な裁判。 | |
| InternetCafe | インターネットカフェ。 | |
| InvestmentFund | 複数の投資家から資金を集め、株式、債券、その他の資産に再投資する会社またはファンド。 | |
| InvestmentOrDeposit | クライアントが潜在的な金銭的利益を得る見込みと引き換えに、資金を金融サービスに移動させる必要がある金融商品の一種です。 | |
| InviteAction | イベントへの参加を依頼する行為。RsvpActionの逆。 | |
| Invoice | 商品またはサービスに対する支払額の明細書、請求書。 | |
| InvoicePrice | 提示された製品の請求価格を表します。 | |
| ItemAvailability | 考えられる製品の在庫オプションのリスト。 | |
| ItemList | あらゆる種類の項目のリスト—たとえば、Top 10 Movies About Weathermen、またはTop 100 Party Songsなどです。HTMLリストとは混同しないでください。HTMLリストは、多くの場合、フォーマット目的でのみ使用されます。 | |
| ItemListOrderAscending | 下位の値が最初にリストされる ItemList。 | |
| ItemListOrderDescending | 上位の値から順に並べられた ItemList。 | |
| ItemListOrderType | itemListOrder の値の列挙。順序付けられた ItemList がどのように構成されているかを示します。 | |
| ItemListUnordered | 明示的な順序なしで順序付けられたItemList。 | |
| ItemPage | 特定の製品やホテルなどの単一の項目に特化したページ。 | |
| JewelryStore | 宝飾品店。 | |
| JobPosting | 特定の組織における求人情報を記述した募集要項。 | |
| JoinAction | エージェントが、参加者/友人と共に、ある場所のイベント/グループに参加します。 関連アクション:
|
|
| Joint | 2つ以上の骨が接触する解剖学的部位。 | |
| KosherDiet | ユダヤ教の食事規定に準拠した食事。 | |
| LaboratoryScience | 化学的、血液学的、免疫学的、顕微鏡的、または細菌学的診断分析または研究に関する医学科学。 | |
| LakeBodyOfWater | 湖(例えば、Lake Pontrachain)。 | |
| Landform | 地形または物理的特徴。地形要素には、山、平野、湖、川、景観、湾、半島、海などの海洋水域界面の特徴、さらには水没した山脈、火山、および巨大な海洋盆地などの水中の地形的特徴が含まれます。 | |
| LandmarksOrHistoricalBuildings | 歴史的なランドマークまたは建物。 | |
| Language | スペイン語、タミル語、ヒンディー語、英語などの自然言語。alternateNameプロパティを介して、BCP 47で表現される正式な言語コードタグを使用できます。Language型は以前、SchemeやLispなどのプログラミング言語もカバーしていましたが、これらは現在ComputerLanguageを使用して表現するのが最適です。 | |
| LaserDiscFormat | LaserDiscFormat. | |
| LearningResource | LearningResource型は、学習、教育、スキル習得、その他の教育目的への特定の明確な指向性を持つCreativeWork(物理的またはデジタル)を示すために使用できます。 LearningResourceは、Book、VideoObject、Productなどの主要な型への追加として使用されることが想定されています。 EducationEventは、イベントのようなもの(例:Trip)に対して同様の目的を果たします。LearningResourceは、例えば記録することによって、EducationEventの結果として作成される場合があります。 |
|
| LeaveAction | エージェントが参加者/友人と共に、ある場所のイベント/グループを離れます。 関連アクション:
|
|
| LeftHandDriving | ステアリングの位置は、車両の左側です(主な進行方向から見て)。 | |
| LegalForceStatus | 法律の効力に関する可能なステータスのリスト。 | |
| LegalService | LegalServiceは、法律指向のサービス、助言、および代理を提供する事業であり、例えば法律事務所などです。 LocalBusinessとして、1つ以上のService(s)のproviderとして記述できます。 |
|
| LegalValueLevel | 法律の有効性に関する可能性のあるレベルのリスト。 | |
| Legislation | 法律文書(法律、政令、法案など、施行の有無にかかわらず)または法律行為の構成要素(条項など)。 | |
| LegislationObject | 法律を含む特定のオブジェクトまたはファイル。同じ法律が複数のファイルで公開される場合があることに注意してください。例えば、デジタル署名されたPDF、プレーンなPDF、およびHTMLバージョンなどです。 | |
| LegislativeBuilding | 立法府の建物—例えば、州議会議事堂。 | |
| LeisureTimeActivity | レクリエーションを目的としたあらゆる身体活動。例としては、ボールルームダンス、ローラースケート、カヌー、釣りなどがあります。 | |
| LendAction | 合意の下で、後日返却されることを条件として、ある物を提供する行為。BorrowActionの逆。 関連アクション:
|
|
| Library | 図書館。 | |
| LibrarySystem | LibrarySystem は、複数の図書館間の共同システムです。 | |
| LifestyleModification | 運動、食事の変化、フィットネスルーチン、および健康状態を改善することを目的としたその他のライフスタイルの変化を含むケアのプロセス。 | |
| Ligament | 複数の骨、軟骨を連結し、関節を構造的に支持する機能を持つ、短く、丈夫で、柔軟性のある線維性結合組織の帯。 | |
| LikeAction | 対象について肯定的な感情を表明する行為。主体が参加者と共に、対象(命題、話題、またはテーマ)を好む。 | |
| LimitedAvailability | 在庫が限られています。 | |
| LimitedByGuaranteeCharity | LimitedByGuaranteeCharity: 保証有限会社を指す非営利型(英国)。 | |
| LinkRole | Webリンクを表すRoleで、例えば 'url' プロパティで表現されます。その linkRelationship プロパティは、URLベースおよびプレーンテキストのリンクタイプ、例えばIANAリンクレジストリのものや 'amphtml' などのものを指し示すことができます。この構造は、HTMLのlink要素からの詳細をHTML外で表現するためのプレースホルダーを提供します。例えば、JSON-LDフィード内などです。 | |
| LiquorStore | ワイン、ビール、ウイスキー、その他のスピリッツなど、アルコール飲料を販売するお店。 | |
| ListItem | リスト項目、例えばチェックリストのステップやハウツーの説明。 | |
| ListPrice | 提示された製品の定価(製品が実際に宣伝されている価格)を表します。 | |
| ListenAction | オーディオコンテンツを消費する行為。 | |
| LiteraryEvent | イベントタイプ: 文学イベント。 | |
| LiveAlbum | LiveAlbum. | |
| LiveBlogPosting | 進行中のイベントを継続的な更新を通じて、リアルタイムなテキストによる報道を提供するブログ投稿。 | |
| LivingWithHealthAspect | トピックに関連する対処法や生活に関する情報。 | |
| LoanOrCredit | 合意された条件と手数料の下で、一定額の資金または信用枠を貸し出すための金融商品。 | |
| LocalBusiness | 特定の物理的なビジネスまたは組織の支店。LocalBusinessの例としては、レストラン、レストランチェーンの特定の支店、銀行の支店、診療所、クラブ、ボーリング場などがあります。 | |
| LocationFeatureSpecification | 宿泊施設の特性を、程度の異なるフォーマリティを持つプロパティと値のペアとして表現する構造化された値を提供することで、ロケーションフィーチャーを指定します。 | |
| LockerDelivery | ロッカーを通じて商品を受け取れる配送方法。 | |
| Locksmith | 鍵屋。 | |
| LodgingBusiness | モーテル、ホテル、旅館などの宿泊施設。 | |
| LodgingReservation | ホテル、モーテル、旅館などの宿泊予約 注記:これは、予約確認メールや個々の予約確認が記載されたHTMLページなど、実際の予約に関する情報用です。 |
|
| Longitudinal | 横断研究とは異なり、縦断研究は同じ人々を追跡するため、観察された違いが世代間の文化的差異によるものである可能性は低くなります。縦断研究は医学においても、特定の疾患の予測因子を明らかにするために使用されます。 | |
| LoseAction | 競争的な活動で敗北すること。 | |
| LowCalorieDiet | カロリー摂取量を減らすことに焦点を当てた食事。 | |
| LowFatDiet | 脂肪とコレステロールの摂取量を減らすことに重点を置いた食事。 | |
| LowLactoseDiet | 乳糖不耐症の人に適した食事。 | |
| LowSaltDiet | 減塩を意識した食事。 | |
| Lung | 肺および呼吸器系の臨床検査。 | |
| LymphaticVessel | 心臓へ単方向的にリンパ液を運ぶ特定の種類の血管。 | |
| MRI | 磁気共鳴画像法。 | |
| MSRP | 提供される製品のメーカー希望小売価格 ("MSRP") を表します。 | |
| Male | 男性の性別。 | |
| Manuscript | 手書きで書かれた本、文書、または音楽作品。タイプまたは印刷されたものではありません。 | |
| Map | 地図。 | |
| MapCategoryType | いくつかの種類のMapの列挙。 | |
| MarryAction | 人を結婚させる行為。 | |
| Mass | 質量を値として取るプロパティは、'<Number> <Mass unit of measure>' の形式です。例: '7 kg'。 | |
| MathSolver | 数学の問題のサブセットを解くことができる数学ソルバー。 | |
| MaximumDoseSchedule | 薬またはサプリメントに対して、当局または薬/サプリメントの製造元が推奨する、安全と見なされる最大投与スケジュール。推奨する当局を、MedicalEntityのrecognizingAuthorityプロパティに記録します。 | |
| MayTreatHealthAspect | 関連トピックは、Topicによって扱われる場合があります。 | |
| MeasurementTypeEnumeration | 一般的な測定タイプ(または寸法)の列挙。例えば、人の「chest」、ズボンの「inseam」、ネジの「gauge」、自転車の「wheel」など。 | |
| MediaGallery | Webページのタイプ:メディアギャラリーページ。画像、動画、その他のマルチメディアを含むことができる複合メディアページです。 | |
| MediaManipulationRatingEnumeration | mediaAuthenticityCategory プロパティで使用するためのコードで、メディアオブジェクトの真正性(公開または共有の状況における)を示します。一般にこれらのコードは相互に排他的ではありませんが、「オリジナル」と「変換済み」、「編集済み」、および「演出済み」のような組み合わせは、同じ MediaReview に適用されると矛盾する可能性があります。これらのコードの適用は、特定の状況で共有または公開されたメディアに対して行われることに注意してください。 | |
| MediaObject | ウェブページまたはダウンロード可能なデータセット(例:DataDownload)に埋め込まれた画像、ビデオ、またはオーディオオブジェクトなどのメディアオブジェクト。クリエイティブワークは、同じウェブページ上で多くのメディアオブジェクトと関連付けられる場合があります。たとえば、1つの楽曲(MusicRecording)に関するページには、ミュージックビデオ(VideoObject)と、高帯域幅および低帯域幅のオーディオストリーム(2 AudioObject's)が含まれる場合があります。 | |
| MediaReview | MediaReview は、オンラインのメディアコンテンツの評価に特化した、より専門的なレビュー形式であり、通常はファクトチェックや誤情報の文脈で使用されます。 より広範な意味でのメディアに関する一般的なレビューについては、UserReview、CriticReview、またはその他の Review タイプを使用してください。この定義は 現在進行中の作業です。MediaManipulationRatingEnumeration リストは、ファクトチェッカーや誤情報対策に取り組む人々による重要なコミュニティレビューを反映していますが、メディアオブジェクト、そのバージョン、および公開コンテキストを表現するための具体的な構造は、まだ進化中です。同様に、MediaReview と ClaimReview マークアップの関係に関するベストプラクティスは、まだ最終決定されていません。 | |
| MediaSubscription | オーディオ、ビデオ、書籍など、メディアにアクセスできるサブスクリプションです。 | |
| MedicalAudience | 医療ウェブページのターゲットオーディエンス。 | |
| MedicalAudienceType | 医療ウェブページに対するターゲットオーディエンスのタイプ。列挙型。 | |
| MedicalBusiness | 医療目的のための組織の特定の物理的または仮想的な事業。MedicalBusinessの例としては、医療従事者によって運営される異なる事業が含まれます。 | |
| MedicalCause | 医学的状態、症状、または徴候に至る病態生理学的プロセスに責任を持つ原因物質。このスキームでは、特に指定がない限り、これは医学的状態、症状、または徴候の直接的な原因を意味します。直接的な原因は、医学的状態、症状、または徴候に最も直接的につながる原因物質として定義されます。例えば、HIVウイルスはエイズの原因と見なすことができます。あるいは、診断の文脈において、患者が転倒して股骨骨折を起こし、2日後に肺塞栓症を起こし、それが心停止につながった場合、心停止の原因(直接的な原因)は肺塞栓症であり、転倒ではありません。医学的な原因には、心血管、化学、皮膚、内分泌、環境、消化器、遺伝、血液、婦人科、医原性、感染症、筋骨格、神経、栄養、産科、腫瘍、耳鼻咽喉科、薬理学、精神科、肺、腎臓、リウマチ、毒物、外傷、または泌尿器的原因が含まれます。医学的状態も原因となり得ます。 | |
| MedicalClinic | 病院や医学校に併設され、特定の診断および/または医療に特化した施設。以前は外来患者に限定されていましたが、進化とともに入院患者にも開放される場合があります。 | |
| MedicalCode | 医療エンティティのコード。 | |
| MedicalCondition | 人の正常な機能を、身体的または精神的に影響するあらゆる人体状態。病気、怪我、障害、疾患、症候群などを含む。 | |
| MedicalConditionStage | 「ステージIIIa」のような、病状の段階。 | |
| MedicalContraindication | 特定の医療治療を保留する理由となる状態または要因です。禁忌は、絶対禁忌(行動方針をとる合理的な状況がない)または相対的禁忌(患者が合併症のリスクが高いが、そのリスクが他の考慮事項によって上回るか、他の対策によって軽減される可能性がある)があります。 | |
| MedicalDevice | 患者の診断または治療のために使用されるあらゆる物体。 | |
| MedicalDevicePurpose | 医療機器のカテゴリーで、機器の目的または意図された使用法によって整理されています。 | |
| MedicalEntity | 健康と医学の実践に関連する最も一般的なタイプのエンティティ。 | |
| MedicalEnumeration | 健康および医学の実践に関連する列挙:医学の実践において、別の概念に品質を付与するため、修飾子、項目の集合、または集合のすべての要素のリストとして使用される概念。 | |
| MedicalEvidenceLevel | 医療ガイドラインの根拠レベル。列挙型。 | |
| MedicalGuideline | 標準的な学会(例:ACC/AHA)またはコンセンサスステートメントによって行われた、特定の疾患の診断と治療方法を示す推奨事項。注:このタイプは、実際のガイドライン推奨をタグ付けするために使用する必要があります。ガイドライン推奨がより大きな学術論文に記載されている場合は、このタイプではなく、MedicalScholarlyArticleを使用して全体の記事をタグ付けしてください。また、推奨事項を出している組織は、MedicalEntityのrecognizingAuthority基本プロパティでキャプチャする必要があります。 | |
| MedicalGuidelineContraindication | 有害性を指し示すガイドラインにおける禁忌であり、その禁忌を裏付けるデータの質が健全であること。 | |
| MedicalGuidelineRecommendation | 有効性が認められ、推奨を裏付けるデータの質が健全であるガイドラインの推奨。 | |
| MedicalImagingTechnique | 診断目的で一般的に使用されるあらゆる医用画像診断モダリティ。列挙型。 | |
| MedicalIndication | 医療治療の使用を示す状態または要因であり、兆候、症状、危険因子、解剖学的状態などが含まれます。 | |
| MedicalIntangible | 医療分野における多くの「形のない」ものに対する包括的なユーティリティクラスです。 | |
| MedicalObservationalStudy | 観察研究は、ある期間にわたって対象者集団を観察することにより、治療の可能性のある効果を推測しようとする医学研究の一種です。観察研究では、対象者を治療群または対照群に割り当てることは、研究者の管理外です。これは、MedicalTrialに代表されるランダム化比較試験のような対照研究とは対照的であり、対照研究では、治療開始前に各対象者がランダムに治療群または対照群に割り当てられます。 | |
| MedicalObservationalStudyDesign | 観測医療研究のための設計モデル。列挙型。 | |
| MedicalOrganization | 病院、施設、または診療所などの医療機関(物理的またはそうでない)。 | |
| MedicalProcedure | 診断、治療、予防、または緩和ケアのいずれかの目的で使用され、侵襲的(外科的)、非侵襲的、またはその他の技術に依存するケアのプロセス。 | |
| MedicalProcedureType | 医療処置の種類を記述する列挙型。 | |
| MedicalResearcher | 医学研究者。 | |
| MedicalRiskCalculator | 複雑な数学的計算であり、予後評価に使用されます。注:オンライン計算ツールのURLは、Thingのurlプロパティに記録してください。 | |
| MedicalRiskEstimator | 合併症や状態の発症リスクを評価するための、あらゆるルールセットまたはインタラクティブツール。 | |
| MedicalRiskFactor | リスク因子とは、人が病気、医学的状態、または合併症を発症または罹患する可能性を高めるあらゆるものです。 | |
| MedicalRiskScore | リスク因子の数を合計して、予後と関連付けられるスコアを算出する単純なシステム。例:CHADスコア、TIMIリスクスコア。 | |
| MedicalScholarlyArticle | 医学分野の学術論文。 | |
| MedicalSign | 客観的な診断検査または身体検査によって発見可能な、個人の病状の身体的現れ。 | |
| MedicalSignOrSymptom | 医学的状態に関連するかどうかに関わらず、あらゆる特徴。医学において、症状は一般的に主観的であり、徴候は客観的です。 | |
| MedicalSpecialty | 医学または診療の特定の分野。医学専門分野には、特定の臓器系とその関連する疾患状態に関連する臨床専門分野と、関連医療専門分野が含まれます。列挙型。 | |
| MedicalStudy | 医学研究は、観察研究、介入試験、レジストリ、ランダム化されたもの、またはそうでないものを含む、人間医学または健康に関連するあらゆる種類の研究研究を包括する包括的なタイプです。特定の研究タイプがわかっている場合は、MedicalTrialやMedicalObservationalStudyなどのこのタイプの拡張機能を使用してください。また、このタイプは研究自体を記述するデータをマークアップするために使用されるべきであり、研究の結果を掲載する記事をタグ付けするには、MedicalScholarlyArticleを使用することに注意してください。注:MedicalEntityのcodeプロパティを使用して、study IDs(例:clinicaltrials.gov ID)を保存してください。 | |
| MedicalStudyStatus | 医学研究のステータス。列挙型。 | |
| MedicalSymptom | 患者が自覚し、表現するあらゆる訴え(したがって主観的と定義される)例えば、腹痛、腰痛、または疲労など。 | |
| MedicalTest | 診断目的で通常行われる、あらゆる医学検査。 | |
| MedicalTestPanel | 一般的にまとめて注文されるテストのコレクションです。 | |
| MedicalTherapy | 人間疾患および医学的状態を予防、治療、および治癒するために設計されたあらゆる医学的介入であり、根治療法と緩和療法を含みます。医学的療法は通常、薬物療法、行動療法、支持療法(例えば、輸液や栄養)、または解毒療法(例えば、血液透析)に依存するケアのプロセスであり、健康状態の改善または予防を目的とします。 | |
| MedicalTrial | 医学試験は、医療療法または医療処置の安全性と有効性を比較するために使用される科学的プロセスを用いた医療研究の一種です。一般的に、医学試験は管理されており、被験者は異なる治療群および/または対照群にランダムに割り当てられます。 | |
| MedicalTrialDesign | 医療試験の設計モデル。列挙型。 | |
| MedicalWebPage | 医療情報を提供するウェブページ。 | |
