This page collects all BEAR.Sunday manuals in one place.
Advanced Implementation Guide
Overview
This document describes more advanced implementation topics for Application-Level Profile Semantics (ALPS). For a description of basic elements and attributes, please refer to the ALPS Reference.
Descriptors and Link Relation Types
When including state transitions in representations, valid values for link relation types can be any of the following:
- Standard Link Relation Types
- Short strings registered in registries like IANA or Microformats.org
- Example:
rel="edit",rel="next",rel="collection" - See IANA Link Relations
- Extended Link Relation Types ([RFC8288])
- Fully qualified URI for a document describing the relation type
- Contains a URI fragment identifier for an ALPS descriptor
- Example:
rel="http://alps.io/profiles/item#purchased-by" - Example:
rel="http://alps.io/profiles/blog#comment"
- ALPS Descriptor ID
idattribute value of a state transition descriptor in an ALPS document- Usable only if the representation includes an ALPS profile
- Example:
rel="purchased-by" - Example:
rel="create-comment"
Resolving Link Relation Conflicts
- Conflicts with Standard Relations
- If a state transition descriptor has the same meaning as a standard link relation, do not change its meaning
- Example: When creating a descriptor named
edit, it must match the meaning of theeditrelation registered with IANA
- Resolving ID Conflicts
- When conflicts occur between multiple descriptors with the same ID:
- Define a unique ID
- Use the
nameattribute to retain the original name if necessary
- Example:
<descriptor id="user-edit" name="edit" type="safe"> <doc>Edit user information</doc> </descriptor>
- When conflicts occur between multiple descriptors with the same ID:
Integration with Existing Media Types
ALPS can be used in combination with various existing media types. Below, we explain how to integrate with major media types.
HTML
In HTML, ALPS descriptors are primarily represented using the class attribute:
<div class="blog-post">
<h1 class="title">Article Title</h1>
<div class="content">Content...</div>
<form class="add-comment" method="post">
<input name="comment-text" class="comment-text">
<button type="submit">Add Comment</button>
</form>
</div>
Corresponding ALPS profile:
<alps version="1.0">
<descriptor id="blog-post" type="semantic">
<descriptor id="title" type="semantic"/>
<descriptor id="content" type="semantic"/>
<descriptor id="add-comment" type="unsafe">
<descriptor id="comment-text" type="semantic"/>
</descriptor>
</descriptor>
</alps>
HAL (Hypertext Application Language)
In HAL, state transitions are expressed as link relations and semantic descriptors as properties:
{
"_links": {
"self": {"href": "/posts/1"},
"add-comment": {"href": "/posts/1/comments"}
},
"title": "Article Title",
"content": "Content...",
"_embedded": {
"comments": [
{
"_links": {
"self": {"href": "/comments/1"}
},
"text": "Comment content..."
}
]
}
}
Collection+JSON
In Collection+JSON, descriptors are expressed as queries and data elements:
{
"collection": {
"version": "1.0",
"href": "/posts/1",
"items": [
{
"data": [
{"name": "title", "value": "Article Title"},
{"name": "content", "value": "Content..."}
]
}
],
"template": {
"data": [
{"name": "comment-text", "value": "", "prompt": "Enter a comment"}
]
}
}
}
Referencing ALPS Documents
This section describes how to reference ALPS profiles when applying them.
Referencing by Link
- Referencing in HTML
<link rel="profile" href="http://example.com/alps/blog" /> - Referencing in HTTP Link Header
Link: <http://example.com/alps/blog>; rel="profile" - Referencing in Media Type Parameter
Content-Type: application/json; profile="http://example.com/alps/blog"
Applying Multiple Profiles
Multiple ALPS profiles can be applied to a single representation:
Link: <http://example.com/alps/blog>; rel="profile",
<http://example.com/alps/comments>; rel="profile"
Profile Priority
Priority when multiple profiles conflict:
- Profiles specified in the
profileparameter of the media type - Profiles specified in the HTTP
Linkheader - Profiles specified in the representation itself (priority given to those specified first)
Error Handling and Validation
This section describes common error cases and how to handle them during implementation.
Common Errors
- Invalid Descriptor Reference
- URLs or fragment identifiers that cannot be resolved
- References to non-existent descriptors
- Link Relation Conflict
- Conflicts in meaning with standard relations
- Conflicts between relation definitions in multiple profiles
- Media Type Constraints
- Presence of elements that cannot be expressed in a particular media type
- Lack of support for link expressions
Best Practices
State
Application state semantic descriptors are represented in UpperCamelCase starting with a capital letter.
"descriptor": [
{"id": "BlogPosting", "type": "semantic", "def": "https://schema.org/BlogPosting", "descriptor": [
{"href": "#id"},
{"href": "#articleBody"},
{"href": "#dateCreated"},
{"href": "#blog"}
]}
]
Safe State Transitions
Semantic descriptors with type safe add the prefix go to the destination descriptor.