| MedicineSystem | 医療実践のシステム。 | |
| MeetingRoom | 会議室、カンファレンスルーム、または会議ホールは、ビジネス会議やミーティングなどの単独のイベントのために設けられた部屋です(出典:Wikipedia, the free encyclopedia, 参照 http://en.wikipedia.org/wiki/Conference_hall)。
ホテルやその他の宿泊施設のマークアップに関するschema.orgの使用に関する専用ドキュメントも参照してください。 |
|
| MensClothingStore | メンズウェア店。 | |
| Menu | フードエスタブリッシュメントから提供される食品または飲料アイテムの構造化された表現。 | |
| MenuItem | メニューまたはメニューセクションに記載されている食品または飲料アイテム。 | |
| MenuSection | メニュー内の食品または飲料項目のサブグループ化。例:コース(「ディナー」、「朝食」など)、特定の料理の種類(「肉」、「ヴィーガン」、「ドリンク」など)、またはメニュー提供者によって行われたその他の分類。 | |
| MerchantReturnEnumeration | MerchantReturnEnumeration は、いくつかの製品返品ポリシーを列挙します。この構造がポリシーのすべての側面を網羅しているとは限りません。 | |
| MerchantReturnFiniteReturnWindow | MerchantReturnFiniteReturnWindow: 製品の返品には期限があります。 | |
| MerchantReturnNotPermitted | MerchantReturnNotPermitted: 製品の返品は許可されていません。 | |
| MerchantReturnPolicy | MerchantReturnPolicy は、Organization または Product に関連付けられた製品返品ポリシーに関する情報を提供します。 | |
| MerchantReturnUnlimitedWindow | MerchantReturnUnlimitedWindow: 製品返品に制限はありません。 | |
| MerchantReturnUnspecified | MerchantReturnUnspecified: 商品返品ポリシーがここに指定されていません。 | |
| Message | 送信者から1つまたは複数の組織または個人への単一のメッセージ。 | |
| MiddleSchool | 中学校(通常は11歳から14歳くらいの子供向けですが、多少ばらつきがあります)。 | |
| Midwifery | 妊娠、出産、産褥期(新生児のケアを含む)に加え、女性の生涯にわたる性と生殖に関する健康を扱う、看護師のような保健医療専門職。 | |
| MinimumAdvertisedPrice | 提供される製品のメーカーが定める最低販売価格 ("MAP") を表します。 | |
| MisconceptionsHealthAspect | あるトピックに関連する一般的な誤解や神話についてのコンテンツ。 | |
| MixedEventAttendanceMode | MixedEventAttendanceMode - オフラインとオンラインのモードを組み合わせた形式で開催されるイベント。 | |
| MixtapeAlbum | MixtapeAlbum. | |
| MobileApplication | 電話などのモバイルデバイスでうまく機能するように設計されたソフトウェアアプリケーション。 | |
| MobilePhoneStore | 携帯電話と関連アクセサリーを販売するお店。 | |
| Monday | 日曜日と火曜日の間の曜日。 | |
| MonetaryAmount | 金額または範囲。このタイプは、$50 USDのような金額や、銀行口座が£1,000から£1,000,000 GBPの残高に適している、または給与の価値などを記述するために使用できます。オファー、請求書などの価格を記述するには、PriceSpecificationタイプを使用することをお勧めします。 | |
| MonetaryAmountDistribution | 金額の統計的分布。 | |
| MonetaryGrant | 金銭的な助成金。 | |
| MoneyTransfer | お金をある場所から別の場所へ移動させる行為。これは電子的に、または物理的に発生する可能性があります。 | |
| MortgageLoan | 担保物件または不動産を担保とするローン。(何らかの不動産を担保とした証券化ローン。) | |
| Mosque | モスク。 | |
| Motel | モーテル。
ホテルやその他の宿泊施設をマークアップするためのschema.orgの使用に関する専用ドキュメントも参照してください。 |
|
| Motorcycle | オートバイまたはバイクは、単一の軌道を持つ二輪の自動車です。 | |
| MotorcycleDealer | オートバイ販売店。 | |
| MotorcycleRepair | オートバイ修理店。 | |
| MotorizedBicycle | モーター付き自転車は、車両を駆動するため、またはペダリングを支援するために取り付けられたモーターを備えた自転車です。 | |
| Mountain | 山、例えばマウント・ホイットニーやマウント・エベレストのような。 | |
| MoveAction | エージェントが場所へ移動する行為。 関連するアクション:
|
|
| Movie | 映画。 | |
| MovieClip | 映画の短いセグメント/部分。 | |
| MovieRentalStore | 映画レンタル店。 | |
| MovieSeries | 映画のシリーズです。含まれる映画は hasPart プロパティで示すことができます。 | |
| MovieTheater | 映画館。 | |
| MovingCompany | 引越し業者。 | |
| MultiCenterTrial | 多施設で行われる試験。 | |
| MultiPlayer | プレイモード:MultiPlayer。複数の人間プレイヤーが同時にプレイすることを要求または許可します。 | |
| MulticellularParasite | 感染症を引き起こす多細胞寄生虫。 | |
| Muscle | 筋肉は、動物が運動を起こすために使用する収縮性組織からなる解剖学的構造です。 | |
| Musculoskeletal | 筋肉、靭帯、および骨格系疾患の診断と治療に関わる医学の特定の分野。 | |
| MusculoskeletalExam | 筋骨格系臨床検査。 | |
| Museum | 博物館。 | |
| MusicAlbum | 音楽トラックのコレクション。 | |
| MusicAlbumProductionType | アルバムのコンテンツの種類による分類:サウンドトラック、ライブアルバム、スタジオアルバムなど。 | |
| MusicAlbumReleaseType | このアルバムのリリース形態:シングル、EP、またはアルバム。 | |
| MusicComposition | 楽曲。 | |
| MusicEvent | イベントタイプ: 音楽イベント。 | |
| MusicGroup | バンド、オーケストラ、合唱団などの音楽グループ。ソロミュージシャンも含まれます。 | |
| MusicPlaylist | プレイリスト形式の音楽トラックのコレクション。 | |
| MusicRecording | 通常、1つの曲である音楽録音(トラック)。 | |
| MusicRelease | MusicRelease は、音楽アルバムの特定のリリースです。 | |
| MusicReleaseFormatType | リリース形式(録音媒体の種類、例:コンパクトディスク、デジタルメディア、LPなど)。 | |
| MusicStore | 音楽店。 | |
| MusicVenue | 音楽会場。 | |
| MusicVideoObject | 音楽ビデオファイル。 | |
| NGO | 組織:非政府組織。 | |
| NLNonprofitType | NLNonprofitType: オランダ発祥の非営利団体タイプ。 | |
| NailSalon | ネイルサロン。 | |
| Neck | 臨床検査による頸部評価。 | |
| Nerve | 各軸索に沿って伝達される電気化学的神経インパルスの共通経路。 | |
| Neuro | 神経系の臨床検査。 | |
| Neurologic | 神経と神経系、およびそれに関連する疾患状態を研究する医学の特定の分野。 | |
| NewCondition | 新品であることを示します。 | |
| NewsArticle | NewsArticleは、ニュースを報道するコンテンツ、またはニュースを理解するための背景情報や補足資料を提供する記事です。 より詳細なschema.org Newsマークアップの概要も入手可能です。 |
|
| NewsMediaOrganization | 新聞やテレビ局などのニュース/メディア組織。 | |
| Newspaper | 一般情報、地理的領域、または特定の主題(例:ビジネス、文化、教育)に関連する多様なトピックに関する情報を含む出版物。多くの場合、毎日発行されます。 | |
| NightClub | ナイトクラブまたはディスコテーク。 | |
| NoninvasiveProcedure | 非侵襲的な技術を伴う医療処置の一種。 | |
| Nonprofit501a | Nonprofit501a: 農業協同組合を指す非営利型。 | |
| Nonprofit501c1 | Nonprofit501c1: 連邦議会法に基づいて組織された法人を指す非営利団体の一種で、連邦信用組合や全国農貸組合などが含まれます。 | |
| Nonprofit501c10 | Nonprofit501c10: 国内兄弟団体および協会を指す非営利団体タイプ。 | |
| Nonprofit501c11 | Nonprofit501c11: 教師退職金基金協会を指す非営利団体タイプ。 | |
| Nonprofit501c12 | Nonprofit501c12: 慈善生命保険協会、相互溝渠または灌漑会社、相互または協同電話会社を指す非営利団体タイプ。 | |
| Nonprofit501c13 | Nonprofit501c13: 墓地会社を指す非営利団体タイプ。 | |
| Nonprofit501c14 | Nonprofit501c14: 州立信用組合、相互準備基金を指す非営利団体タイプ。 | |
| Nonprofit501c15 | Nonprofit501c15: 相互保険会社または協会を指す非営利型。 | |
| Nonprofit501c16 | Nonprofit501c16: 農作物の運営資金を調達するための協同組合を指す非営利団体タイプ。 | |
| Nonprofit501c17 | Nonprofit501c17: 補充失業給付信託を指す非営利団体タイプ。 | |
| Nonprofit501c18 | Nonprofit501c18: 従業員拠出年金信託(1959年6月25日以前に設立)を指す非営利団体タイプ。 | |
| Nonprofit501c19 | Nonprofit501c19: Armed Forcesの過去または現在のメンバーのPostまたはOrganizationを指す非営利団体タイプ。 | |
| Nonprofit501c2 | Nonprofit501c2: 免税組織のための所有権保持会社を指す非営利型。 | |
| Nonprofit501c20 | Nonprofit501c20: グループ法的サービスプラン組織を指す非営利型。 | |
| Nonprofit501c21 | Nonprofit501c21: ブラックラング給付信託を指す非営利団体タイプ。 | |
| Nonprofit501c22 | Nonprofit501c22: 引き出し責任支払い基金を指す非営利型。 | |
| Nonprofit501c23 | Nonprofit501c23: 退役軍人団体を指す非営利型。 | |
| Nonprofit501c24 | Nonprofit501c24: Section 4049 ERISA信託を指す非営利団体タイプ。 | |
| Nonprofit501c25 | Nonprofit501c25: 不動産所有会社または複数の親会社を持つ信託を指す非営利団体タイプ。 | |
| Nonprofit501c26 | Nonprofit501c26: 高リスクの個人に健康保険を提供する州が支援する組織を指す非営利団体タイプ。 | |
| Nonprofit501c27 | Nonprofit501c27: 州が支援する労災保険再保険機関を指す非営利団体タイプ。 | |
| Nonprofit501c28 | Nonprofit501c28: 全国鉄道退職金投資信託を指す非営利団体タイプ。 | |
| Nonprofit501c3 | Nonprofit501c3: 宗教、教育、慈善、科学、文学、公共の安全のための試験、国内または国際的なアマチュアスポーツ競技の育成、または児童または動物への虐待防止を目的とする組織を指す非営利団体タイプ。 | |
| Nonprofit501c4 | Nonprofit501c4: 市民リーグ、社会福祉団体、従業員の地方組織を指す非営利団体タイプ。 | |
| Nonprofit501c5 | Nonprofit501c5: 労働、農業、園芸団体を指す非営利団体タイプ。 | |
| Nonprofit501c6 | Nonprofit501c6: ビジネスリーグ、商工会議所、不動産協会などを指す非営利団体タイプ。 | |
| Nonprofit501c7 | Nonprofit501c7: 社会的およびレクリエーションクラブを指す非営利団体タイプ。 | |
| Nonprofit501c8 | Nonprofit501c8: 兄弟互助団体および協会を指す非営利型。 | |
| Nonprofit501c9 | Nonprofit501c9: 任意従業員給付組合を指す非営利型。 | |
| Nonprofit501d | Nonprofit501d: 宗教的および使徒的協会を指す非営利団体タイプ。 | |
| Nonprofit501e | Nonprofit501e: 協同病院サービス機関を指す非営利型。 | |
| Nonprofit501f | Nonprofit501f: 協同組合サービス機関を指す非営利型。 | |
| Nonprofit501k | Nonprofit501k: Child Care Organizationsを指す非営利型。 | |
| Nonprofit501n | Nonprofit501n: 慈善リスクプールを指す非営利型。 | |
| Nonprofit501q | Nonprofit501q: クレジットカウンセリング機関を指す非営利団体タイプ。 | |
| Nonprofit527 | Nonprofit527: 政治団体を指す非営利型。 | |
| NonprofitANBI | NonprofitANBI: 公益団体(NL)を指す非営利団体タイプ。 | |
| NonprofitSBBI | NonprofitSBBI: 社会的利益を促進する機関(NL)を指す非営利型。 | |
| NonprofitType | NonprofitType は、非営利団体がなりうる公式な非営利団体の種類を列挙します。 | |
| Nose | 臨床検査による鼻機能評価。 | |
| NotInForce | 法案が現在施行されていないことを示します。 | |
| NotYetRecruiting | まだ募集していません。 | |
| Notary | 公証人。 | |
| NoteDigitalDocument | 作者向けに主に書かれたメモを含むファイル。 | |
| Number | データ型: Number. 使用ガイドライン:
|
|
| Nursing | 正式な教育を受け、病気または虚弱な人のケアにおける訓練を受けた人の健康専門職。 | |
| NutritionInformation | レシピの栄養情報。 | |
| OTC | 医薬品などの医療品が、処方箋なしで店頭で入手可能かどうかという性質。 | |
| Observation | クラス Observation のインスタンスは、特定の時点でエンティティ(StatisticalPopulation のインスタンスである場合も、そうでない場合もあります)に関する観察を指定するために使用されます。Observation の主なプロパティは、observedNode、measuredProperty、measuredValue(または median など)および observationDate です(measuredProperty プロパティは、W3C RDF Data Cube の「measure properties」である場合もあれば、そうでない場合もあります。例:lifeExpectancy)。 詳細については、StatisticalPopulation および データとデータセット の概要も参照してください。 | |
| Observational | 観察研究デザイン。 | |
| Obstetric | 妊娠中および産後の女性のケア、そして子供の出産を専門とする医学の一分野。 | |
| Occupation | 職業は、長期間の訓練や/または正式な資格を必要とする場合があります。 | |
| OccupationalActivity | 職務遂行のために行われるあらゆる身体活動。例としては、ウェイター業務、メイドサービス、郵便物を運ぶこと、果物や野菜の収穫、建設作業などが挙げられます。 | |
| OccupationalExperienceRequirements | 雇用関連の経験要件を示します。例:monthsOfExperience。 | |
| OccupationalTherapy | 身体的、感情的、または社会的な問題を抱える人々を、目的を持った活動を用いて、彼らの問題を克服したり、それに対処することを学んだりする治療法。 | |
| OceanBodyOfWater | 海(例えば、太平洋)。 | |
| Offer | 何らかの権利の譲渡やサービスの提供の申し出 — 例えば、イベントのチケット販売、映画のDVDレンタル、インターネット経由のテレビ番組ストリーミング、オートバイの修理、または本の貸し出しなど。 businessFunctionプロパティ(申し出の形態を識別するもの。例:販売、リース、修理、処分)は、デフォルトでhttp://purl.org/goodrelations/v1#Sellとなります。したがって、定義されたbusinessFunction値を持たないOfferは、販売の申し出と見なすことができます。 GTIN関連フィールドについては、チェックデジット計算機および検証ガイド(GS1より)を参照してください。 |
|
| OfferCatalog | OfferCatalog は、同じプロバイダーによって提供される関連するオファーおよび/またはさらなる OfferCatalog を含む ItemList です。 | |
| OfferForLease | Schema.org の OfferForLease は、何かを賃貸する Offer、つまり businessFunction が 賃貸 である Offer を表します。背景については、Good Relations を参照してください。 | |
| OfferForPurchase | Schema.org の OfferForPurchase は、何かを販売するための Offer、つまり businessFunction が sell である Offer を表します。背景については、Good Relations を参照してください。 | |
| OfferItemCondition | アイテムの考えられる状態のリスト。 | |
| OfferShippingDetails | OfferShippingDetails は配送先に関する情報を示します。 これらのエンティティの複数を使用することで、異なる配送先に対して異なる送料を設定できます: アラスカ/ハワイ向けのエンティティを1つ。本土アメリカ向けの別のエンティティ。フランス全土向けの別のエンティティ。 これらのエンティティの複数を使用することで、異なる送料と配達時間を表現できます。 料金と時間のみが異なる同一のエンティティを2つ: 例:安価で遅い:5ドルで5~7日 または 高速で高価:1~2日で15ドル。 |
|
| OfficeEquipmentStore | オフィス機器店。 | |
| OfficialLegalValue | 公式の出版社によって発行されたすべての文書は、少なくとも法的価値レベル「OfficialLegalValue」を持つ必要があります。これは、その文書が、それを公開する公的な任務を負う組織によって発行されたことを示します(例:EU出版局によって発行されたEU指令の統合版)。 | |
| OfflineEventAttendanceMode | オフラインイベント参加モード - 主にオフラインで実施されるイベント。 | |
| OfflinePermanently | ゲームサーバーの状態:OfflinePermanently。サーバーはオフラインであり、利用できません。 | |
| OfflineTemporarily | ゲームサーバーの状態:オフライン一時的。サーバーは現在オフラインですが、まもなくオンラインになる可能性があります。 | |
| OnDemandEvent | 番組をオンデマンドで利用できる、キャッチアップTVやラジオポッドキャストなどの配信イベント。 | |
| OnSitePickup | 現地で商品を受け取る配送方法。例えば、店舗や引換場所など。 | |
| Oncologic | 腫瘍学は、良性および悪性腫瘍を扱う医学の一分野であり、それらの発生、診断、治療、および予防の研究を含みます。 | |
| OneTimePayments | OneTimePayments: これは個人に対する一回限りの支払いに対する特典です。 | |
| Online | ゲームサーバーの状態:オンライン。サーバーは利用可能です。 | |
| OnlineEventAttendanceMode | OnlineEventAttendanceMode - 主にオンラインで開催されるイベント。 | |
| OnlineFull | ゲームサーバーの状態:OnlineFull。サーバーはオンラインですが、利用できません。最大プレイヤー数に達しました。 | |
| OnlineOnly | オンラインでのみ購入可能な商品であることを示します。 | |
| OpenTrial | 研究者が治療の全詳細を知っており、患者も同様に知っている試験デザイン。 | |
| OpeningHoursSpecification | 場所または場所内の特定のサービスの営業時間に関する情報を提供する構造化された値。 場所は、opensプロパティが指定されている場合は営業中、そうでない場合は休業となります。 closesプロパティの値がopensプロパティの値よりも小さい場合、時間範囲は翌日にまたがると想定されます。 |
|
| OpinionNewsArticle | OpinionNewsArticle は、ニュースや出来事のジャーナリストによる報道というよりも、主に意見を表明する NewsArticle です。例えば、ニュース出版物の意見欄にあるコラムや Blog/BlogPosting エントリーで構成される NewsArticle です。 | |