(RFC8288)
[
{"id": "goHome", "type": "safe", "rt": "#Home"},
{"id": "goFirst", "type": "safe", "rt": "#TodoList"},
{"id": "goPrevious", "type": "safe", "rt": "#TodoList"}
]
Semantic descriptors that are not safe should use the prefix do.
[
{"id": "doEditUser", "type": "idempotent", "rt": "#UserList"},
{"id": "doDeleteUser", "type": "idempotent", "rt": "#UserList"}
]
The rt (transition destination) ID is formed by adding the destination descriptor ID to the prefix go or do.
[
{"id": "goBlogPosting", "type": "safe", "rt": "#BlogPosting"},
{"id": "doEditBlogPosting", "type": "idempotent", "rt": "#Blog"}
]
Elements
Semantic descriptors that are not defined as application states, i.e., elements, are written in lowerCamelCase starting with a lowercase letter.
[
{"id": "articleBody"},
{"id": "dateCreated"}
]
ALPS File Structure
The semantic descriptors in ALPS files are divided into three blocks in the following order:
- Semantic descriptor groups with meaning definitions using
defanddoc(ontology) - Semantic descriptor groups with inclusion relationships (taxonomy)
- State transition semantic descriptor groups (choreography)
{"descriptor" : [
{"id" : "name", "type" : "semantic", "def": "http://schema.org/identifier"},
{"id" : "age", "type" : "semantic", "def": "http://schema.org/title"},
{"id" : "Person", "type": "semantic", "descriptor":[
{"href": "#name"},
{"href": "#age"}
]}
{"id": "goPerson", "type": "safe", "rt": "#Person"},
]
Hierarchical Structure Outside ALPS
In ALPS, hierarchical meanings can be expressed by position.
{"descriptor": [
{"id": "name", "def": "https://schema.org/name"},
{"id": "Product", "descriptor":[
{"href": "#name"}
]}
{"id": "Person", "descriptor":[
{"href": "#name"}
]}
]
- In the example above,
nameis shared betweenProduct/nameandPerson/name. - When expressing such terms in formats with only flat hierarchies, it’s basic practice to follow the conventions of each format.
- In HTML, they are expressed in lower camel case.
<form>
<input name="productName" type="text">
<input name="personName" type="text">
</form>
Adding Schema References
When creating ALPS profiles, it is recommended to add schema references.
{
"$schema": "https://alps-io.github.io/schemas/alps.json",
"alps" : {
}
}
<alps
version="1.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="https://alps-io.github.io/schemas/alps.xsd">
</alps>
Implementation Examples
Semantic Elements
Basic element definitions:
<descriptor id="title" title="Title" doc="Article title. Maximum 100 characters."/>
<descriptor id="content" title="Content" doc="Article body. Supports Markdown format."/>
<descriptor id="publishedAt" title="Publication Date" doc="Article publication date and time. ISO 8601 format."/>
{"descriptor": [
{"id": "title", "title": "Title", "doc": {"value": "Article title. Maximum 100 characters."}},
{"id": "content", "title": "Content", "doc": {"value": "Article body. Supports Markdown format."}},
{"id": "publishedAt", "title": "Publication Date", "doc": {"value": "Article publication date and time. ISO 8601 format."}}
]}
Reusing basic elements:
<descriptor id="blogPost">
<doc>User-created article. After publication, visible to all users.</doc>
<descriptor href="#title"/>
<descriptor href="#content"/>
<descriptor href="#publishedAt"/>
</descriptor>
<descriptor id="pagePost">
<doc>Static page. Permanent content such as site basic information.</doc>
<descriptor href="#title"/>
<descriptor href="#content"/>
</descriptor>
{"descriptor": [
{"id": "blogPost", "doc": {"value": "User-created article. After publication, visible to all users."}, "descriptor": [
{"href": "#title"},
{"href": "#content"},
{"href": "#publishedAt"}
]},
{"id": "pagePost", "doc": {"value": "Static page. Permanent content such as site basic information."}, "descriptor": [
{"href": "#title"},
{"href": "#content"}
]}
]}
Operation Definitions
<descriptor id="goBlog" type="safe" rt="#Blog" doc="Display blog homepage. Shows latest 10 articles."/>
<descriptor id="doCreateBlogPost" type="unsafe" rt="#BlogPost">
<doc>Create new article. Saved in draft state.</doc>
<descriptor href="#title"/>
<descriptor href="#content"/>
</descriptor>
<descriptor id="doPublishBlogPost" type="idempotent" rt="#BlogPost">
<doc>Publish article. Current time is set to publishedAt.</doc>
<descriptor href="#id"/>
</descriptor>
{"descriptor": [
{"id": "goBlog", "type": "safe", "rt": "#Blog", "doc": {"value": "Display blog homepage. Shows latest 10 articles."}},
{"id": "doCreateBlogPost", "type": "unsafe", "rt": "#BlogPost", "doc": {"value": "Create new article. Saved in draft state."}, "descriptor": [
{"href": "#title"},
{"href": "#content"}
]},
{"id": "doPublishBlogPost", "type": "idempotent", "rt": "#BlogPost", "doc": {"value": "Publish article. Current time is set to publishedAt."}, "descriptor": [