| Optician | 視力を改善するための老眼鏡や類似のデバイスを販売する店。 | |
| Optometric | 視力検査の科学または実践と、矯正レンズの処方。 | |
| Order | 注文は取引の確認(領収書)であり、顧客が受け入れたOfferによって表される複数の明細項目を含むことができます。 | |
| OrderAction | エージェントがオブジェクト/製品/サービスを配送/送付するよう注文します。 | |
| OrderCancelled | 注文のキャンセルを表す OrderStatus。 | |
| OrderDelivered | 注文の正常な配達を表す OrderStatus。 | |
| OrderInTransit | 輸送中の注文を表す OrderStatus。 | |
| OrderItem | 注文明細は注文の1行です。購入したオファーの数量と配送の詳細を含みます。 | |
| OrderPaymentDue | 注文に対する支払い期日が来たことを示すOrderStatus。 | |
| OrderPickupAvailable | OrderStatus は、注文の引き取り可能性を表します。 | |
| OrderProblem | 注文に問題があることを示すOrderStatus。 | |
| OrderProcessing | 処理中の注文を表す OrderStatus。 | |
| OrderReturned | 返品された注文を表す OrderStatus。 | |
| OrderStatus | Order の列挙型ステータス値。 | |
| Organization | 学校、NGO、企業、クラブなど、そのような組織。 | |
| OrganizationRole | 組織内の役割を記述するために使用されるRoleのサブクラス。 | |
| OrganizeAction | 1つ以上のオブジェクトの操作/管理/監督/制御を行う行為。 | |
| OriginalMediaContent | MediaReviewで「オリジナルメディアコンテンツ」としてコード化され、公開または共有された状況を考慮したもの。 VideoObjectが「オリジナル」であるためには:映像が誤解を招くように改変または操作された証拠がないこと。ただし、虚偽または誤解を招く主張が含まれていても構いません。 ImageObjectが「オリジナル」であるためには:画像が誤解を招くように改変または操作された証拠がないこと。ただし、虚偽または誤解を招く主張が含まれていても構いません。 埋め込みテキストを持つImageObjectが「オリジナル」であるためには:画像が誤解を招くように改変または操作された証拠がないこと。ただし、虚偽または誤解を招く主張が含まれていても構いません。 AudioObjectが「オリジナル」であるためには:音声が誤解を招くように改変または操作された証拠がないこと。ただし、虚偽または誤解を招く主張が含まれていても構いません。 |
|
| OriginalShippingFees | OriginalShippingFees ... | |
| Osteopathic | 自己治癒力を促進することに焦点を当てた医学体系。 | |
| Otolaryngologic | 耳、鼻、喉およびそれらのそれぞれの疾患状態を扱う医学の特定の分野。 | |
| OutOfStock | 在庫切れであることを示します。 | |
| OutletStore | アウトレットストア。 | |
| OverviewHealthAspect | コンテンツの概要。導入に最も関連性の高い情報を含む、トピックの要約されたビューです。 | |
| OwnershipInfo | 特定の組織または個人が特定の製品を所有していた時期に関する情報を提供する構造化された値。 | |
| PET | 陽電子放出断層撮影。 | |
| PaidLeave | 有給休暇: これは有給休暇の福利厚生です。 | |
| PaintAction | 絵画を制作する行為で、通常は絵の具とキャンバスを道具として用いる。 | |
| Painting | 絵画。 | |
| PalliativeProcedure | 症状を緩和することを主な目的とした、基礎疾患の症状を緩和するための医療処置。 | |
| Paperback | 書籍の形式:ペーパーバック。 | |
| ParcelDelivery | 郵便サービスまたは商業サービスによる荷物の配達。 | |
| ParcelService | 特定のオファーで利用可能な配送モードとしての民間宅配サービス。 一般的に使用される値:
|
|
| ParentAudience | 親の特性のセットで、特定のコンテンツの閲覧に興味を持つ可能性があります。 | |
| ParentalSupport | ParentalSupport: これは育児支援のための給付金です。 | |
| Park | 公園。 | |
| ParkingFacility | 駐車場またはその他の駐車施設。 | |
| ParkingMap | 駐車場の地図。 | |
| PartiallyInForce | 法律の一部が施行されており、一部は施行されていないことを示します。 | |
| Pathology | 疾患の状態の原因、起源、および性質を研究する医学の特定の分野であり、その疾患の発現の結果として生じる影響も含まれます。臨床現場においては、この用語は、検査を用いて病気を診断し、その予後意義を判断する医学の分野を指します。 | |
| PathologyTest | 病理検査所で行われる医療検査で、通常は病理医による組織サンプルの検査を伴います。 | |
| Patient | 患者は、医療サービスを受けるすべての人物です。 | |
| PatientExperienceHealthAspect | 患者または同様の経験を持つ人々の実体験に関するコンテンツ。フォーラム、トピック、Q&Aおよび関連資料などが含まれる場合があります。 | |
| PawnShop | 個人所有物を買い取ったり、担保にお金を貸したりする店。 | |
| PayAction | エージェントは参加者に対して価格を支払います。 | |
| PaymentAutomaticallyApplied | 自動引き落としシステムが導入されており、利用されます。 | |
| PaymentCard | クレジットカード、デビットカード、ストアカード、またはその他のカードを使用して、支払いとアカウントを関連付ける支払い方法。 | |
| PaymentChargeSpecification | 特定の支払い方法を使用して支払いを決済する費用。 | |
| PaymentComplete | お支払いが確認され、処理されました。 | |
| PaymentDeclined | 支払先は支払いを受け取りましたが、何らかの理由で却下されました。 | |
| PaymentDue | お支払いが期日ですが、まだ受け取り可能な猶予期間内です。 | |
| PaymentMethod | 支払い方法は、購入金額を移転するための標準化された手順です。支払い方法は、使用される法的および技術的構造と、取引を実行する組織またはグループによって特徴付けられます。 一般的に使用される値:
|
|
| PaymentPastDue | お支払いが期限切れとなっております。 | |
| PaymentService | 個人または組織から受取人である個人または組織へ資金を送金するサービス。 | |
| PaymentStatusType | 特定の支払いステータス。例えば、PaymentDue、PaymentCompleteなど。 | |
| Pediatric | 乳児、小児、および青年を専門とする医学の一分野。 | |
| PeopleAudience | アイテムのターゲットオーディエンスを構成する人々など、特徴の集合。 | |
| PercutaneousProcedure | 皮膚への針刺しによる経皮的介入を伴う医療処置の一種で、臓器または組織へのアクセスを達成します。例えば、ステント留置などのカテーテルを用いた処置です。 | |
| PerformAction | パフォーマンスアートへの参加行為。 | |
| PerformanceRole | PerformanceRoleは、あるエンティティが映画、TVシリーズなど、演劇的パフォーマンスに関して担うRoleです。 | |
| PerformingArtsTheater | 劇場またはその他の舞台芸術センター。 | |
| PerformingGroup | バンド、オーケストラ、サーカスなどのパフォーマンスグループ。 | |
| Periodical | 連続的に発行される連番または年代順の標題を持つ、雑誌、学術雑誌、新聞など、永続的に継続することを意図した、あらゆる媒体での出版物。 関連項目 ブログ投稿。 |
|
| Permit | 組織によって発行される許可証、例えば、{parking pass}など。 | |
| Person | 生きている人、死んだ人、アンデッド、または架空の人物。 | |
| PetStore | ペットショップ。 | |
| Pharmacy | 薬局またはドラッグストア。 | |
| PharmacySpecialty | 薬剤および医薬品の調製と調剤の実践、または芸術と科学。 | |
| Photograph | 写真。 | |
| PhotographAction | カメラを使って物体を静止画として捉える行為。 | |
| PhysicalActivity | 身体の適性および全体的な健康とウェルネスを向上または維持するあらゆる身体活動。日常生活およびルーチンの一部である活動、構造化された運動、および医療治療または回復計画の一部として処方された運動が含まれます。 | |
| PhysicalActivityCategory | 生理学的分類による身体活動のカテゴリー。 | |
| PhysicalExam | 医師が患者に対して行う身体検査の一種。 | |
| PhysicalTherapy | 健康状態を改善することを目的とした、段階的な身体的ケアとリハビリテーションのプロセス。 | |
| Physician | 医者のオフィス。 | |
| Physiotherapy | 病気、怪我、または変形を、薬や手術ではなく、マッサージ、熱療法、運動などの物理的な方法で治療する実践。 | |
| Place | ある程度固定された物理的な広がりを持つエンティティ。 | |
| PlaceOfWorship | 教会、シナゴーグ、モスクなどの礼拝の場所。 | |
| PlaceboControlledTrial | プラセボ対照試験デザイン。 | |
| PlanAction | イベント/タスク/アクション/予約/計画を将来の日付に実行するための計画を立てる行為。 | |
| PlasticSurgery | 手動および器械的な手段による、欠損、損傷、または奇形のある組織または身体部位の治療的または美容的な修復または再形成に関わる、医学の一分野。 | |
| Play | 戯曲は文学の一形態であり、通常は登場人物間の対話で構成され、単なる読書ではなく、演劇的な公演を意図しています。戯曲の公演はTheaterEvent - Play がworkPerformedとなります。 | |
| PlayAction | 楽しみ、レジャー、娯楽、競争、または運動のために、遊ぶ/運動する/訓練する/演奏する行為。 関連するアクション:
|
|
| Playground | 遊び場。 | |
| Plumber | 配管サービス。 | |
| PodcastEpisode | ポッドキャストシリーズの単一のエピソード。 | |
| PodcastSeason | ポッドキャストの単一のシーズン。多くのポッドキャストは個別のシーズンに分割されません。その場合は、PodcastSeriesを使用する必要があります。 | |
| PodcastSeries | ポッドキャストは、ユーザーがダウンロードして聴くことができるデジタル音声またはビデオファイルの連続したシリーズです。 | |
| Podiatric | 足病医学は、人間の足のケアであり、特に足の障害の診断と治療を扱います。 | |
| PoliceStation | 警察署。 | |
| Pond | 池。 | |
| PostOffice | 郵便局。 | |
| PostalAddress | 郵送先住所。 | |
| PostalCodeRangeSpecification | 郵便番号の範囲を示します。通常は、postalCodeBeginからpostalCodeEndまでの有効なコードの集合として定義され、両端の値を含みます。 | |
| Poster | 広く、通常は印刷された掲示、請求書、または告知で、多くはイラスト付きであり、何かを宣伝または広報するために掲示されるもの。 | |
| PotentialActionStatus | サポートされているアクションの説明。 | |
| PreOrder | 予約受付中です。 | |
| PreOrderAction | エージェントが、(まだリリースされていない)オブジェクト/製品/サービスを配送/送信するよう注文します。 | |
| PreSale | 一般発売前に注文と配送が可能なアイテムであることを示します。 | |
| PregnancyHealthAspect | 妊娠に関連する健康トピックに関する内容。 | |
| PrependAction | 順序付けられたコレクションの先頭に挿入する行為。 | |
| Preschool | 幼稚園。 | |
| PrescriptionOnly | 処方箋が必要な製品です。 | |
| PresentationDigitalDocument | スライドが含まれているファイル、またはプレゼンテーションに使用されるファイル。 | |
| PreventionHealthAspect | トピックまたはトピックに関連する重大な状況に陥るのを避けるために講じることができる行動または措置に関する情報。 | |
| PreventionIndication | 基礎疾患、症状など、を予防するための指標。 | |
| PriceComponentTypeEnumeration | 提供された製品の合計価格を構成するさまざまな価格要素を列挙します。 | |
| PriceSpecification | 価格または価格範囲を表す構造化された値です。通常、このタイプのサブクラスのみがマークアップに使用されます。給与、クレジットカードの限度額など、独立した金額を記述するには、MonetaryAmountを使用することをお勧めします。 | |
| PriceTypeEnumeration | リスト価格、請求価格、販売価格など、異なる価格タイプを列挙します。 | |
| PrimaryCare | 患者が医療システムに最初に接触する医師、またはその他の医療従事者による医療、および必要に応じて専門医を紹介する可能性。 | |
| Prion | プリオンは、ミスフォールドした形態のタンパク質から構成される感染性因子です。 | |
| Product | 提供されるあらゆる製品またはサービス。例えば:靴一足;コンサートチケット;レンタカー;ヘアカット;またはオンラインで配信されるテレビ番組の一話。 | |
| ProductCollection | 製品のセット(ProductGroupまたは特定のバリアント)で、例えばOffer内でまとめてリストされているもの。 | |
| ProductGroup | ProductGroupは、size、color、materialなど、特定の明確な方法でのみ異なるProductのグループを表します。 ProductGroup自体は直接販売されませんが、それが表す様々なバリエーション製品は販売可能です。ProductGroupはプロトタイプまたはテンプレートとして機能し、isVariantOfの関係を持つすべての製品を代表します。そのため、特性を(非常に多数の)バリアント間で共有するために、プロパティ(追加のタイプを含む)をProductGroupに適用できます。ProductGroupを参照するプロパティはこのメカニズムに含まれません。また、以下の特定のプロパティvariesBy、hasVariant、urlも含まれません。 |
|
| ProductModel | 製品のデータシートまたはベンダー仕様(プロトタイプ的な記述の意味で)。 | |
| ProfessionalService | プロフェッショナルサービスの提供者です。 ローカルビジネス向けの一般的なProfessionalServiceタイプは、Serviceとの混同を避けるため非推奨となりました。参考として、これに含まれていたタイプは次のとおりです:Dentist、 AccountingService、Attorney、Notary、およびいくつかのHomeAndConstructionBusinessのタイプ:Electrician、GeneralContractor、 HousePainter、Locksmith、Plumber、RoofingContractor。LegalServiceは、Attorneyをより包括的に包含する上位タイプとして導入されました。 |
|
| ProfilePage | Web ページの種類: プロフィールページ。 | |
| PrognosisHealthAspect | トピックの人生課程における典型的な進行と出来事。 | |
| ProgramMembership | ロイヤリティプログラム(例:「StarAliance」)、旅行者クラブ(例:「AAA」)、購入クラブ(「Safeway Club」など)の会員資格などを記述するために使用されます。 | |
| Project | 特定の目的を達成するために計画された企業(個人である可能性もありますが、通常は共同で行われます)。 Organization、subOrganization/parentOrganization のプロパティを使用して、プロジェクトのサブ構造を示します。 | |
| PronounceableText | データ型: PronounceableText。 | |
| Property | 何かの属性と関係性を示すために使用されるプロパティ。rdf:Propertyと同等。 | |
| PropertyValue | プロパティと値のペアで、例えば製品または場所の機能を表現します。プロパティの名前には'name'プロパティを使用してください。値の追加の人間が読めるバージョンがある場合は、それを'description'プロパティに入力してください。 常に、a) それが存在し、b) 値を埋めることができる場合は、特定のschema.orgプロパティを使用してください。PropertyValueを代用として使用しても、元の特定のプロパティを使用した場合と同じ効果が得られないことがよくあります。 |
|
| PropertyValueSpecification | プロパティ値の仕様。 | |
| Protozoa | 感染症を引き起こす単細胞生物。 | |
| Psychiatric | 医学的および心理療法を用いた、精神疾患の研究、治療、および予防を扱う医学の一分野。 | |
| PsychologicalTreatment | カウンセリング、対話、コミュニケーションを基盤とするケアのプロセスで、薬物を使用せずに精神的な健康状態を改善することを目的とします。 | |
| PublicHealth | 地域社会の健康を改善し保護するための保健サービスに関わる医学の分野。特に、疫学、衛生、免疫、予防医学などが含まれます。 | |
| PublicHolidays | これは、祝日となるあらゆる日を表します。特定の場所のすべての公式な祝日のプレースホルダーです。技術的には「曜日」ではありませんが、OpeningHoursSpecificationで使用できます。開館時間仕様の文脈では、祝日の開館時間を示すために使用でき、祝日が発生する曜日の一般的な開館時間を上書きします。 | |
| PublicSwimmingPool | 公共のスイミングプール。 | |
| PublicToilet | 公衆トイレは、一般の人々、または特定の企業のお客様や従業員が利用できる、1つ以上のトイレ(および場合によっては小便器)を含む部屋または小さな建物です。 | |
| PublicationEvent | PublicationEvent は、あらゆる種類の CreativeWork の出版イベント、例えば放送イベント、オンデマンドイベント、様々な配信メディアを通じた書籍/ジャーナル出版に無差別に対応します。 | |
| PublicationIssue | 雑誌や書籍などの連続刊行物の一部で、通常は番号が付けられ、記事などの作品のまとまりを含むもの。 関連項目:ブログ記事。 |
|
| PublicationVolume | 定期刊行物や複数巻の作品など、連続して出版されるものの一部で、通常は番号が付けられています。年などの期間を表すこともあります。 関連項目: ブログ記事。 |
|
| Pulmonary | 呼吸器系およびその関連疾患を研究する医学の特定の分野。 | |
| QAPage | QAPageは、特定の質問とその回答に焦点を当てたWebPageであり、例えば質問応答サイトやよくある質問(FAQ)のドキュメントなどで使用されます。 | |
| QualitativeValue | 製品特性の定義済みの値。例えば、電源コードプラグタイプ「US」や、衣料品のサイズ「S」、「M」、「L」、および「XL」など。 | |
| QuantitativeValue | 製品特性やその他の目的のためのポイント値または間隔。 | |
| QuantitativeValueDistribution | 値の統計的分布。 | |
| Quantity | 距離、時間、質量、重さなどの量。例えば質量の具体的な例としては、「3 Kg」や「4ミリグラム」のようなものが挙げられます。 | |
| Question | 特定の質問 - 例えば、オンラインで回答を求めているユーザーからのもの、またはよくある質問(FAQ)ドキュメントで収集されたもの。 | |
| Quiz | クイズ:知識、スキル、能力のテスト。 | |
| Quotation | 引用。しばしば、しかし必ずしもではないが、何らかの書物からのもので、現実世界の著者、そして(架空のキャラクターに関連付けられている場合)架空の人物に帰せられる。ソース/起源へのリンクにはisBasedOnを使用する。Eventからの引用を参照するには、recordedInプロパティを使用できる。 | |
| QuoteAction | エージェントが、ある場所/店舗で、ある物/製品/サービスに価格を提示/見積もり/評価します。 | |
| RVPark | 「レクリエーショナルビークル」、キャラバン、移動住宅などのためのスペースを提供する場所。 | |
| RadiationTherapy | 健康状態を改善することを目的とした放射線を利用したケアのプロセス。 | |
| RadioBroadcastService | 放送またはオンラインを通じてラジオコンテンツを提供する配信サービス。 | |
| RadioChannel | CableOrSatelliteServiceのラインナップにおける、ラジオBroadcastServiceのユニークなインスタンス。 | |
| RadioClip | 短いラジオ番組、またはラジオ番組のセグメント/部分。 | |
| RadioEpisode | シリーズまたはシーズンの一部となりうるラジオのエピソード。 | |
| RadioSeason | ラジオ放送と関連するオンライン配信に特化したシーズン。 | |