{"href": "#id"}
]}
]}
Exmaple
FAQ
Q. Who can use the software?
A. It can be used by anyone involved in site creation (engineers, designers, POs).
Q. What kind of people can write ALPS?
A. Anyone who can understand XML and JSON and can do simple HTML coding can write ALPS.
Q. How do you use it?
A. It is used to design a site by organizing information into the minimum necessary elements, and to design web and API services. The design can be expressed in formats such as JSON and XML, and documents such as transition diagrams and vocabulary lists can be generated. In addition, each producer can know the exact words, meanings and structures of information based on the information design.
Q. What is information design?
A. Based on IA (Information Architecture), it defines the information (meta-information) of information in terms of ontology (meaning of words), taxonomy (classification of information), and choreography (links).
Q. Is it used for design clarification?
A. No, it is not. It can be used as a modeling tool from the very early stage of site design to organize information and formulate what kind of site it will be.
Q. What do I need to write ALPS?
A. You need an editor to edit JSON and XML.
Q. Isn’t it hard to edit XML and JSON directly?
A. If you use an editor that supports schemas such as WebStorm, you can edit them comfortably with completion and validation.
Q. Which is better, XML or JSON?
A. There is no difference in functionality. There is also no need to unify them when using multiple ALPS files. Please compare them in practice. XML / JSON JSON
Q. Can it be used for APIs without links?
A. Yes. It cannot represent a transition diagram, but it can generate a vocabulary and documentation of the nature of the information.
Q. Are there any other technologies that are similar to ALPS?
A. There are no direct competitors. A similar technology is Microformat.
Q. What is the difference from IDL such as OpenAPI?
A. ALPS deals with REST abstractions that are higher than HTTP. Therefore, it can be used as a modeling and design language for OpenAPI implementations.
Q. Do I need it?
A. If you want to model information to improve the quality of user experience, or if you want a reference (SSOT) to unify the understanding among production members, or if you want to overview and reuse your design, or if you want to keep your information design as a standardized document, ALPS+ASD will be useful as your information design modeling tool or as a format to express it.
VERY IMPORTANT:
ALPS is pronounced ‘alps’, the same as the Swiss alps. It is not A-L-P-S. “ælps”
VERY IMPORTANT:
ALPS is pronounced ‘alps’, the same as the Swiss alps. It is not A-L-P-S. “ælps”
VERY IMPORTANT:
ALPS is pronounced ‘alps’, the same as the Swiss alps. It is not A-L-P-S. “ælps”
VERY IMPORTANT:
ALPS is pronounced ‘alps’, the same as the Swiss alps. It is not A-L-P-S. “ælps”
Information Architecture and ALPS
Applying Information Architecture (IA) concepts to domain modeling in API design and system development enables systematic organization of business requirements. The elements of IA—”meaning,” “structure,” and “interaction”—originally developed in UX and content design, play a crucial role in structuring business domain knowledge. ALPS provides a standardized method to express these concepts.
Applying Information Architecture
Information Architecture expert Dan Klyn defined IA as the interplay of Ontology, Taxonomy, and Choreography. 1 These concepts serve as a foundation not only for content design but also for system design. While OpenAPI focuses on technical API details (endpoints, HTTP methods, request/response structures), ALPS uses these IA concepts to structure the business domain.
Role in the Design Process
ALPS bridges business requirements and system design from the early stages of development. Unlike traditional endpoint-centric design, which typically starts with documenting predetermined API specifications, ALPS can be utilized from the requirements definition phase. This enables early detection and correction of differences in business requirement interpretations. It also establishes a common language between technical and business teams, providing a framework for easily understanding the scope of design changes.
ALPS goes beyond API endpoint design to provide a means of systematizing and sharing business domain knowledge. As a Single Source of Truth (SSOT), it consistently models system structure and behavior. Using business terminology at its core, it clearly expresses complex business rules, visualizes workflows, and enables intuitive understanding of information interactions.
Adapting to Technical Changes
ALPS offers flexibility in its application to various API styles. Even as technology evolves and architecture styles change, business domain design can be maintained. For example, whether transitioning from RESTful APIs to GraphQL, adopting microservice architecture, or implementing new communication protocols, domain models defined in ALPS remain valid. This is because ALPS focuses on abstracted business logic rather than implementation details.
Building Knowledge Foundation
In the implementation of Taxonomy, relationships between business entities are defined, ensuring scalability through hierarchical structure. This establishes a common vocabulary across the organization, streamlining communication. Choreography defines business process flows and service coordination rules, enhancing system-wide consistency and reliability.
Applying IA concepts to domain modeling naturally connects technical implementation with business requirements. ALPS functions as a framework to achieve this bridge, serving as a foundation for systematically structuring and evolving organizational knowledge.
Through this approach, organizations can build a sustainable knowledge foundation that remains resilient to technological changes.
IANA Link Relations
This document lists IANA link relations recommended for use in the rel attribute of ALPS profiles.
State Transitions
| Relation | Description |
|---|---|
| first | Transition to the first state in a series |
| last | Transition to the last state in a series |
| next | Transition to the next state in a series |
| prev | Transition to the previous state in a series |
Semantic Description
| Relation | Description |
|---|---|
| section | Indicates a section in a document |
| subsection | Indicates a subsection in a document |
| chapter | Indicates a chapter in a document |
| contents | Indicates the table of contents of a document |
Metadata
| Relation | Description |
|---|---|
| latest-version | Transition to the latest version state |
| predecessor-version | Transition to the previous version state |
| successor-version | Transition to the next version state |
| version-history | Transition to a state showing version history |
Related Information
| Relation | Description |
|---|---|
| help | Reference to help information |
| status | Reference to state information |
| alternate | Reference to alternative representation |
Notes:
- This list is an excerpt of relations that are likely to be commonly used in ALPS profiles
- For a complete list, refer to IANA Registry
- The categorization is for convenience
- When using these relations, please select appropriate ones according to your application requirements
Introduction

ALPS: A Format for Clarifying Application-Level Meaning and Structure
Application-Level Profile Semantics (ALPS) is a format that expresses application-level semantics and adds application-specific information to generic media such as JSON and HTML. ALPS clarifies the meaning, structure, and operations of data, enabling efficient development processes, enhanced system interoperability, and improved API reusability and discoverability.
Consider an e-commerce platform as an example. When integrating multiple payment services such as credit cards, digital money, and bank transfers, ALPS standardizes the meaning of data and operations at each step of the payment process. This makes it easier to add new payment methods and integrate with existing systems, allowing developers to implement APIs consistently. Frontend and backend developers can communicate efficiently using a common language, enabling rapid feature additions and improvements.
ASD: Visualizing Application State Transitions
Application State Diagram (ASD) is a tool that visualizes state transitions and behaviors from ALPS documents. It enables intuitive understanding of an application’s overall structure, state transitions, and possible actions. For example, in an online shopping application, it clearly visualizes the process from product search to purchase, helping developers understand the choices and possible operations users face at each stage. This aids in making design decisions that enhance the user experience.
With ASD, all team members—including product owners, backend and frontend developers, and UI/UX designers—can understand the application from the same perspective and work together effectively. This enables smooth communication between members from different specialties and helps new members quickly integrate into complex projects. Furthermore, it allows quick evaluation and adjustment of application flows and logic, providing opportunities to identify and resolve issues early in the design phase, directly contributing to improved development efficiency and application quality.
Through the use of ASD, project transparency increases, minimizing discrepancies in vision among team members.
Information Architecture for REST Application Design
When designing REST applications from an information architecture perspective, ALPS and ASD complement each other in their roles. ALPS standardizes the meaning and structure of data handled by applications, enabling teams to define information using a common vocabulary. ASD, on the other hand, represents state changes in diagrams, making it easy to visually understand user operations and application responses. Through ALPS specifications and ASD visualization, information design in REST application development is strengthened, team communication becomes smoother, and the overall project consistency and quality are enhanced.
To improve development efficiency, deliver excellent user experiences, and ensure project sustainability, a shared understanding among diverse developers is essential. ALPS and ASD build this foundation and support the long-term success of projects.
Introduction

ALPS: A way to organize app information
ALPS (Application Level Profile Semantics) is a way to neatly describe the information and mechanics of an app. It adds app-specific information to formats commonly used on the Internet (e.g., JSON and HTML) to clarify how the app works and what information it handles. This will make the process of creating the app smoother and allow different apps and systems to work well together.
For example, consider an online shopping site. For the sequence of steps (including payment) that a customer goes through to select and buy a product, ALPS can clearly show what is happening at each step. This makes it easier for those who create the app to make the necessary improvements to ensure a smooth shopping experience for customers.
ASD: Diagrams showing how the app works
The ASD (Application State Transition Diagram) shows a diagram of how the app moves and the operations the user can perform based on the app information described in the ALPS. This allows you to understand at a glance how the app is working. In the case of an online shopping site, the diagram shows a series of steps, such as searching for a product, adding it to the cart, and paying for it.
ASD allows people in different roles in the team building the app, such as programmers and designers, to have a common understanding of how the app should work. This can be very helpful in discussions about how to improve the app and in coming up with new ideas.
Designing REST Applications
ALPS and ASD are especially useful for designing apps that run on the web (called REST applications). Using these tools, you can clearly show what information the app handles and how it works. The result is an app that is easier to create and improve, and more user-friendly for the people using it.
In order for team members with diverse skills to work efficiently toward the same goal, it is important that they understand exactly what each other is working on, and ALPS and ASD are very useful tools to help them achieve this understanding.