| RadioSeries | ラジオ放送および関連するオンライン配信に特化したCreativeWorkSeries。 | |
| RadioStation | ラジオ局。 | |
| Radiography | 放射線撮影は、可視光以外の電磁放射線、特にX線を使用して、人体のような不均一で不透明な物体の内部構造を観察する画像技術です。 | |
| RandomizedTrial | ランダム化比較試験デザイン。 | |
| Rating | 評価は、1つから5つ星のような数値スケールでの評価です。 | |
| ReactAction | 対象に対して本能的かつ感情的に反応し、感情を表現する行為。 | |
| ReadAction | 書かれたコンテンツを消費する行為。 | |
| ReadPermission | ドキュメントの読み取りまたは表示権限。 | |
| RealEstateAgent | 不動産エージェント。 | |
| RealEstateListing | RealEstateListing は、1つ以上の不動産 Offer を説明するリスティングであり(その businessFunction は通常、賃貸または販売です)。 RealEstateListing タイプ自体は、何らかの WebPage に現れる、全体的なリスティングを表します。 | |
| RearWheelDriveConfiguration | 後輪駆動は、エンジンが後輪を駆動するトランスミッションのレイアウトです。 | |
| ReceiveAction | 起源から宛先へ移送されたオブジェクトを物理的または電子的に受け取る行為。SendActionの逆操作。 関連アクション:
|
|
| Recipe | レシピ。レシピでカバーされる食事制限については、いくつかの一般的な制限がsuitableForDietを通じて列挙されています。keywordsプロパティを使用して、さらに詳細を追加することもできます。 | |
| Recommendation | Recommendationは、最良の選択肢または最良の行動方針として何かを提案または提案するタイプのReviewです。レコメンデーションは、製品やサービス、またはランキングリストや製品ガイドの場合のような具体的なものを対象とすることがあります。Guideは、異なるカテゴリに対して複数のレコメンデーションをリストアップすることがあります。例えば、どのテレビを購入するかについてのGuideでは、著者がいくつかのRecommendationを持っている可能性があります。 | |
| RecommendedDoseSchedule | 薬またはサプリメントの、権威ある機関または薬/サプリメントの製造元によって処方または推奨される推奨投与スケジュール。推奨機関をMedicalEntityのrecognizingAuthorityプロパティにキャプチャします。 | |
| Recruiting | 参加者募集。 | |
| RecyclingCenter | リサイクルセンター。 | |
| RefundTypeEnumeration | RefundTypeEnumeration は、いくつかの製品返品の払い戻しタイプを列挙します。 | |
| RefurbishedCondition | 商品が整備済み品であることを示します。 | |
| RegisterAction | The act of registering to be a user of a service, product or web page. Related actions:
|
|
| Registry | レジストリベースの研究デザイン。 | |
| ReimbursementCap | 薬剤の費用は、保険会社が薬剤に対して支払う最大の払い戻し額を表します。 | |
| RejectAction | オブジェクトを拒否または採用する行為。 関連するアクション:
|
|
| RelatedTopicsHealthAspect | メインのトピックに関連するその他の著名な、または関連性のあるトピック。 | |
| RemixAlbum | RemixAlbum. | |
| Renal | 腎臓およびその関連疾患を研究する医学の一分野。 | |
| RentAction | 物品(車両や不動産など)の所有権を伴わず、一時的な使用の対価として金銭を支払う行為。例えば、エージェントは、定期的な支払いと引き換えに、家主から不動産を賃貸します。 | |
| RentalCarReservation | レンタカーの予約。 注:これは実際の予約に関する情報用です。例えば、確認メールや個々の予約確認ページなど。 |
|
| RentalVehicleUsage | 車両がレンタカーとして使用されていることを示します。 | |
| RepaymentSpecification | 返済を表す構造化された値。 | |
| ReplaceAction | 受信者を古いオブジェクトを新しいオブジェクトに置き換えることで編集する行為。 | |
| ReplyAction | 対象オブジェクトから尋ねられた/送信された質問/メッセージに応答する行為。AskAction に関連します。 関連アクション:
|
|
| Report | 政府または非政府機関によって生成されたレポート。 | |
| ReportageNewsArticle | ReportageNewsArticle タイプは、ジャーナリスティックな報道慣習の結果として作成されたニュース記事を表す NewsArticle のサブタイプです。 実際には、多くのニュース発行者はさまざまな種類の記事を制作しており、その多くは NewsArticle と見なされるかもしれませんが、ReportageNewsArticle ではありません。例えば、意見記事、レビュー、分析、スポンサー付きまたは風刺的な記事、またはこれらの要素を組み合わせた記事などです。 ReportageNewsArticle タイプは、ジャーナリズム作品としての「ニュース」に対するより厳格な理想に基づいています。記事は、著者が観察または検証した事実情報、または知識のある情報源から報告および検証された情報に基づいています。これには、特定の問題に関する複数の視点からの意見が含まれることがよくあります(報道記事と広報またはプロパガンダを区別します)。ReportageNewsArticle の意味での報道記事は、著者の意見を軽視し、解説や価値判断は通常、他の場所で表現されます。 より詳細な分析を行う ReportageNewsArticle は、追加のタイプである AnalysisNewsArticle でもマークできます。 |
|
| ReportedDoseSchedule | 薬剤またはサプリメントの患者申告または観察された投与スケジュール。 | |
| ResearchProject | 研究プロジェクト。 | |
| Researcher | 研究者たち。 | |
| Reservation | 旅行、食事、またはイベントの予約について説明します。一部の予約にはチケットが必要です。 注:このタイプは、予約確認メールや個々の予約確認ページなど、実際の予約に関する情報用です。チケットのオファー、レストランの予約、フライト、またはレンタカーの場合は、Offerを使用してください。 |
|
| ReservationCancelled | 以前に確認済みの予約がキャンセルされた状態。 | |
| ReservationConfirmed | 確認済みの予約のステータス。 | |
| ReservationHold | 予約が保留されており、クレジットカード番号やフライトの変更などの更新を待っている状態。 | |
| ReservationPackage | 共通の値を持つすべてのサブ予約を持つ、複数の予約のグループ。 | |
| ReservationPending | リクエストは送信されたが、確認されていない予約のステータス。 | |
| ReservationStatusType | Reservation の列挙型ステータス値。 | |
| ReserveAction | 具体的なオブジェクトの予約。 関連アクション:
|
|
| Reservoir | 貯水池、通常はカルバ貯水池のような人工的に作られた湖。 | |
| Residence | 人が住む場所。 | |
| Resort | リゾートとは、リラックスやレクリエーションのために利用される場所で、休日や休暇で観光客を引きつけます。リゾートは、場所、町、または単一の会社によって運営される商業施設であることがあります(出典:Wikipedia, the free encyclopedia, 参照 http://en.wikipedia.org/wiki/Resort)。
ホテルやその他の宿泊施設をマークアップするためのschema.orgの使用に関する専用ドキュメントも参照してください。 |
|
| RespiratoryTherapy | 呼吸機能の維持または改善を目的とする治療法(肺疾患患者などにおいて)。 | |
| Restaurant | レストラン。 | |
| RestockingFees | RestockingFees … | |
| RestrictedDiet | 文化的、宗教的、健康、またはライフスタイル上の理由により、特定の食品や調理法を制限した食事。 | |
| ResultsAvailable | 結果は利用可能です。 | |
| ResultsNotAvailable | 結果は利用できません。 | |
| ResumeAction | 一時停止されていたデバイスまたはアプリケーションを再開する行為(例:音楽再生を再開する、またはタイマーを再開する)。 | |
| Retail | この薬の費用は、薬の小売価格を表します。 | |
| ReturnAction | 以前に受け取った(具体的な物)または取得した(所有権)ものを、元の状態に戻す行為。 | |
| ReturnFeesEnumeration | ReturnFeesEnumeration は返品手数料のポリシーを表現します。 | |
| ReturnShippingFees | 返品送料... | |
| Review | レストラン、映画、またはお店など、ある品物についてのレビュー。 | |
| ReviewAction | 対象物について、聴衆に対してバランスの取れた意見を表明する行為。エージェントが参加者と共に対象物をレビューし、レビューが生成されます。 | |
| ReviewNewsArticle | NewsArticleとCriticReviewで、サービス、製品、パフォーマンス、または芸術的または文学的作品に対する専門家の批評家の評価を提供するものです。 | |
| Rheumatologic | 関節リウマチ、自己免疫疾患、または関節疾患の研究と治療を扱う医学の特定の分野。 | |
| RightHandDriving | ステアリングの位置は、車両の右側です(主な進行方向から見て)。 | |
| RisksOrComplicationsHealthAspect | トピックに続く可能性のあるリスク要因と合併症に関する情報。 | |
| RiverBodyOfWater | 川(例えば、広大で雄大なShannon川)。 | |
| Role | 関係またはプロパティに関する追加情報を示します。例えば、Roleを使用して、あるSportsTeamと選手を結びつける「member」の役割が特定の期間に発生したと表現できます。あるいは、あるPersonのMovieにおける「actor」の役割が、特定のcharacterNameのためであったと表現できます。このようなプロパティはRoleエンティティに付加され、その後、通常のプロパティ(「member」や「actor」など)を使用して、主要なエンティティと関連付けられます。 こちらもご覧ください ブログ投稿。 |
|
| RoofingContractor | 屋根工事請負業者。 | |
| Room | 部屋は、構造物内の識別可能な空間であり、通常は内壁によって他の空間から区切られています。(出典:Wikipedia、フリー百科事典、http://en.wikipedia.org/wiki/Room)。
ホテルやその他の宿泊施設をマークアップするためのschema.orgの使用に関する専用ドキュメントも参照してください。 |
|
| RsvpAction | イベントへの参加予定の有無をイベント主催者に通知する行為。 | |
| RsvpResponseMaybe | 招待された人は、出席するかもしれないし、しないかもしれない。 | |
| RsvpResponseNo | 招待者は参加しません。 | |
| RsvpResponseType | RsvpResponseType は、RSVP リクエストに応答することを表すインスタンスを持つ列挙型です。 | |
| RsvpResponseYes | 招待された人は参加します。 | |
| SRP | 提供される製品の推奨小売価格(「SRP」)を表します。 | |
| SafetyHealthAspect | 健康トピックの安全性に関する情報。 | |
| SaleEvent | イベントタイプ: Sales event. | |
| SalePrice | 提供されている製品の販売価格(通常、期間限定で有効)を表します。 | |
| SatireOrParodyContent | MediaReview内で「風刺またはコンテンツ」とコード化され、それが公開または共有された状況を考慮したもの。 VideoObjectが「風刺またはパロディコンテンツ」であるためには:政治的またはユーモラスな解説として作成され、その文脈で提示された動画。(関連する文脈を含まない風刺/パロディコンテンツの再共有は、「文脈の欠如」評価に該当する可能性が高くなります。) ImageObjectが「風刺またはパロディコンテンツ」であるためには:政治的またはユーモラスな解説として作成され、その文脈で提示された画像。(関連する文脈を含まない風刺/パロディコンテンツの再共有は、「文脈の欠如」評価に該当する可能性が高くなります。) テキストが埋め込まれたImageObjectが「風刺またはパロディコンテンツ」であるためには:政治的またはユーモラスな解説として作成され、その文脈で提示された画像。(関連する文脈を含まない風刺/パロディコンテンツの再共有は、「文脈の欠如」評価に該当する可能性が高くなります。) AudioObjectが「風刺またはパロディコンテンツ」であるためには:政治的またはユーモラスな解説として作成され、その文脈で提示された音声。(関連する文脈を含まない風刺/パロディコンテンツの再共有は、「文脈の欠如」評価に該当する可能性が高くなります。) |
|
| SatiricalArticle | Article の内容は主に [風刺的] な性質を持ち、つまり文字通り真実である可能性が低いものです。風刺記事は、必ずしもそうではありませんが、NewsArticle であることもあります。ScholarlyArticle も風刺の対象となることがあります。 | |
| Saturday | 金曜日と日曜日の中間の曜日。 | |
| Schedule | スケジュールは、定期的に発生するEventを記述するために使用される繰り返し時間間隔を定義します。 最小限、スケジュールは、イベントの発生間隔を記述するrepeatFrequencyを指定します。 スケジュールをより正確に指定するために、追加情報を提供できます。 これには、イベントが再発する曜日または月日の特定、および開始時間と終了時間が含まれます。 スケジュールには、開始日と終了日を設定して、有効期間を示すこともできます。たとえば、イベントの限られたカレンダーを定義する場合などです。 | |
| ScheduleAction | 将来のアクション、イベント、またはタスクのスケジュール設定。 関連アクション:
|
|
| ScholarlyArticle | 学術論文。 | |
| School | 学校。 | |
| SchoolDistrict | 学校区は、学校の運営を行うための行政区域です。 | |
| ScreeningEvent | 映画または他のビデオの上映。 | |
| ScreeningHealthAspect | トピックをスクリーニングまたはさらにフィルタリングする方法に関するコンテンツ。 | |
| Sculpture | 彫刻作品。 | |
| SeaBodyOfWater | 海(例えば、カスピ海)。 | |
| SearchAction | 物体の探索行為。 関連するアクション:
|
|
| SearchResultsPage | Webページの種類: 検索結果ページ。 | |
| Season | メディアシーズン、例:テレビ、ラジオ、ビデオゲームなど。 | |
| Seat | イベント予約における指定席など、座席を説明するために使用されます。 | |
| SeatingMap | 座席表。 | |
| SeeDoctorHealthAspect | 質問される可能性のある情報、専門家を受診する時期、医師の診察を受ける前の対策、または最初の診察に関する内容。 | |
| SeekToAction | これは、特定のVideoObject内のstartOffsetタイムスタンプにナビゲートするActionであり、通常はURLテンプレート構造で表現されます。 | |
| SelfCareHealthAspect | 心を落ち着かせたり、健康を維持したり、ある話題を避けたりするために取れる自己ケアの行動や対策。これは自宅で行うことができ、本人自身で実施/管理することができます。 | |
| SelfStorage | トランクルーム。 | |
| SellAction | 商品またはサービスに対して買い手からお金を受け取る行為。エージェントは、ある価格で買い手にオブジェクト、製品、またはサービスを販売します。BuyActionの逆。 | |
| SendAction | ある物体を起点から宛先へ物理的または電子的に送る行為。関連アクション:
|
|
| Series | schema.org のシリーズは、関連する項目のグループであり、通常は同じ種類の項目ですが、必ずしもそうである必要はありません。CreativeWorkSeries、EventSeries も参照してください。 | |
| Service | 組織が提供するサービス、例:配送サービス、印刷サービスなど。 | |
| ServiceChannel | サービスにアクセスするための手段、例えば、政府機関の所在地、ウェブサイト、または電話番号。 | |
| ShareAction | 人々の娯楽または啓発のためにコンテンツを配布する行為。 | |
| SheetMusic | 楽譜、演奏または録音された音楽とは対照的に。 | |
| ShippingDeliveryTime | ShippingDeliveryTime は、配送の配送時間に関する様々な情報を提供します。 | |
| ShippingRateSettings | ShippingRateSettings は、再利用可能な配送情報のまとまりを表します。これは、OfferShippingDetails の shippingSettingsLink プロパティを介して参照される可能性のある URL での公開を目的としています。複数のインスタンスを公開し、それらの shippingLabel の異なる値によって区別および照合(つまり、識別/参照)できます。 | |
| ShoeStore | 靴屋。 | |
| ShoppingCenter | ショッピングセンターまたはモール。 | |
| ShortStory | 短編小説または物語。通常、物語形式の散文で書かれた短い文学作品。 | |
| SideEffectsHealthAspect | トピックの使用から観察される可能性のある副作用。 | |
| SingleBlindedTrial | 研究者が患者にランダムに割り当てられた治療法を知っているが、患者自身は知らない試験デザイン。 | |
| SingleCenterTrial | 単一施設で実施される試験。 | |
| SingleFamilyResidence | 住宅の種類: 一戸建て。 | |
| SinglePlayer | プレイモード:SinglePlayer。これは単独のプレイヤーによってプレイされます。 | |
| SingleRelease | SingleRelease. | |
| SiteNavigationElement | ページのナビゲーション要素。 | |
| SizeGroupEnumeration | 様々な製品カテゴリの一般的なサイズグループを列挙します。 | |
| SizeSpecification | 製品のサイズに関連するプロパティで、通常はサイズコード(name)と、オプションでsizeSystem、sizeGroup、および製品の測定値(hasMeasurement)が含まれます。さらに、suggestedAge、suggestedGender、および推奨される身体測定値(suggestedMeasurement)を通じて、対象ユーザーを定義できます。 | |
| SizeSystemEnumeration | さまざまな製品カテゴリの一般的なサイズシステムを列挙します。例えば、ウェアラブルの場合は「EN-13402」または「UK」、ネジの場合は「Imperial」などです。 | |
| SizeSystemImperial | インペリアル制度。 | |
| SizeSystemMetric | メートル法。 | |
| SkiResort | スキーリゾート。 | |
| Skin | 臨床検査による皮膚評価。 | |
| SocialEvent | イベントタイプ: Social event. | |
| SocialMediaPosting | ブログ投稿、ツイート、Facebook投稿など、ソーシャルメディアプラットフォームへの投稿。 | |
| SoftwareApplication | ソフトウェアアプリケーション。 | |
| SoftwareSourceCode | コンピュータプログラミングのソースコード。例:完全(コンパイル可能)な解答、コードスニペットのサンプル、スクリプト、テンプレート。 | |
| SoldOut | 品切れであることを示します。 | |
| SolveMathAction | 数式を受け取り、その数式を解いたり簡略化したりできる可能性のあるページへユーザーを誘導するアクション。 | |
| SomeProducts | 同じ種類の複数の類似製品のプレースホルダー。 | |
| SoundtrackAlbum | サウンドトラックアルバム。 | |
| SpeakableSpecification | SpeakableSpecification は、ドキュメントの xpath または cssSelector を介して、特に speakable と強調表示されるセクションを示します。このタイプのインスタンスは、主に speakable プロパティの値として使用されることが想定されています。 | |
| SpecialAnnouncement | A SpecialAnnouncement combines a simple date-stamped textual information update
with contextualized Web links and other structured data. It represents an information update made by a
locally-oriented organization, for example schools, pharmacies, healthcare providers, community groups, police,