Resource
- ALPS official
- RFC
- Skeleton
- GitHub Action
- app-state-diagram
ALPS Prompt Creation
Paste your existing ALPS profile below and proceed directly to the format conversion step.
Convert ALPS to Implementation Format
Generated ALPS Prompt
💡 Pro Tip: After receiving your ALPS profile from the AI, consider asking: "Please review this ALPS profile to verify that there are no isolated states (unreachable or exit-less states) and that all state transitions are properly connected. Also check if all semantic descriptors are consistently tagged and grouped."
💡 Next Step: After confirming that ALPS is rendered correctly at https://editor.app-state-diagram.com/, Paste your ALPS profile into textarea and proceed directly to the format conversion step.
Select Target Implementation Format
Generated Conversion Prompt
Copy this prompt to ChatGPT, Claude, or any other AI assistant:
💡 Remember: For best results, first have the AI verify the ALPS profile for correctness, then provide this conversion prompt.
Tip: For quick results, you can also use ALPS Assistant GPTs with your prompts.
Installation and Usage Guide
ASD (app-state-diagram) is a tool for creating comprehensive ALPS documentation that includes application state transition diagrams and vocabulary lists. It can be used in the following ways:
Choosing Usage Method
1. Online Version
Use immediately without local installation:
Features:
- No installation required
- Immediately available in browser
- JSON/XML/HTML files can be loaded via drag & drop
- Snippets and advanced code completion
- Recommended option when local installation is not needed
- Note: Currently unable to edit multiple files simultaneously
2. Homebrew Version
Easiest to use in environments where homebrew is installed.
Installation:
brew install alps-asd/asd/asd
3. Docker Version
Download and run a script to execute in Docker. Follow these security verification steps as this involves downloading and running a shell script.
Security Verification Steps
- Review script content (recommended):
curl -sL https://alps-asd.github.io/app-state-diagram/asd.sh | less
- Verify checksum:
curl -sL https://alps-asd.github.io/app-state-diagram/asd.sh | sha256sum
Expected value:
0f05034400b2e7fbfee6cddfa9dceb922e51d93fc6dcda62e42803fb8ef05f66
- Execute installation:
sudo curl -sL https://alps-asd.github.io/app-state-diagram/asd.sh -o /usr/local/bin/asd
sudo chmod +x /usr/local/bin/asd
Prerequisites
- Docker must be installed
- curl command must be available
4. Mac Launcher Application (GUI Version)
A Mac GUI application that doesn’t require command line operations.
Installation steps:
- Download ASD launcher
- Security verification:
- View the downloaded files and verify the contents before proceeding
- Verify the checksum (SHA-256):
shasum -a 256 [downloaded zip file] - Compare with the expected checksum on the official repository: 659ecc3225b95a04f0e2ac4ebed544267ba78a0221db7ed84b6dfd7b08ce423b
- Open the verified script in Script Editor:
- If you get a security warning, right-click (or Control-click) the script and select “Open”
- In System Settings > Privacy & Security, click “Open Anyway” if prompted
- Select “File” > “Export…”
- Save location: “Applications”
- Save as Format: “Application”
5. GitHub Actions Version
Create ASD in CI. See marketplace for details.
6. VSCode Plugin
You can live edit ALPS files while viewing the preview screen using the VSCode Plugin (experimental).
Visual Studio Marketplace - Application State Diagram
Usage
Running Demo
# Download and run demo file
curl -L https://alps-asd.github.io/app-state-diagram/blog/profile.json > alps.json
asd -w ./alps.json
Command Line Options
asd [options] [alpsFile]
Options:
-w, --watch Watch mode
-m, --mode Drawing mode
--port Port to use (default 3000)
Mode Settings
- Markdown mode available for use with private repositories
- However, diagram links don’t function in Markdown mode
- Use as alternative option when HTML cannot be published
Installation Verification
asd
usage: asd [options] alps_file
@see https://github.com/alps-asd/app-state-diagram#usage
Selection Guidelines
- Quick trial, temporary use → Online version
- Local use on Mac → Homebrew version
- Cross-platform use → Docker version
- Mac local environment with GUI → Launcher application
- CI/CD environment use → GitHub Actions version
ALPS Reference
Overview
Application-Level Profile Semantics (ALPS) is a document format for describing application semantics. This document explains the elements and attributes of ALPS.
Document Structure
ALPS documents have the following hierarchical structure:
- Root Element (
alps)- The root element of the document containing version information
- All definitions are contained within this element
- Descriptor Element (
descriptor)- The central element that defines the meaning of application features and information
- There are four types:
- semantic: Represents information or terminology (default)
- safe: Read operations (does not change resource state)
- idempotent: Operations that produce the same result when executed multiple times (e.g., complete replacement with PUT or removal with DELETE)
- unsafe: Operations that produce different results when executed multiple times (e.g., creation with POST, numeric addition, etc.)