local government. For work in progress guidelines on Coronavirus-related markup see this doc. The motivating scenario for SpecialAnnouncement is the Coronavirus pandemic, and the initial vocabulary is oriented to this urgent situation. Schema.org expect to improve the markup iteratively as it is deployed and as feedback emerges from use. In addition to our usual Github entry, feedback comments can also be provided in this document. While this schema is designed to communicate urgent crisis-related information, it is not the same as an emergency warning technology like CAP, although there may be overlaps. The intent is to cover the kinds of everyday practical information being posted to existing websites during an emergency situation. Several kinds of information can be provided: We encourage the provision of "name", "text", "datePosted", "expires" (if appropriate), "category" and "url" as a simple baseline. It is important to provide a value for "category" where possible, most ideally as a well known URL from Wikipedia or Wikidata. In the case of the 2019-2020 Coronavirus pandemic, this should be "https://en.wikipedia.org/w/index.php?title=2019-20_coronavirus_pandemic" or "https://www.wikidata.org/wiki/Q81068910". For many of the possible properties, values can either be simple links or an inline description, depending on whether a summary is available. For a link, provide just the URL of the appropriate page as the property's value. For an inline description, use a WebContent type, and provide the url as a property of that, alongside at least a simple "text" summary of the page. It is unlikely that a single SpecialAnnouncement will need all of the possible properties simultaneously. We expect that in many cases the page referenced might contain more specialized structured data, e.g. contact info, openingHours, Event, FAQPage etc. By linking to those pages from a SpecialAnnouncement you can help make it clearer that the events are related to the situation (e.g. Coronavirus) indicated by the category property of the SpecialAnnouncement. Many SpecialAnnouncements will relate to particular regions and to identifiable local organizations. Use spatialCoverage for the region, and announcementLocation to indicate specific LocalBusinesses and CivicStructures. If the announcement affects both a particular region and a specific location (for example, a library closure that serves an entire region), use both spatialCoverage and announcementLocation. The about property can be used to indicate entities that are the focus of the announcement. We now recommend using about only for representing non-location entities (e.g. a Course or a RadioStation). For places, use announcementLocation and spatialCoverage. Consumers of this markup should be aware that the initial design encouraged the use of /about for locations too. The basic content of SpecialAnnouncement is similar to that of an RSS or Atom feed. For publishers without such feeds, basic feed-like information can be shared by posting SpecialAnnouncement updates in a page, e.g. using JSON-LD. For sites with Atom/RSS functionality, you can point to a feed with the webFeed property. This can be a simple URL, or an inline DataFeed object, with encodingFormat providing media type information e.g. "application/rss+xml" or "application/atom+xml". [TRANSLATION ERROR - ORIGINAL KEPT] |
|
| Specialty | 人々が通常、かなりの学習、時間、および努力の後に特定の専門知識を開発する分野のあらゆる分野。 | |
| SpeechPathology | 吃音、構音障害、または幼児語のような発話の欠陥、障害、機能不全、および失語症や言語発達の遅れのような言語障害の科学的研究と治療。 | |
| SpokenWordAlbum | SpokenWordAlbum. | |
| SportingGoodsStore | スポーツ用品店。 | |
| SportsActivityLocation | 競技場のようなスポーツ施設。 | |
| SportsClub | スポーツクラブ。 | |
| SportsEvent | イベントタイプ: スポーツイベント。 | |
| SportsOrganization | スポーツチーム、統括団体、スポーツ協会など、すべてのスポーツ組織のコレクションを表します。 | |
| SportsTeam | 組織: スポーツチーム。 | |
| SpreadsheetDigitalDocument | スプレッドシートファイル。 | |
| StadiumOrArena | スタジアム。 | |
| StagedContent | MediaReview 内で「staged content」とコード化され、公開または共有された状況を考慮したコンテンツ。 VideoObject が「staged content」であるためには:俳優や同様に作為的な手法を用いて作成された動画。 ImageObject が「staged content」であるためには:俳優や同様に作為的な手法を用いて作成された画像。例えば、偽のツイートのスクリーンショットなど。 埋め込みテキストを持つ ImageObject が「staged content」であるためには:俳優や同様に作為的な手法を用いて作成された画像。例えば、偽のツイートのスクリーンショットなど。 AudioObject が「staged content」であるためには:俳優や同様に作為的な手法を用いて作成された音声。 |
|
| StagesHealthAspect | トピックから観察できる段階。 | |
| State | 国の州または県。 | |
| StatisticalPopulation | StatisticalPopulationは、特定の制約を満たす、ある特定の型のインスタンスの集合です。型を指定するには、populationTypeプロパティを使用します。その型のインスタンスで使用できる任意のプロパティは、統計的集団に現れる可能性があります。たとえば、カリフォルニア州イーストポダンクにhomeLocationを持つすべてのPersonを表すStatisticalPopulationは、その人々の集合を表すStatisticalPopulationアイテムに適切なhomeLocationとpopulationTypeプロパティを適用することで記述されます。 numConstraintsとconstrainingPropertyのプロパティは、集団のプロパティのどれが集団を指定するために使用されるかを指定するために使用されます。ここで使用されている「集団」の意味は、統計的集団の一般的な意味であり、集団が人々で構成されることを意味するものではありません。たとえば、EventまたはNewsArticleのpopulationTypeを使用できます。Observationおよびデータとデータセットの概要も参照してください。 | |
| StatusEnumeration | ステータスタイプを扱うリストまたは列挙型。 | |
| SteeringPositionValue | 操舵位置を示す値。 | |
| Store | 小売商品店。 | |
| StoreCreditRefund | StoreCreditRefund ... | |
| StrengthTraining | 筋力と骨の強度を向上させるために行われる身体活動。レジスタンス・トレーニングとも呼ばれます。 | |
| StructuredValue | 構造化された値は、プロパティの値が単なるテキスト値や別のものへの参照よりも複雑な構造を持つ場合に使用されます。 | |
| StudioAlbum | StudioAlbum. | |
| SubscribeAction | 誰か/何か(オブジェクト)と個人的な繋がりを一方的に/非対称的に形成し、更新をプッシュしてもらう行為。 関連アクション:
|
|
| Subscription | 提供された製品の総価格に対するサブスクリプションの価格構成要素を表します。 | |
| Substance | 定義された組成を持つ、離散的な存在を持つ、生物学的、鉱物学的、または化学的な起源を持つあらゆる物質。 | |
| SubwayStation | 地下鉄の駅。 | |
| Suite | ホテルまたはその他の宿泊施設におけるスイートとは、複数の部屋を特徴とする高級宿泊施設のクラスを指します(出典:Wikipedia, the free encyclopedia, 参照 http://en.wikipedia.org/wiki/Suite_(hotel))。
ホテルやその他の宿泊施設をマークアップするためのschema.orgの使用に関する専用ドキュメントも参照してください。 |
|
| Sunday | 土曜日と月曜日の間の曜日。 | |
| SuperficialAnatomy | 解剖学的な特徴のうち、解剖なしで視覚的に観察できるもの。これには、人体の形態と比例、そしてより深部の皮下構造に対応する表面のランドマークが含まれます。表面解剖学は、スポーツ医学、採血、その他の医療分野において重要な役割を果たします。なぜなら、表面触診によって基礎となる解剖学的構造を特定できるからです。例えば、背中手術の際、表面解剖学を用いて椎骨を触診・数え、切開部位を特定することができます。あるいは、採血においては、表面解剖学を用いて基礎となる静脈の位置を特定することができます。例えば、上腕静脈は、肘窩の境界(上腕骨内上顆や外上顆など)を触診し、静脈の大きさ、隆起、圧迫後の再充填能力、周囲組織の支持感などの表在的な兆候を探すことで見つけることができます。別の例として、肩関節の亜脱臼(脱臼)の場合、三角筋が肩関節を覆いきれず、肩甲骨の縁が表面的に可視になります。ここでは、表面解剖学とは可視化された肩甲骨の縁であり、これは基礎となる関節の脱臼(関連する解剖学的構造)を示唆しています。 | |
| Surgical | 医学の一分野であり、手技および器械を用いて疾患、外傷、および変形を治療することに関するものです。 | |
| SurgicalProcedure | 切開器具を用いた切開を伴う医療処置。診断、または治療目的のために行われる。 | |
| SuspendAction | デバイスまたはアプリケーション(例:音楽再生の一時停止、またはタイマーの一時停止)を瞬間的に停止する行為。 | |
| Suspended | 保留中。 | |
| SymptomsHealthAspect | Topicの症状または関連症状。 | |
| Synagogue | シナゴーグ。 | |
| TVClip | 短いテレビ番組、またはテレビ番組のセグメント/部分。 | |
| TVEpisode | シリーズまたはシーズンの一部となりうるテレビ番組のエピソード。 | |
| TVSeason | TV放送と関連するオンライン配信に特化したシーズン。 | |
| TVSeries | TV放送および関連オンライン配信に特化したCreativeWorkSeries。 | |
| Table | Webページ上の表。 | |
| TakeAction | 対象の所有権を起源から得る行為。GiveActionの逆操作。 関連アクション:
|
|
| TattooParlor | 入れ墨屋(いれずみや)。 | |
| Taxi | タクシー。 | |
| TaxiReservation | タクシーの予約。 注:これは実際の予約に関する情報用です(例:確認メールや個々の予約確認ページ)。チケットのオファーの場合は、Offerを使用してください。 |
|
| TaxiService | 運転手付きの車両による地域移動のためのサービスです。料金は通常、走行距離に基づいて計算されます。 | |
| TaxiStand | タクシー乗り場。 | |
| TaxiVehicleUsage | タクシーとしての車の使用を示します。 | |
| TechArticle | 技術記事 - 例:ハウツー(タスク)の話題、段階的な手順、手順に沿ったトラブルシューティング、仕様など。 | |
| TelevisionChannel | CableOrSatelliteServiceラインナップ上のテレビBroadcastServiceのユニークなインスタンス。 | |
| TelevisionStation | テレビ局。 | |
| TennisComplex | テニスコンプレックス。 | |
| Terminated | 終了しました。 | |
| Text | データ型: Text. | |
| TextDigitalDocument | 主にテキストで構成されたファイル。 | |
| TheaterEvent | イベントタイプ: 演劇公演。 | |
| TheaterGroup | 劇団または劇会社、例えば、Royal Shakespeare CompanyやDruid Theatreなど。 | |
| Therapeutic | 治療目的で使用される医療機器。 | |
| TherapeuticProcedure | 主に治療目的を意図した医療処置で、健康状態の改善を目的とするものです。 | |
| Thesis | 学位または専門資格の候補資格を裏付けるために提出される論文または学位論文文書。 | |
| Thing | 最も一般的なアイテムのタイプです。 | |
| Throat | 臨床検査による喉の評価。 | |
| Thursday | 水曜日と金曜日の間の曜日。 | |
| Ticket | イベント、フライト、バスなどへのチケットを説明するために使用されます。 | |
| TieAction | 競争的な活動で引き分けになる行為。 | |
| Time | hh:mm:ss[Z|(+|-)hh:mm]の形式で複数日にわたって繰り返される時点(詳細はXMLスキーマを参照)。 | |
| TipAction | サービスへの対価として、受益者へ自発的に金銭を贈与する行為。 | |
| TireShop | タイヤ店。 | |
| TollFree | 関連する電話番号はフリーダイヤルです。 | |
| TouristAttraction | 観光名所。原則として、MountainやLandmarksOrHistoricalBuildingsからLocalBusinessまで、あらゆるものがTouristAttractionになり得ます。このタイプは、一般的なTouristAttractionを記述するため単独で使用することも、他のタイプに観光名所のプロパティを追加するためのadditionalTypeとして使用することもできます。(下記に例を示します) | |
| TouristDestination | A tourist destination. In principle any Place can be a TouristDestination from a City, Region or Country to an AmusementPark or Hotel. This Type can be used on its own to describe a general TouristDestination, or be used as an additionalType to add tourist relevant properties to any other Place. A TouristDestination is defined as a Place that contains, or is colocated with, one or more TouristAttractions, often linked by a similar theme or interest to a particular touristType. The UNWTO defines Destination (main destination of a tourism trip) as the place visited that is central to the decision to take the trip. (See examples below). [TRANSLATION ERROR - ORIGINAL KEPT] | |
| TouristInformationCenter | 観光案内所。 | |
| TouristTrip | A tourist trip. A created itinerary of visits to one or more places of interest (TouristAttraction/TouristDestination) often linked by a similar theme, geographic area, or interest to a particular touristType. The UNWTO defines tourism trip as the Trip taken by visitors. (See examples below). [TRANSLATION ERROR - ORIGINAL KEPT] | |
| Toxicologic | 毒物、その性質、効果、検出に関心を持ち、中毒の治療に関与する医学の特定の分野。 | |
| ToyStore | おもちゃ屋さん。 | |
| TrackAction | エージェントは、更新のためにオブジェクトを追跡します。 関連アクション:
|
|
| TradeAction | 財やサービスを金銭的補償と交換すること。エージェントは、ある対象、製品、またはサービスを参加者と、一回限りの支払いまたは定期的な支払いと交換します。 | |
| TraditionalChinese | 中国発祥で数千年にわたり発展してきた共通の理論的概念に基づいた医学体系で、ハーブ、鍼灸、運動、マッサージ、食事療法、その他の方法を用いて、幅広い疾患を治療します。 | |
| TrainReservation | 列車の予約。 注:これは実際の予約に関する情報用です(例:確認メールや個々の予約確認ページ)。チケットのオファーの場合は、Offerを使用してください。 |
|
| TrainStation | 駅。 | |
| TrainTrip | 商業鉄道線での旅行。 | |
| TransferAction | ある場所から別の場所へ、抽象的または具体的な、生物または無生物の物体を移動/転送する行為。 | |
| TransformedContent | MediaReview 内でコード化された「変換されたコンテンツ」は、公開または共有された状況を考慮して判断されます。 VideoObject が「変換されたコンテンツ」であるためには:動画自体を変換するために、動画全体が操作されている必要があります。これには、Adobe Suiteなどのツールを使用して、動画の速度を変更したり、視覚要素を追加または削除したり、音声をダビングしたりすることが含まれます。ディープフェイクも変換の一種です。 ImageObject が「変換されたコンテンツ」であるためには:画像を誤解させる意図で、視覚要素を追加または削除して、意味を変えることです。 埋め込みテキストを持つ ImageObject が「変換されたコンテンツ」であるためには:画像を誤解させる意図で、視覚要素を追加または削除して、意味を変えることです。 AudioObject が「変換されたコンテンツ」であるためには:音声の一部または全部が操作されて言葉や音声を変更された場合、または音声が合成的に生成された場合(声真似ボイスの作成など)です。 |
|
| TransitMap | 乗り換え案内図。 | |
| TravelAction | ある場所 fromLocation から目的地まで、特定の交通手段を用いて移動する行為。参加者はオプション。 | |
| TravelAgency | 旅行代理店。 | |
| TreatmentIndication | 基礎疾患、症状などに対する適応 | |
| TreatmentsHealthAspect | Topicに関する治療法または関連療法。 | |
| Trip | 旅行または旅。1つ以上の場所への訪問の旅程。 | |
| TripleBlindedTrial | 研究者、治療を実施する者、患者のいずれも、患者に無作為に割り当てられた治療の詳細を知らない試験デザイン。 | |
| True | ブール値の true。 | |
| Tuesday | 月曜日と水曜日の間の曜日。 | |
| TypeAndQuantityNode | バンドルオファーに含まれる商品の数量、測定単位、およびビジネス機能を指す構造化された値です。 | |
| TypesHealthAspect | トピックに関連する分類およびその他の種類。 | |
| UKNonprofitType | UKNonprofitType: イギリス発祥の非営利団体の種類。 | |
| UKTrust | UKTrust: イギリスの信託を指す非営利団体タイプ。 | |
| URL | データ型: URL. | |
| USNonprofitType | USNonprofitType: 米国発祥の非営利団体の種類。 | |
| Ultrasound | 超音波イメージング。 | |
| UnRegisterAction | サービスの登録解除行為。 関連アクション:
|
|
| UnemploymentSupport | 失業手当: これは失業手当の給付金です。 | |
| UnincorporatedAssociationCharity | UnincorporatedAssociationCharity: 英国において、法人化されていない慈善団体を指す非営利型。 | |
| UnitPriceSpecification | それぞれの組織または個人が提示する特定のオファーに対して求められる価格。 | |
| UnofficialLegalValue | 特定のまたは特別な地位を持たない文書を示します(例:民間出版社による法律の再出版)。 | |
| UpdateAction | オブジェクトの状態を変更/編集することによる管理行為。 | |
| Urologic | 尿路および泌尿生殖器系に関連する疾患の診断と治療を扱う医学の特定の分野。 | |
| UsageOrScheduleHealthAspect | トピックに関する、方法、タイミング、頻度、および投与量についての内容。 | |
| UseAction | 対象物を意図された目的に適用する行為。 | |
| UsedCondition | アイテムが使用済みであることを示します。 | |
| UserBlocks | UserInteractionとそのサブタイプは、ユーザーがページとインタラクションする方法について話す古い方法です。一般的には、Commentのようなタイプとともに、Actionベースの語彙を使用する方が良いでしょう。 | |
| UserCheckins | UserInteractionとそのサブタイプは、ユーザーがページとインタラクションする方法について話す古い方法です。一般的には、Commentのようなタイプとともに、Actionベースの語彙を使用する方が良いでしょう。 | |
| UserComments | UserInteractionとそのサブタイプは、ユーザーがページとインタラクションする方法について話す古い方法です。一般的には、Commentのようなタイプとともに、Actionベースの語彙を使用する方が良いでしょう。 | |
| UserDownloads | UserInteractionとそのサブタイプは、ユーザーがページとインタラクションする方法について話す古い方法です。一般的には、Commentのようなタイプとともに、Actionベースの語彙を使用する方が良いでしょう。 | |
| UserInteraction | UserInteractionとそのサブタイプは、ユーザーがページとインタラクションする方法について話す古い方法です。一般的には、Commentのようなタイプとともに、Actionベースの語彙を使用する方が良いでしょう。 | |
| UserLikes | UserInteractionとそのサブタイプは、ユーザーがページとインタラクションする方法について話す古い方法です。一般的には、Commentのようなタイプとともに、Actionベースの語彙を使用する方が良いでしょう。 | |
| UserPageVisits | UserInteractionとそのサブタイプは、ユーザーがページとインタラクションする方法について話す古い方法です。一般的には、Commentのようなタイプとともに、Actionベースの語彙を使用する方が良いでしょう。 | |
| UserPlays | UserInteractionとそのサブタイプは、ユーザーがページとインタラクションする方法について話す古い方法です。一般的には、Commentのようなタイプとともに、Actionベースの語彙を使用する方が良いでしょう。 | |
| UserPlusOnes | UserInteractionとそのサブタイプは、ユーザーがページとインタラクションする方法について話す古い方法です。一般的には、Commentのようなタイプとともに、Actionベースの語彙を使用する方が良いでしょう。 | |
| UserReview | エンドユーザー(例:消費者、購入者、参加者など)によって作成されたレビューで、CriticReviewとは対照的です。 | |
| UserTweets | UserInteractionとそのサブタイプは、ユーザーがページとインタラクションする方法について話す古い方法です。一般的には、Commentのようなタイプとともに、Actionベースの語彙を使用する方が良いでしょう。 | |
| VeganDiet | 動物性食品を一切含まない食事。 | |
| VegetarianDiet | 動物肉のみを排除した食事。 | |
| Vehicle | 乗り物とは、陸、水、空、または宇宙を介して人や貨物を輸送するように設計または使用される装置です。 | |
| Vein | 心臓に血液を特異的に運ぶ血管の一種。 | |
| VenueMap | 会場マップ(例:ショッピングモール、講堂、博物館など)。 | |
| Vessel | 人間の循環器系の一構成要素であり、全身に血液を輸送する複雑な空洞状の管のネットワークで構成されています。 | |
| VeterinaryCare | 獣医のオフィス。 | |
| VideoGallery | Webページの種類: ビデオギャラリーページ。 | |
| VideoGame | ビデオゲームは、ビデオデバイス上で視覚的なフィードバックを生成するために、ユーザーインターフェースとの人間の相互作用を伴う電子ゲームです。 | |
| VideoGameClip | ビデオゲームの短いセグメント/パート。 | |
| VideoGameSeries | ビデオゲームシリーズ。 | |
| VideoObject | ビデオファイル。 | |
| ViewAction | 静的な視覚コンテンツを消費する行為。 | |
| VinylFormat | VinylFormat. | |
| VirtualLocation | イベントに参加するためのオンラインまたは仮想的な場所です。例えば、オンラインセミナーや教育イベントに参加することが挙げられます。仮想的な場所はイベントの場所として使用できますが、仮想的な場所と現実世界の物理的な場所を混同しないでください。 | |
| Virus | ウイルス感染症を引き起こす病原ウイルス。 | |
| VisualArtsEvent | イベントタイプ: 視覚芸術イベント。 | |
| VisualArtwork | 主に視覚的特徴を持つ芸術作品。 | |
| VitalSign | バイタルサインは、最も基本的な身体機能を評価するために、様々な生理学的機能を測定するものです。 | |
| Volcano | 富士山のような火山。 | |
| VoteAction | 固定/有限/構造化された選択肢/オプションのセットから優先順位を表現する行為。 | |
| WPAdBlock | ページの広告セクション。 | |
| WPFooter | ページのフッターセクション。 | |
| WPHeader | ページのヘッダーセクション。 | |
| WPSideBar | ページのサイドバーセクション。 | |
| WantAction | 対象について願望を表明する行為。主体は対象を欲する。 | |
| WarrantyPromise | 製品の欠陥または誤動作が発生した場合に、顧客に無償で提供されるサービスの期間と範囲を表す構造化された値。 | |
| WarrantyScope | 製品の欠陥または誤動作が発生した場合に、顧客に無料で提供される一連のサービス。 一般的に使用される値:
|
|
| WatchAction | 動的な/移動する視覚コンテンツを消費する行為。 | |
| Waterfall | ナイアガラの滝のような滝。 | |
| WearAction | 衣服を着る行為。 | |
| WearableMeasurementBack | ジャケットなどの背中部分の測定 | |
| WearableMeasurementChestOrBust | スーツなどの胸囲/バスト部分の測定 | |
| WearableMeasurementCollar | シャツの襟の測定、例えば{シャツ}の襟 | |
| WearableMeasurementCup | カップの測定、例えばブラジャーの例 | |
| WearableMeasurementHeight | 高さの測定、例えば靴のヒールの高さ | |
| WearableMeasurementHips | スカートなどの、ヒップ部分の計測について | |
| WearableMeasurementInseam | パンツなどの股下の測定 | |
| WearableMeasurementLength | ドレスなどの長さを表します。 | |
| WearableMeasurementOutsideLeg | ズボンの外股の計測など | |
| WearableMeasurementSleeve | シャツの袖丈の測定など | |
| WearableMeasurementTypeEnumeration | ウェアラブル製品の一般的な測定タイプを列挙します。 | |
| WearableMeasurementWaist | ズボンのウエスト部分の測定、例えば{Measurement of the waist section, for example of pants} | |
| WearableMeasurementWidth | 靴の幅の測定、例えば{shoes}の幅 | |
| WearableSizeGroupBig | ウェアラブル向けのサイズグループ「Big」。 | |
| WearableSizeGroupBoys | ウェアラブル向けのサイズグループ「Boys」。 | |
| WearableSizeGroupEnumeration | ウェアラブル製品の一般的なサイズグループ(「サイズタイプ」とも呼ばれます)を列挙します。 | |
| WearableSizeGroupExtraShort | ウェアラブル向けのサイズグループ「Extra Short」。 | |
| WearableSizeGroupExtraTall | ウェアラブル向けのサイズグループ「Extra Tall」。 | |
| WearableSizeGroupGirls | ウェアラブル向けのサイズグループ「Girls」。 | |
| WearableSizeGroupHusky | ウェアラブル向けのサイズグループ「Husky」(または「Stocky」)。 | |
| WearableSizeGroupInfants | ウェアラブル向けのサイズグループ「Infants」。 | |
| WearableSizeGroupJuniors | ウェアラブル向けのサイズグループ「Juniors」。 | |
| WearableSizeGroupMaternity | ウェアラブル向けのサイズグループ「Maternity」。 | |
| WearableSizeGroupMens | ウェアラブル向けのサイズグループ「Mens」。 | |
| WearableSizeGroupMisses | ウェアラブル向けのサイズグループ「Misses」(別名「Missy」)。 | |
| WearableSizeGroupPetite | ウェアラブル向けのサイズグループ「Petite」。 | |
| WearableSizeGroupPlus | ウェアラブル向けのサイズグループ「Plus」。 | |
| WearableSizeGroupRegular | ウェアラブル向けのサイズグループ「Regular」。 | |
| WearableSizeGroupShort | ウェアラブル向けのサイズグループ「Short」。 | |
| WearableSizeGroupTall | ウェアラブル向けのサイズグループ「Tall」。 | |
| WearableSizeGroupWomens | ウェアラブル向けのサイズグループ「Womens」。 | |
| WearableSizeSystemAU | ウェアラブルのオーストラリアサイズシステム。 | |
| WearableSizeSystemBR | ウェアラブル向けのブラジルサイズシステム。 | |
| WearableSizeSystemCN | ウェアラブル向けの中国サイズシステム。 | |
| WearableSizeSystemContinental | ウェアラブル向けのコンチネンタルサイズシステム。 | |
| WearableSizeSystemDE | ウェアラブル向けのドイツサイズシステム。 | |
| WearableSizeSystemEN13402 | EN 13402 (衣服のサイズ表示に関するヨーロッパ共同規格)。 | |
| WearableSizeSystemEnumeration | ウェアラブル製品に特有の一般的なサイズシステムを列挙します。 | |
| WearableSizeSystemEurope | ウェアラブル向けのヨーロッパサイズシステム。 | |
| WearableSizeSystemFR | ウェアラブル向けのフランスのサイズシステム。 | |
| WearableSizeSystemGS1 | ウェアラブル向けのGS1(旧NRF)サイズシステム。 | |
| WearableSizeSystemIT | ウェアラブル向けのイタリアのサイズシステム。 | |
| WearableSizeSystemJP | ウェアラブルの日本のサイズシステム。 | |
| WearableSizeSystemMX | ウェアラブル向けのメキシコサイズシステム。 | |
| WearableSizeSystemUK | ウェアラブル向けのイギリスサイズシステム。 | |
| WearableSizeSystemUS | ウェアラブル向けの米国サイズシステム。 | |
| WebAPI | Web/インターネット技術を通じてアクセス可能なアプリケーションプログラミングインターフェース。 | |
| WebApplication | ウェブアプリケーション。 | |
| WebContent | WebContentは、すべてのWebPage、WebSite、およびWebPageElementコンテンツを表す型です。Webページ、サイト、およびそれらの構成要素間の詳細な区別が、必ずしも重要または明白でない場合があります。WebContent型は、そのような区別を常に明示する必要なく、Webアドレス指定可能なコンテンツを記述しやすくします。(意図としては、既存の型WebPage、WebSite、およびWebPageElementが最終的にWebContentのサブタイプとして宣言されることです)。 | |
| WebPage | ウェブページ。すべてのウェブページは暗黙的にWebPage型として宣言されているとみなされるため、breadcrumbのようなそのウェブページに関する様々なプロパティを使用できます。これらのプロパティが指定されている場合は明示的な宣言を推奨しますが、itemscope外でこれらが見つかった場合は、ページに関するものとみなされます。 |
|
| WebPageElement | テーブルや画像などのウェブページの要素。 | |
| WebSite | ウェブサイトは、関連するウェブページやその他の項目が、通常、単一のウェブドメインから提供され、URLを通じてアクセス可能なものです。 | |
| Wednesday | 火曜日と木曜日の間の曜日。 | |
| WesternConventional | 科学的根拠に基づいた臨床的意思決定を目指す、西洋医学の従来のシステム。従来の医学または西洋医学とも呼ばれる。 | |
| Wholesale | この薬の費用は、薬の卸売取得原価(Wholesale Acquisition Cost)を表します。 | |
| WholesaleStore | 卸売店。 | |
| WinAction | 競争的な活動で勝利を収める行為。 | |
| Winery | ワイナリー。 | |
| Withdrawn | 取り下げられました。 | |
| WorkBasedProgram | 教育と就労の両方の要素を持つプログラム。通常、職場を拠点とし、職場学習を中心に構成され、職業に関連する能力を育成することを目的としています。WorkBasedProgramは、徒弟制度のようなプログラムを、学校、大学、その他の教室ベースの教育プログラムと区別するために使用されます。 | |
| WorkersUnion | 労働組合(労働組合、労働組合、またはトレードユニオンとしても知られています)は、労働組合員とその労働条件の改善のために、経営側との団体交渉、組織活動、政治的ロビー活動を行う組織です。 | |
| WriteAction | 書かれた創造的なコンテンツを作成する行為。 | |
| WritePermission | ドキュメントの書き込みまたは編集の許可。 | |
| XPathType | XPath(通常はバージョン1.0ですが、必ずしもそうとは限りません)を表すテキスト。 | |
| XRay | X線イメージング。 | |
| ZoneBoardingPolicy | 航空会社は、飛行機のゾーンごとに搭乗します。 | |
| Zoo | 動物園。 |
推奨セマンティック用語
概要
このドキュメントはSchema.orgで定義されている語彙から、ALPSプロファイルのセマンティックディスクリプタ(id)として使用できる用語の完全な一覧です。
使い方
- APIの設計を始める際は、まず 🔵 Core Terms から適切な用語を選択します。
- より詳細な表現が必要な場合は、🟡 Extended Terms を検討します。
- 特殊なユースケースでは、⚪ Full Terms まで視野に入れて検討します。
- カテゴリインデックスから必要な分野の用語を探せます。
- ドメイン固有の用語について:
- 業界やビジネス固有の用語は、独自のセマンティックディスクリプタとして定義します。
- 命名規則: domainName + PropertyName (例:orderShippingStatus, medicalDiagnosisCode)
- できるだけSchema.orgの用語を基盤としつつ、必要な拡張を行うことを推奨します。
- ドメイン固有の用語を定義する際は、その意味と用途を明確にドキュメント化することが重要です。
カテゴリインデックス
- 基本プロパティ
- 識別子・参照
- メタデータ
- 日時・期間
- テキスト・コンテンツ
- メディア・ファイル
- 人物・個人
- 組織・団体
- 住所・位置
- 商品・サービス
- 価格・支払い
- イベント・活動
- レビュー・評価
- 教育・学習
- 医療・健康
- 金融・取引
- 予約・スケジュール
- コミュニケーション
- セキュリティ・アクセス制御
- ワークフロー・プロセス
- 技術・システム
- 法務・規約
- その他の属性
| status | 🔵 | 状態 | |
| type | 🔵 | タイプ | |
| category | 🔵 | カテゴリ | |
| order | 🔵 | 順序 | |
| priority | 🔵 | 優先度 | |
| tag | 🔵 | タグ | |
| group | 🔵 | グループ | |
| relation | 🔵 | 関係 | |
| source | 🔵 | ソース | |
| target | 🔵 | ターゲット | |
| origin | 🟡 | 起源 | |
| destination | 🟡 | 目的地 | |
| sortOrder | 🟡 | ソート順 | |
| rank | 🟡 | ランク | |
| score | 🟡 | スコア | |
| level | 🟡 | レベル | |
| theme | 🟡 | テーマ | |
| style | 🟡 | スタイル | |
| layout | 🟡 | レイアウト | |
| template | 🟡 | テンプレート | |
| format | 🟡 | フォーマット | |
| mode | 🟡 | モード | |
| state | 🟡 | 状態 | |
| phase | 🟡 | フェーズ | |
| context | 🟡 | コンテキスト | |
| scope | 🟡 | スコープ | |
| flags | ⚪ | フラグ | |
| options | ⚪ | オプション | |
| settings | ⚪ | 設定 | |
| preferences | ⚪ | 環境設定 | |
| configuration | ⚪ | 構成 | |
| customization | ⚪ | カスタマイズ | |
| variant | ⚪ | バリアント | |
| alternative | ⚪ | 代替 | |
| fallback | ⚪ | フォールバック | |
| override | ⚪ | 上書き | |
| default | ⚪ | デフォルト | |
| custom | ⚪ | カスタム | |
| external | ⚪ | 外部 | |
| internal | ⚪ | 内部 | |
| public | ⚪ | 公開 | |
| private | ⚪ | 非公開 | |
| hidden | ⚪ | 非表示 | |
| visible | ⚪ | 表示 | |
| enabled | ⚪ | 有効 | |
| disabled | ⚪ | 無効 | |
| locked | ⚪ | ロック済み | |
| archived | ⚪ | アーカイブ済み | |
| deleted | ⚪ | 削除済み | |
| deprecated | ⚪ | 非推奨 |
おわりに
このドキュメントは継続的に更新され、新しい用語や使用パターンが追加される可能性があります。
重要度レベル
すべての用語は、重要度と使用頻度に基づいて3段階にレベル分けされています:
- 🔵 Core Terms: 基本的なAPIに必須の主要用語(全体の約10-15%)
- ほとんどのアプリケーションで使用される基礎的な語彙
- シンプルなAPIを作る際の最初の選択肢
- 一般的なCRUD操作に必要な用語