- Can contain other descriptor elements as child elements
- Can contain link elements as child elements
- Supplementary Elements
doc: Detailed explanations or supplementary informationlink: References to related documentstitle: Description of the profile
Representation Formats
ALPS documents can be written in the following two formats:
XML Format
<?xml version="1.0" encoding="UTF-8"?>
<alps version="1.0">
<title>Blog API Profile</title>
<doc>API profile for a blog system</doc>
<descriptor id="title" title="Title" doc="Article title. Maximum 100 characters."/>
<descriptor id="blogPost">
<doc>Blog post</doc>
<descriptor href="#title"/>
<link rel="related" href="http://example.org/related-docs/blog.html" />
</descriptor>
</alps>
JSON Format
{
"alps": {
"version": "1.0",
"title": "Blog API Profile",
"doc": {"value": "API profile for a blog system"},
"descriptor": [
{"id": "title", "title": "Title", "doc": {"value": "Article title. Maximum 100 characters."}},
{"id": "blogPost", "doc": {"value": "Blog post"},
"descriptor": [
{"href": "#title"}
],
"link": [
{"rel": "related", "href": "http://example.org/related-docs/blog.html"}
]
}
]
}
}
Elements and Attributes in Detail
alps
The root element of an ALPS document.
Attributes:
- version: The document version (required)
descriptor
Defines the semantics (meaning) of application features or information. Either id or href is required, and other attributes are optional.
A descriptor can have the following child elements:
- descriptor: Other descriptor elements can be nested to represent hierarchical structures
- doc: Detailed description
- link: Links to related resources
- ext: Extension information
descriptor attributes list
| Attribute | Required | Type | Description | Example |
|---|---|---|---|---|
| href | optional | string | External document URL | "http://example.com/doc" |
| format | optional | string | Document format | "markdown" |
| contentType | optional | string | Content type | "text/html" |
| tag | optional | string | Classification tags | "api spec" |
| value | optional | string | Description text | "Detailed description" |
Format attribute support levels:
- text: Required support (MUST)
- html: Recommended support (SHOULD)
- asciidoc: Optional support (MAY)
- markdown: Optional support (MAY), compliant with [RFC7763]
Priority of contentType and format:
- If contentType exists, it is used
- If both contentType and format exist, format is ignored
- If neither exists, text/plain is assumed
link
Defines references to related documents. Link can be used as a child element of alps or descriptor elements.
link attributes list
| Attribute | Required | Type | Description | Example |
|---|---|---|---|---|
| id | required | string | Unique identifier for the extension | "range" |
| href | recommended | string | URL explaining the extension | "http://alps.io/ext/range" |
| value | optional | string | Extension value | "0,100" |
| tag | optional | string | Classification tags | "validation" |
Validation
- A descriptor requires either id or href
- href reference targets must be resolvable URLs and must include a fragment identifier
- rt transition targets must exist in the document
- The type attribute must be one of the four defined values (semantic, safe, idempotent, unsafe)
- The following prefixes are recommended for operation descriptors:
- safe:
go(e.g.,goBlog) - unsafe:
do(e.g.,doCreateBlog) - idempotent:
do(e.g.,doUpdateBlog)
- safe:
Hierarchical Structure Example
Below is a concise example of hierarchical structure using nested descriptor elements:
XML Format
<alps version="1.0">
<descriptor id="user" type="semantic">
<doc>User information</doc>
<descriptor id="name" type="semantic" />
<descriptor id="email" type="semantic" />
<link rel="help" href="http://example.org/help/user.html" />
</descriptor>
</alps>
JSON Format
{
"alps": {
"version": "1.0",
"descriptor": [
{
"id": "user",
"type": "semantic",
"doc": {"value": "User information"},
"descriptor": [
{"id": "name", "type": "semantic"},
{"id": "email", "type": "semantic"}
],
"link": [
{"rel": "help", "href": "http://example.org/help/user.html"}
]
}
]
}
}
Schema.org Terms
Properties
| Property | Description | Meta information |
|---|---|---|
| about | The subject matter of the content. | |
| abridged | Indicates whether the book is an abridged edition. | |
| abstract | An abstract is a short description that summarizes a CreativeWork. | |
| accelerationTime | The time needed to accelerate the vehicle from a given start velocity to a given target velocity. Typical unit code(s): SEC for seconds
|
|
| acceptedAnswer | The answer(s) that has been accepted as best, typically on a Question/Answer site. Sites vary in their selection mechanisms, e.g. drawing on community opinion and/or the view of the Question author. | |
| acceptedOffer | The offer(s) -- e.g., product, quantity and price combinations -- included in the order. | |
| acceptedPaymentMethod | The payment method(s) accepted by seller for this offer. | |
| acceptsReservations | Indicates whether a FoodEstablishment accepts reservations. Values can be Boolean, an URL at which reservations can be made or (for backwards compatibility) the strings Yes or No. |
|
| accessCode | Password, PIN, or access code needed for delivery (e.g. from a locker). | |
| accessMode | The human sensory perceptual system or cognitive faculty through which a person may process or perceive information. Expected values include: auditory, tactile, textual, visual, colorDependent, chartOnVisual, chemOnVisual, diagramOnVisual, mathOnVisual, musicOnVisual, textOnVisual. | |
| accessModeSufficient | A list of single or combined accessModes that are sufficient to understand all the intellectual content of a resource. Expected values include: auditory, tactile, textual, visual. | |