- 🟡 Extended Terms: よく使用される拡張用語(全体の約30-35%)
- 特定のドメインやより詳細な表現に必要な語彙
- 一般的なビジネスアプリケーションでよく使用される用語
- より豊かな表現力が必要な場合の選択肢
- ⚪ Full Terms: 特殊用途の用語(全体の約50-55%)
- 特定の業界や特殊なユースケースで必要となる語彙
- 完全な互換性が必要な場合の選択肢
- 非常に専門的な表現のための用語
使用上の注意
- 命名規則:
- lowerCamelCase形式を使用
- 略語は避け、完全な単語を使用
- 一貫性のある命名パターンを維持
- カスタマイズ:
- 必要に応じて独自の用語を追加可能
- 業界固有の用語は適切なプレフィックスを付けることを推奨
- 組織内で統一した用語の使用を心がける
- 相互運用性:
- Schema.orgとの互換性を意識
- 標準的な用語を優先的に使用
- 独自拡張する場合は明確な文書化を行う
参考リソース
共有ボキャブラリ
アプリケーションを設計する際に共有ボキャブラリ(共通語彙)サイトに登録された標準化された語句を利用することを推奨します。
IANA リンクリレーション
リンクリレーションとは、2つのリソース間の関係性を示す標準化された識別子です。主な目的は、リソース間の意味的な関係を明確にすることです。
例) IANAに登録されているauthor
<descriptor id="goBookAuthor" type="safe" rt="#BookAuthor" rel="author">
IANAリンクリレーションをご覧ください。
Schema.org
Schema.orgは、Google、Microsoft、Yahoo、Yandexが共同で開発した構造化データの語彙(ボキャブラリー)です。
セマンティック用語をご覧ください。
Schema.orgのセマンティックをインポートしたALPSファイルが利用できます。
セマンティックにhrefでリンクします。
例)givenNameとfamilynName
<decriptor id="Person">
<descriptor href="https://alps-io.github.io/imports/schema.org/properties/givenName.json" />
<descriptor href="https://alps-io.github.io/imports/schema.org/properties/familyName.json" />
</decriptor>
狭くする
共有ボキャブラリからセマンティックを狭くしたディスクリプタを作成できます。
例)
<descriptor id="bankAccountId" href="https://alps-io.github.io/imports/schema.org/properties/accountId.json" />

家を建てるとき、外観写真やパース図だけでは不十分です。
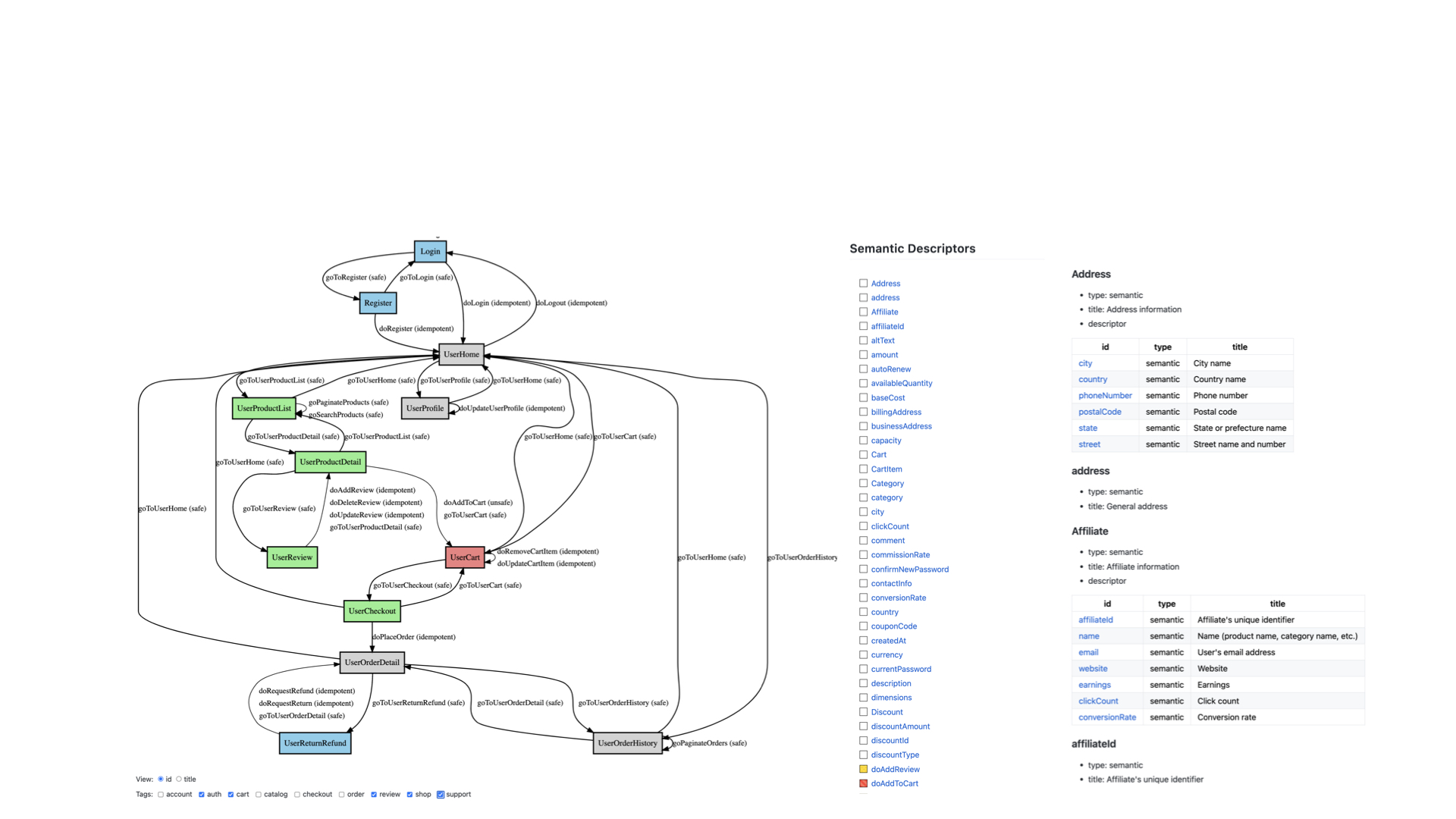
Webサイトを作る時の共通言語が、ALPSドキュメントです。
ALPS チュートリアル
ALPSのチュートリアルは2部構成になっています:
- 基本チュートリアル(このページ)
- 実践的なハンズオン形式で、ALPSの基本的な使い方を学びます
- ツールの使用方法から始めて、段階的にALPSの機能を理解していきます
- ALPSを使い始めるための最初のステップとして最適です
- 応用チュートリアル
- ALPSの理論的な基盤と設計パターンについて学びます
- REST/HTTPアプリケーションの状態遷移システムとしての本質を理解します
- より深い理解を得たい方や、大規模なアプリケーション設計に携わる方向けです
まずはこの基本チュートリアルから始めることをお勧めします。
始める
このチュートリアルでは、ブラウザベースのALPSエディタを使用します:
- ALPS Editor を開きます
- 左側のエディターペインに表示されているデモコードを全て削除します
注:ローカル環境でASDアプリケーションを使用することもできますが、このチュートリアルではオンラインエディタの使用を推奨しています。
最初のステップ:空のファイルを用意する
ALPSドキュメントを作成するための最初のステップとして、基本となる空のファイルを用意します。これは、すべてのALPSドキュメントの出発点となる最小限の構造を持つファイルです。
ALPSドキュメントは、XMLまたはJSON形式で記述できます。それぞれの形式には対応するスキーマ(XMLはXSD、JSONはJson-Schema)があり、これを参照することでドキュメントの構造が正しく、ALPS仕様に沿っているかをチェックできます。どちらの形式を使っても機能的な違いはないので、チームの好みや普段使っているツールに合わせて選んでください。
XMLの場合:
<?xml version="1.0" encoding="UTF-8"?>
<alps
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="https://alps-io.github.io/schemas/alps.xsd">
</alps>
JSONの場合:
{
"$schema": "https://alps-io.github.io/schemas/alps.json",
"alps": {
"descriptor": [
]
}
}
意味をIDとして登録する
ALPSではアプリケーションが扱う特定の語句をIDとして定義します。最初にdateCreated(作成日付)という語句を加えてみましょう。
XMLの場合:
<?xml version="1.0" encoding="UTF-8"?>
<alps
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="https://alps-io.github.io/schemas/alps.xsd">
+ <descriptor id="dateCreated"/>
</alps>
JSONの場合:
{
"$schema": "https://alps-io.github.io/schemas/alps.json",
"alps": {
"descriptor": [
+ {"id": "dateCreated"}
]
}
}
語句を説明する
titleやdocで説明を加えられます。
XMLの場合:
<?xml version="1.0" encoding="UTF-8"?>
<alps
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="https://alps-io.github.io/schemas/alps.xsd">
- <descriptor id="dateCreated"/>
+ <descriptor id="dateCreated" title="作成日付">
+ <doc format="text">ISO8601フォーマットで記事の作成日付を表します</doc>
+ </descriptor>
</alps>
JSONの場合:
{
"$schema": "https://alps-io.github.io/schemas/alps.json",
"alps": {
"descriptor": [
- {"id": "dateCreated"}
+ {"id": "dateCreated", "title": "作成日付", "doc": {"format": "text", "value": "ISO8601フォーマットで記事の作成日付を表します"}}
]
}
}
titleは見出しのような簡潔な表現、docはより長いテキストでの説明です。
この意味に紐づけられたIDをセマンティックディスクリプタ(意味的記述子)といいます。dateCreatedは「作成日付」という意味を紐づけたセマンティックディスクリプタです。このような意味や概念の定義をオントロジーといいます。
ボキャブラリ
ALPSの重要な役割の1つはアプリケーションの語句の辞書になることです。利用者が同じ意味を指し示すときは同じ語句を使い、表現の揺れを防いだり、利用者が違った認識を持つことを防止します。
情報は情報を含む
セマンティックディスクリプタはセマンティックディスクリプタを含むことがあります。
例えば、BlogPosting(ブログ記事)はarticleBody(本文)とdateCreated(作成日付)を含みます。descriptorの中にdescriptorを記述することで情報の階層を表します。このような情報の構成や配置がタクソノミーです。
XMLの場合:
<alps
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="https://alps-io.github.io/schemas/alps.xsd">
<!-- Ontology -->
<descriptor id="id" title="id"/>
<descriptor id="articleBody" title="本文"/>
<descriptor id="dateCreated" title="作成日付"/>
<!-- Taxonomy -->
<descriptor id="BlogPosting" title="記事" >
<descriptor href="#id"/>
<descriptor href="#dateCreated"/>
<descriptor href="#articleBody"/>
</descriptor>
<descriptor id="Blog" title="記事リスト">
<descriptor href="#BlogPosting"/>
</descriptor>
</alps>
JSONの場合:
{
"$schema": "https://alps-io.github.io/schemas/alps.json",
"alps": {
"descriptor": [
{"id": "id", "title": "id"},
{"id": "articleBody", "title": "本文"},
{"id": "dateCreated", "title": "作成日付"},
{"id": "BlogPosting", "title": "記事", "descriptor": [
{"href": "#id"},
{"href": "#dateCreated"},
{"href": "#articleBody"}
]},
{"id": "Blog", "title": "記事リスト", "descriptor": [
{"href": "#BlogPosting"}
]}
]
}
}
#を使って他のdescriptorを参照する事ができます。これをインラインリンクと呼び1つのdescriptorを複数の箇所から参照する事ができます。
情報の閲覧と操作
Webのページは情報だけでなく他のページへのリンクやアクションのフォームを含み、関連する情報の閲覧や操作ができます。以下の3種類の操作が出来ます。
safe
関連する情報の閲覧。HTMLで言うとAタグ、HTTPではGETです。リソースの状態を変更しない安全な遷移です。ユーザーが何を見ているかというアプリケーション状態が変化します。つまり閲覧しているURLが変わります。
idempotent
リソース状態を変更します。冪等性(べきとうせい)があり、何度繰り返しても同じ結果になります。ファイルの上書きをイメージしてください。何度実行しても結果は変わりません。
unsafe
idempotentと同じようにリソース状態は変更しますが冪等性がありません。ファイルの追記をイメージしてください。繰り返し実行しただけ結果が異なってきます。
HTTPメソッドとの対応
safeはGET、idempotentはPUTまたはDELETE、unsafeはPOSTとそれぞれのHTTPのメソッドに対応します。
リンク
typeで操作の種類、rtで遷移先を指定してリンクを作成します。
この例はBlogを閲覧するリンクです。
XMLの場合:
<descriptor type="safe" id="goBlog" rt="#Blog" title="ブログ記事リストを見る" />
JSONの場合:
{"type": "safe", "id": "goBlog", "rt": "#Blog", "title": "ブログ記事リストを見る"}
この例はブログ記事からブログ記事リストに戻る操作を追加しています。
XMLの場合:
<descriptor id="BlogPosting" title="記事">
<descriptor href="#id"/>
<descriptor href="#dateCreated"/>
<descriptor href="#articleBody"/>
<descriptor href="#goBlog" />
</descriptor>
JSONの場合:
{"id": "BlogPosting", "title": "記事", "descriptor": [
{"href": "#id"},
{"href": "#dateCreated"},
{"href": "#articleBody"},
{"href": "#goBlog"}
]}
遷移や操作に必要なdescriptorはdescriptorに含めます。
XMLの場合:
<descriptor id="goBlogPosting" type="safe" rt="#BlogPosting" title="記事を見る">
<!-- 記事を見るにはIDが必要 -->
<descriptor href="#id"/>
</descriptor>
JSONの場合:
{"id": "goBlogPosting", "type": "safe", "rt": "#BlogPosting", "title": "記事を見る", "descriptor": [
{"href": "#id"}
]}
ブログ記事リストとブログ記事双方のリンクを追加してみましょう。
XMLの場合:
<alps
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="https://alps-io.github.io/schemas/alps.xsd">
<!-- Ontology -->
<descriptor id="id" title="id"/>
<descriptor id="articleBody" title="本文"/>
<descriptor id="dateCreated" title="作成日付"/>
<!-- Taxonomy -->
<descriptor id="BlogPosting" title="記事" >
<descriptor href="#id"/>
<descriptor href="#dateCreated"/>
<descriptor href="#articleBody"/>
<descriptor href="#goBlog" />
</descriptor>
<descriptor id="Blog" title="記事リスト">
<descriptor href="#BlogPosting"/>
<descriptor href="#goBlogPosting" />
</descriptor>
<!-- Choreography -->
<descriptor type="safe" id="goBlog" rt="#Blog" title="記事リストを見る" />
<descriptor type="safe" id="goBlogPosting" rt="#BlogPosting" title="記事を見る">
<descriptor href="#id"/>
</descriptor>
</alps>
JSONの場合:
{
"$schema": "https://alps-io.github.io/schemas/alps.json",
"alps": {
"descriptor": [
{"id": "id", "title": "id"},
{"id": "articleBody", "title": "本文"},
{"id": "dateCreated", "title": "作成日付"},
{"id": "BlogPosting", "title": "記事", "descriptor": [
{"href": "#id"},
{"href": "#dateCreated"},
{"href": "#articleBody"},
{"href": "#goBlog"}
]},
{"id": "Blog", "title": "記事リスト", "descriptor": [
{"href": "#BlogPosting"},
{"href": "#goBlogPosting"}
]},
{"type": "safe", "id": "goBlog", "rt": "#Blog", "title": "記事リストを見る"},
{"type": "safe", "id": "goBlogPosting", "rt": "#BlogPosting", "title": "記事を見る", "descriptor": [
{"href": "#id"}
]}
]
}
}
アプリケーション状態遷移図
記事リスト、記事、双方からリンクされた状態遷移図が表示されます。四角のボックスのはユーザーがどこを見ているかというアプリケーション状態、つまり閲覧中のWebページです。矢印は情報の閲覧や変更などの操作を表します。HTMLでのAタグやFORMタグの遷移に該当します。ボックスや矢印をクリックすると詳しい情報が見られます。確認してみましょう。
Webサイトの情報が相互にリンクされているように、ASDドキュメントページも相互にリンクされています。アプリケーション状態遷移図はサイトの情報設計を俯瞰することができ、情報の意味や構造、接続といった情報設計の詳細にリンクしています。
RESTアプリケーションのためのALPSチュートリアル
はじめに
現代のWebアプリケーション(オンラインショッピング、SNS、動画配信サービス、業務システムなど)は、多くがRESTアーキテクチャに基づいて構築されています。このチュートリアルでは、RESTの基本概念を踏まえ、ALPSを用いたアプリケーション設計の方法を解説します。
RESTアプリケーションの本質
RESTアプリケーションは本質的に「状態遷移システム」です。たとえば:
- 商品を探し、カートに入れ、注文を確定する(オンラインショッピング)
- 投稿を読み、反応し、コメントを残す(SNS)
これらの一連の行動はすべて「状態」から「状態」への移り変わり(遷移)として捉えられ、RESTアプリケーションはこの遷移を管理する仕組みです。
状態遷移とは
状態遷移は、あるシステムが持つ状態が別の状態に変化することを指します。Webアプリケーションでは:
- ユーザーは常に「どこか」にいます(現在の状態)
- そこから「どこかへ」移動できます(遷移可能な状態)
- 「どうやって」移動するかが定義されています(遷移方法)
これら3つの要素が状態遷移システムの基本です。
RESTの2つの状態
状態遷移で用いられる状態以外に、RESTには2種類の重要な状態があります:
- アプリケーション状態
- クライアント(ブラウザ)側での現在の位置を示し、URLで表現されます
- リソース状態
- サーバー側で管理されるデータの状態です
クライアントはアプリケーション状態の変更によってリソース状態にアクセスし、 サーバーはリソース状態とともに、次の状態への遷移情報(ネットワークアフォーダンス)も返します。
RESTアプリケーションの状態遷移の基本的な流れ
RESTアプリケーションにおける状態遷移は、次のような流れで行われます:
- 状態の認識
- クライアントは現在の状態を把握し、利用可能な情報を理解します
- 遷移の選択
- 提供されているリンクや操作を確認し、次の遷移先を選択します。
- 状態の遷移
- 選択した操作を実行し、新しい状態へ移行します。
この流れは、アプリケーションの利用中、継続的に繰り返されます。
情報アーキテクチャとALPS
RESTアプリケーションを適切に設計するためには、状態遷移システムを体系的に記述する必要があります。 Dan Klynは、この記述に必要な3つの重要な側面を提唱しています:
- オントロジー(Ontology)
- 「何を意味するのか」を定義します
- 例:「ブログ記事」「作成日時」という言葉の意味
- 用語の同じ意味を共有します
- タクソノミー(Taxonomy)
- 「どのように関係しているか」を整理します
- 例:「ブログ記事」は「作成日時」と「本文」を持ちます
- 情報の構造を定義します
- コレオグラフィー(Choreography)
- 「どのように動作するか」を記述します
- 例:記事の閲覧、作成、更新、削除
- 操作の流れを示します
ALPSは、これらの概念を実践的に表現するための手段です。以降のチュートリアルでは:
- オントロジー:基本的な用語の定義
- タクソノミー(1):情報構造の定義
- コレオグラフィー:状態遷移の定義
- タクソノミー(2):状態と遷移の統合
の順で、具体的な実装方法を学んでいきます。
オントロジー:用語の定義
オントロジーでは、アプリケーションで使用する言葉の意味を定義します。この段階で明確に定義することで、チーム間での共通理解が生まれ、API設計が一貫性を持つようになります。
エディターの準備
- ブラウザで https://editor.app-state-diagram.com/ を開きます
- 左側のエディターペインに表示されているデモコードを全て削除します
最初の用語を定義する
以下は「作成日時」を表す用語の定義です。
XMLの場合:
<?xml version="1.0" encoding="UTF-8"?>
<alps
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="https://alps-io.github.io/schemas/alps.xsd">
<descriptor id="dateCreated" title="作成日時">
<doc format="text">記事が作成された日時をISO8601形式で表します</doc>
</descriptor>
</alps>
JSONの場合:
{
"$schema": "https://alps-io.github.io/schemas/alps.json",
"alps": {
"version": "1.0",
"descriptor": [
{"id": "dateCreated", "title": "作成日時", "doc": {"format": "text", "value": "記事が作成された日時をISO8601形式で表します"}}
]
}
}
この定義の各要素の意味:
id属性- 用語の識別子
title属性- 人間が理解しやすい短い説明です
- 画面やドキュメントでの表示に使用します
doc要素- 用語の正確な意味や使用方法を記述します -形式(format属性)を指定できます
記事の本文を定義する
続いて、ブログ記事の本文を表す用語を追加します。
XMLの場合:
<?xml version="1.0" encoding="UTF-8"?>
<alps
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="https://alps-io.github.io/schemas/alps.xsd">
<descriptor id="dateCreated" title="作成日時">
<doc format="text">記事が作成された日時をISO8601形式で表します</doc>
</descriptor>