| accessibilityAPI | Indicates that the resource is compatible with the referenced accessibility API (WebSchemas wiki lists possible values). | |
| accessibilityControl | Identifies input methods that are sufficient to fully control the described resource (WebSchemas wiki lists possible values). | |
| accessibilityFeature | Content features of the resource, such as accessible media, alternatives and supported enhancements for accessibility (WebSchemas wiki lists possible values). | |
| accessibilityHazard | A characteristic of the described resource that is physiologically dangerous to some users. Related to WCAG 2.0 guideline 2.3 (WebSchemas wiki lists possible values). | |
| accessibilitySummary | A human-readable summary of specific accessibility features or deficiencies, consistent with the other accessibility metadata but expressing subtleties such as "short descriptions are present but long descriptions will be needed for non-visual users" or "short descriptions are present and no long descriptions are needed." | |
| accommodationCategory | Category of an Accommodation, following real estate conventions e.g. RESO (see PropertySubType, and PropertyType fields for suggested values). | |
| accommodationFloorPlan | A floorplan of some Accommodation. | |
| accountId | The identifier for the account the payment will be applied to. | |
| accountMinimumInflow | A minimum amount that has to be paid in every month. | |
| accountOverdraftLimit | An overdraft is an extension of credit from a lending institution when an account reaches zero. An overdraft allows the individual to continue withdrawing money even if the account has no funds in it. Basically the bank allows people to borrow a set amount of money. | |
| accountablePerson | Specifies the Person that is legally accountable for the CreativeWork. | |
| acquireLicensePage | Indicates a page documenting how licenses can be purchased or otherwise acquired, for the current item. | |
| acquiredFrom | The organization or person from which the product was acquired. | |
| acrissCode | The ACRISS Car Classification Code is a code used by many car rental companies, for classifying vehicles. ACRISS stands for Association of Car Rental Industry Systems and Standards. | |
| actionAccessibilityRequirement | A set of requirements that a must be fulfilled in order to perform an Action. If more than one value is specied, fulfilling one set of requirements will allow the Action to be performed. | |
| actionApplication | An application that can complete the request. | |
| actionOption | A sub property of object. The options subject to this action. | |
| actionPlatform | The high level platform(s) where the Action can be performed for the given URL. To specify a specific application or operating system instance, use actionApplication. | |
| actionStatus | Indicates the current disposition of the Action. | |
| actionableFeedbackPolicy | For a NewsMediaOrganization or other news-related Organization, a statement about public engagement activities (for news media, the newsroom’s), including involving the public - digitally or otherwise -- in coverage decisions, reporting and activities after publication. | |
| activeIngredient | An active ingredient, typically chemical compounds and/or biologic substances. | |
| activityDuration | Length of time to engage in the activity. | |
| activityFrequency | How often one should engage in the activity. | |
| actor | An actor, e.g. in tv, radio, movie, video games etc., or in an event. Actors can be associated with individual items or with a series, episode, clip. | |
| actors | An actor, e.g. in tv, radio, movie, video games etc. Actors can be associated with individual items or with a series, episode, clip. | |
| addOn | An additional offer that can only be obtained in combination with the first base offer (e.g. supplements and extensions that are available for a surcharge). | |
| additionalName | An additional name for a Person, can be used for a middle name. | |
| additionalNumberOfGuests | If responding yes, the number of guests who will attend in addition to the invitee. | |
| additionalProperty | A property-value pair representing an additional characteristics of the entitity, e.g. a product feature or another characteristic for which there is no matching property in schema.org. Note: Publishers should be aware that applications designed to use specific schema.org properties (e.g. https://schema.org/width, https://schema.org/color, https://schema.org/gtin13, ...) will typically expect such data to be provided using those properties, rather than using the generic property/value mechanism. |
|
| additionalType | An additional type for the item, typically used for adding more specific types from external vocabularies in microdata syntax. This is a relationship between something and a class that the thing is in. In RDFa syntax, it is better to use the native RDFa syntax - the 'typeof' attribute - for multiple types. Schema.org tools may have only weaker understanding of extra types, in particular those defined externally. | |
| additionalVariable | Any additional component of the exercise prescription that may need to be articulated to the patient. This may include the order of exercises, the number of repetitions of movement, quantitative distance, progressions over time, etc. | |
| address | Physical address of the item. | |
| addressCountry | The country. For example, USA. You can also provide the two-letter ISO 3166-1 alpha-2 country code. | |
| addressLocality | The locality in which the street address is, and which is in the region. For example, Mountain View. | |