<descriptor id="articleBody" title="記事本文">
<doc format="text">ブログ記事の本文</doc>
</descriptor>
</alps>
JSONの場合:
{
"$schema": "https://alps-io.github.io/schemas/alps.json",
"alps": {
"version": "1.0",
"descriptor": [
{"id": "dateCreated", "title": "作成日時", "doc": {"format": "text", "value": "記事が作成された日時をISO8601形式で表します"}},
{"id": "articleBody", "title": "記事本文", "doc": {"format": "text", "value": "ブログ記事の本文"}}
]
}
}
オントロジー定義のポイント
- 命名規則
- セマンティック用語を優先して選びます
- 一貫性のある命名パターンを使用します
- キャメルケースを推奨(例:dateCreated, articleBody)
- 説明の書き方
- 簡潔で明確な説明を心がけます
- 必要な場合は例も含めます
- 形式や制約がある場合は明記します
タクソノミー:情報の構造化
タクソノミーでは「情報をどのように整理・分類するか」を定義します。 先ほど定義した用語を組み合わせて、より大きな概念を表現します。
ブログ記事(BlogPosting)は、作成日時と本文を持つ情報の集まりとして定義できます。
XMLの場合:
<?xml version="1.0" encoding="UTF-8"?>
<alps
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="https://alps-io.github.io/schemas/alps.xsd">
<descriptor id="dateCreated" title="作成日時">
<doc format="text">記事が作成された日時をISO8601形式で表します</doc>
</descriptor>
<descriptor id="articleBody" title="記事本文">
<doc format="text">ブログ記事の本文</doc>
</descriptor>
<descriptor id="BlogPosting" title="ブログ記事">
<descriptor href="#dateCreated"/>
<descriptor href="#articleBody"/>
</descriptor>
</alps>
JSONの場合:
{
"$schema": "https://alps-io.github.io/schemas/alps.json",
"alps": {
"version": "1.0",
"descriptor": [
{"id": "dateCreated", "title": "作成日時", "doc": {"format": "text", "value": "記事が作成された日時をISO8601形式で表します"}},
{"id": "articleBody", "title": "記事本文", "doc": {"format": "text", "value": "ブログ記事の本文"}},
{"id": "BlogPosting", "title": "ブログ記事", "descriptor": [
{"href": "#dateCreated"},
{"href": "#articleBody"}
]}
]
}
}
構造化のポイント
- href による参照
#を使って既存の用語を参照- 同じ定義を複数回使い回せる
- 用語の一貫性を保証
- 階層構造の表現
BlogPostingがdateCreatedとarticleBodyを含む- 含まれる要素は
descriptorタグで表現 - 親子関係として表現される
プレビュー画面での確認
- ボキャブラリリスト
- 定義した用語が階層的に表示される
- BlogPostingの配下に含まれる要素が表示
- 状態遷移図(State Diagram)
- BlogPostingが一つの状態として表示
- この時点ではまだ遷移は定義されていない
なぜ構造化が重要か
- 情報の関係性の明確化
- どの情報がどの概念に属するのか
- 情報の依存関係の可視化
- APIの一貫性
- 同じ構造が常に同じ形で表現される
- クライアントの実装が容易になる
- ドキュメントとしての役割
- システムの全体像の把握
- 情報構造の共通理解
コレオグラフィー:状態遷移の定義
コレオグラフィーでは、操作の種類に応じて状態遷移を定義します。ALPSでは、操作は以下の種類に分かれます:
| 操作 | メソッド | HTTP メソッド説明 |
| safe | GET | アプリケーションの状態のみを変更 |
| unsafe | POST | 新しいリソース状態を作成 |
| idempotent | PUT/DELETE | リソース状態を更新/削除 |
safe(安全)- アプリケーション状態のみが変化します(例:GET)
- リソース状態は変更されません
unsafe(非安全)- 新しいリソース状態を作成します
- 実行するたびに結果が異なる可能性があります
idempotent(べき等)- リソース状態を更新または削除します
- 何度実行しても同じ結果になります
ALPSの操作はリソースの変更を、追加操作のように実行するたびに結果が異なる、つまりべき等性がない操作か、変更や削除のように何度繰り返しても結果が変わらない、つまりべき等性がある操作を区別します。
記事を閲覧する遷移を定義する
まず、ブログ記事を閲覧する操作(safe)を定義します:
XMLの場合:
<?xml version="1.0" encoding="UTF-8"?>
<alps
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="https://alps-io.github.io/schemas/alps.xsd">
<descriptor id="dateCreated" title="作成日時">
<doc format="text">記事が作成された日時をISO8601形式で表します</doc>
</descriptor>
<descriptor id="articleBody" title="記事本文">
<doc format="text">ブログ記事の本文</doc>
</descriptor>
<descriptor id="BlogPosting" title="ブログ記事">
<descriptor href="#dateCreated"/>
<descriptor href="#articleBody"/>
</descriptor>
<descriptor id="goBlogPosting" type="safe" rt="#BlogPosting" title="ブログ記事を見る">
<descriptor href="#dateCreated"/>
</descriptor>
</alps>
JSONの場合:
{
"$schema": "https://alps-io.github.io/schemas/alps.json",
"alps": {
"version": "1.0",
"descriptor": [
{"id": "dateCreated", "title": "作成日時", "doc": {"format": "text", "value": "記事が作成された日時をISO8601形式で表します"}},
{"id": "articleBody", "title": "記事本文", "doc": {"format": "text", "value": "ブログ記事の本文"}},
{"id": "BlogPosting", "title": "ブログ記事", "descriptor": [
{"href": "#dateCreated"},
{"href": "#articleBody"}
]},
{"id": "goBlogPosting", "type": "safe", "rt": "#BlogPosting", "title": "ブログ記事を見る", "descriptor": [
{"href": "#dateCreated"}
]}
]
}
}
この定義で重要な要素:
- 命名規則のプレフィックス
- safe遷移では
goを使用します - unsafe遷移では
doCreateを使用します - idempotent遷移では
doUpdate/doDeleteを使用します
- safe遷移では
type属性- 操作の種類を指定します
- ここでは
safe(安全な遷移)です
rt(return type)属性- 遷移先の状態を指定します
#BlogPostingへの遷移を示します
- 遷移に必要な情報
descriptor href="#dateCreated"で指定します- 記事を特定するために必要な情報です
プレビュー画面では:
- 状態遷移図に状態(BlogPosting)と遷移を示す矢印が表示されます
- ボキャブラリリストに遷移(goBlogPosting)の情報が表示されます
記事を作成する遷移を定義する
続いて、記事を作成する操作(unsafe)を追加します:
XMLの場合:
<descriptor id="doCreateBlogPosting" type="unsafe" rt="#BlogPosting" title="ブログ記事を作成する">
<descriptor href="#articleBody"/>
</descriptor>
JSONの場合:
{"id": "doCreateBlogPosting", "type": "unsafe", "rt": "#BlogPosting", "title": "ブログ記事を作成する", "descriptor": [
{"href": "#articleBody"}
]}
ここで、閲覧(safe)と作成(unsafe)の違いに注目してください:
- 必要な情報
- 閲覧:dateCreated(記事を特定)
- 作成:articleBody(記事の内容)
- 状態の変化
- 閲覧:アプリケーション状態のみ
- 作成:リソース状態も変化
- 実行結果
- 閲覧:何度実行しても同じ
- 作成:実行ごとに新しい記事が作られる
次のステップでは、これらの遷移をブログ全体の構造に組み込んでいきます。
タクソノミー(2):操作を含む構造化
ここまでで定義した用語と操作を組み合わせ、ブログ全体を表現する構造を定義します。
XMLの場合:
<?xml version="1.0" encoding="UTF-8"?>
<alps
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="https://alps-io.github.io/schemas/alps.xsd">
<descriptor id="dateCreated" title="作成日時">
<doc format="text">記事が作成された日時をISO8601形式で表します</doc>
</descriptor>
<descriptor id="articleBody" title="記事本文">
<doc format="text">ブログ記事の本文</doc>
</descriptor>
<descriptor id="BlogPosting" title="ブログ記事">
<descriptor href="#dateCreated"/>
<descriptor href="#articleBody"/>
</descriptor>
<descriptor id="goBlogPosting" type="safe" rt="#BlogPosting" title="ブログ記事を見る">
<descriptor href="#dateCreated"/>
</descriptor>
<descriptor id="doCreateBlogPosting" type="unsafe" rt="#BlogPosting" title="ブログ記事を作成する">
<descriptor href="#articleBody"/>
</descriptor>
<descriptor id="Blog" title="ブログ">
<descriptor href="#BlogPosting"/>
<descriptor href="#goBlogPosting"/>
<descriptor href="#doCreateBlogPosting"/>
</descriptor>
</alps>
JSONの場合:
{
"$schema": "https://alps-io.github.io/schemas/alps.json",
"alps": {
"version": "1.0",
"descriptor": [
{"id": "dateCreated", "title": "作成日時", "doc": {"format": "text", "value": "記事が作成された日時をISO8601形式で表します"}},
{"id": "articleBody", "title": "記事本文", "doc": {"format": "text", "value": "ブログ記事の本文"}},
{"id": "BlogPosting", "title": "ブログ記事", "descriptor": [
{"href": "#dateCreated"},
{"href": "#articleBody"}
]},
{"id": "goBlogPosting", "type": "safe", "rt": "#BlogPosting", "title": "ブログ記事を見る", "descriptor": [{"href": "#dateCreated"}]},
{"id": "doCreateBlogPosting", "type": "unsafe", "rt": "#BlogPosting", "title": "ブログ記事を作成する", "descriptor": [{"href": "#articleBody"}]},
{"id": "Blog", "title": "ブログ", "descriptor": [
{"href": "#BlogPosting"},
{"href": "#goBlogPosting"},
{"href": "#doCreateBlogPosting"}
]}
]
}
}
Blogの構成要素
このBlogの定義には以下の要素が含まれています:
- 情報構造
- BlogPosting:ブログ記事の構造
- 状態遷移
- goBlogPosting:記事の閲覧操作(safe)
- doCreateBlogPosting:記事の作成操作(unsafe)
プレビュー画面では:
- 状態遷移図
- Blog、BlogPostingが状態として表示されます
- 状態間の遷移が矢印として表示されます
- safe遷移とunsafe遷移が異なるスタイルで表現されます
- ボキャブラリリスト
- 定義した全ての要素が階層的に表示されます
- Blog配下の情報構造と操作が確認できます
1. オントロジー(用語の定義)
XMLの場合:
<descriptor id="dateCreated" title="作成日時">
<doc format="text">記事が作成された日時をISO8601形式で表します</doc>
</descriptor>
JSONの場合:
{"id": "dateCreated", "title": "作成日時", "doc": {"format": "text", "value": "記事が作成された日時をISO8601形式で表します"}}
- アプリケーションで使用する言葉の意味を定義します
id、title、docを使って表現します
2. タクソノミー(情報の構造化)
XMLの場合:
<descriptor id="BlogPosting" title="ブログ記事">
<descriptor href="#dateCreated"/>
<descriptor href="#articleBody"/>
</descriptor>
JSONの場合:
{"id": "BlogPosting", "title": "ブログ記事", "descriptor": [
{"href": "#dateCreated"},
{"href": "#articleBody"}
]}
- 用語を組み合わせて構造を定義します
descriptorとhrefによる参照で表現します
3. コレオグラフィー(状態遷移)
XMLの場合:
<descriptor id="goBlogPosting" type="safe" rt="#BlogPosting" title="ブログ記事を見る">
<descriptor href="#dateCreated"/>
</descriptor>
JSONの場合:
{"id": "goBlogPosting", "type": "safe", "rt": "#BlogPosting", "title": "ブログ記事を見る",
"descriptor": [{"href": "#dateCreated"}]}
- 操作の種類を定義します
- safe:閲覧操作(prefixは
go) - unsafe:作成操作(prefixは
doCreate) - idempotent:更新・削除操作(prefixは
update/delete)
リンク関係の指定
これらの遷移の種類に加えて、標準的なリンク関係をrel属性で指定できます:
XMLの場合:
<descriptor id="goBlogPosting" type="safe" rt="#BlogPosting" rel="item" title="記事を見る">
<descriptor href="#id"/>
</descriptor>
<descriptor id="returnToBlog" type="safe" rt="#Blog" rel="collection" title="記事リストに戻る"/>
JSONの場合:
{
"$schema": "https://alps-io.github.io/schemas/alps.json",
"alps": {
"descriptor": [
{"id": "goBlogPosting", "type": "safe", "rt": "#BlogPosting", "rel": "item", "title": "記事を見る", "descriptor": [
{"href": "#id"}
]},
{"id": "returnToBlog", "type": "safe", "rt": "#Blog", "rel": "collection", "title": "記事リストに戻る"}
]
}
}
rel属性には以下のいずれかを指定できます:
- IANAで定義されたリンク関係
collection:コレクションへのリンク(例:記事リストへの遷移)item:個別アイテムへのリンク(例:個別記事への遷移)next/prev:ページネーションedit:リソースの編集
- 完全なURL(絶対URI)
- カスタムのリンク関係を定義する場合に使用します
- 例:
rel="https://example.com/rels/custom-relation"
リンク関係を指定することで、APIの意図がより明確になり、クライアントが適切な振る舞いを選択できるようになります。
4. 統合(タクソノミー2)
XMLの場合:
<descriptor id="Blog" title="ブログ">
<descriptor href="#BlogPosting"/>
<descriptor href="#goBlogPosting"/>
<descriptor href="#doCreateBlogPosting"/>
</descriptor>
JSONの場合:
{"id": "Blog", "title": "ブログ", "descriptor": [
{"href": "#BlogPosting"},
{"href": "#goBlogPosting"},
{"href": "#doCreateBlogPosting"}
]}
- 情報構造と操作を組み合わせて完全な定義を作成します
- リソースの全体構造を表現します
要素の分類とグループ化
tag属性を使って要素を分類できます:
XMLの場合:
<descriptor id="BlogPosting" title="ブログ記事">
<descriptor href="#dateCreated" tag="metadata"/>
<descriptor href="#articleBody" tag="content"/>
<descriptor href="#goBlogPosting" tag="navigation"/>
<descriptor href="#doCreateBlogPosting" tag="action"/>
</descriptor>
JSONの場合:
{
"id": "BlogPosting",
"title": "ブログ記事",
"descriptor": [
{"href": "#dateCreated", "tag": "metadata"},
{"href": "#articleBody", "tag": "content"},
{"href": "#goBlogPosting", "tag": "navigation"},
{"href": "#doCreateBlogPosting", "tag": "action"}
]
}
tagによる分類は以下のような目的で使用できます:
- 情報の種類の明確化
metadata:作成日時などのメタ情報content:実際のコンテンツnavigation:ナビゲーション要素action:状態を変更する操作
- 処理の分類
validation:検証が必要な項目required:必須項目cache:キャッシュ可能な情報
タグは複数指定することもできます:
XMLの場合:
<descriptor href="#title" tag="metadata content"/>
JSONの場合:
{"href": "#title", "tag": "metadata content"}
まとめ:設計手法としてのALPS
ここまで、ブログシステムを例にALPSによる設計手法を学んできました。 この手法には以下のような利点があります:
- API設計の明確化
- 意味、構造、遷移の一貫した定義
- 設計の意図の共有
- 実装の指針
- ドキュメントとしての役割
- 視覚的な状態遷移の理解
- 用語の定義の明確化
- チーム内での共通理解
- 実装との対応
- HTTPメソッドとの明確な関係(safe→GET, unsafe→POST, idempotent→PUT/DELETE)
- URLによる状態の表現
- RESTful APIの設計指針
チュートリアルの次のステップ
このチュートリアルで学んだ知識は、以下のような形で活用できます:
- 既存アプリケーションのALPSによる記述
- 現在の設計の可視化と理解
- 改善ポイントの発見
- ドキュメントの整備
- 新規APIの設計とALPSの連携
- 一貫性のある設計の実現
- クライアントとの効果的なコミュニケーション
- メンテナンス性の向上
ALPSを使った設計は、当初は手間がかかるように感じるかもしれません。しかし、プロジェクトの規模が大きくなるにつれて、その価値は明確になっていきます。一貫性のある設計、明確なドキュメント、効果的なコミュニケーションは、長期的なプロジェクトの成功に大きく貢献します。