| addressRegion | The region in which the locality is, and which is in the country. For example, California or another appropriate first-level Administrative division | |
| administrationRoute | A route by which this drug may be administered, e.g. 'oral'. | |
| advanceBookingRequirement | The amount of time that is required between accepting the offer and the actual usage of the resource or service. | |
| adverseOutcome | A possible complication and/or side effect of this therapy. If it is known that an adverse outcome is serious (resulting in death, disability, or permanent damage; requiring hospitalization; or is otherwise life-threatening or requires immediate medical attention), tag it as a seriouseAdverseOutcome instead. | |
| affectedBy | Drugs that affect the test's results. | |
| affiliation | An organization that this person is affiliated with. For example, a school/university, a club, or a team. | |
| afterMedia | A media object representing the circumstances after performing this direction. | |
| agent | The direct performer or driver of the action (animate or inanimate). e.g. John wrote a book. | |
| aggregateRating | The overall rating, based on a collection of reviews or ratings, of the item. | |
| aircraft | The kind of aircraft (e.g., "Boeing 747"). | |
| album | A music album. | |
| albumProductionType | Classification of the album by it's type of content: soundtrack, live album, studio album, etc. | |
| albumRelease | A release of this album. | |
| albumReleaseType | The kind of release which this album is: single, EP or album. | |
| albums | A collection of music albums. | |
| alcoholWarning | Any precaution, guidance, contraindication, etc. related to consumption of alcohol while taking this drug. | |
| algorithm | The algorithm or rules to follow to compute the score. | |
| alignmentType | A category of alignment between the learning resource and the framework node. Recommended values include: 'requires', 'textComplexity', 'readingLevel', and 'educationalSubject'. | |
| alternateName | An alias for the item. | |
| alternativeHeadline | A secondary title of the CreativeWork. | |
| alumni | Alumni of an organization. | |
| alumniOf | An organization that the person is an alumni of. | |
| amenityFeature | An amenity feature (e.g. a characteristic or service) of the Accommodation. This generic property does not make a statement about whether the feature is included in an offer for the main accommodation or available at extra costs. | |
| amount | The amount of money. | |
| amountOfThisGood | The quantity of the goods included in the offer. | |
| announcementLocation | Indicates a specific CivicStructure or LocalBusiness associated with the SpecialAnnouncement. For example, a specific testing facility or business with special opening hours. For a larger geographic region like a quarantine of an entire region, use spatialCoverage. | |
| annualPercentageRate | The annual rate that is charged for borrowing (or made by investing), expressed as a single percentage number that represents the actual yearly cost of funds over the term of a loan. This includes any fees or additional costs associated with the transaction. | |
| answerCount | The number of answers this question has received. | |
| answerExplanation | A step-by-step or full explanation about Answer. Can outline how this Answer was achieved or contain more broad clarification or statement about it. | |
| antagonist | The muscle whose action counteracts the specified muscle. | |
| appearance | Indicates an occurence of a Claim in some CreativeWork. | |
| applicableLocation | The location in which the status applies. | |
| applicantLocationRequirements | The location(s) applicants can apply from. This is usually used for telecommuting jobs where the applicant does not need to be in a physical office. Note: This should not be used for citizenship or work visa requirements. | |
| application | An application that can complete the request. | |
| applicationCategory | Type of software application, e.g. 'Game, Multimedia'. | |
| applicationContact | Contact details for further information relevant to this job posting. | |
| applicationDeadline | The date at which the program stops collecting applications for the next enrollment cycle. | |
| applicationStartDate | The date at which the program begins collecting applications for the next enrollment cycle. | |
| applicationSubCategory | Subcategory of the application, e.g. 'Arcade Game'. | |
| applicationSuite | The name of the application suite to which the application belongs (e.g. Excel belongs to Office). | |
| appliesToDeliveryMethod | The delivery method(s) to which the delivery charge or payment charge specification applies. | |
| appliesToPaymentMethod | The payment method(s) to which the payment charge specification applies. | |
| archiveHeld | Collection, fonds, or item held, kept or maintained by an ArchiveOrganization. | |
| area | The area within which users can expect to reach the broadcast service. | |
| areaServed | The geographic area where a service or offered item is provided. | |
| arrivalAirport | The airport where the flight terminates. | |
| arrivalBoatTerminal | The terminal or port from which the boat arrives. | |
| arrivalBusStop | The stop or station from which the bus arrives. | |
| arrivalGate | Identifier of the flight's arrival gate. | |
| arrivalPlatform | The platform where the train arrives. | |
| arrivalStation | The station where the train trip ends. | |
| arrivalTerminal | Identifier of the flight's arrival terminal. | |
| arrivalTime | The expected arrival time. | |
| artEdition | The number of copies when multiple copies of a piece of artwork are produced - e.g. for a limited edition of 20 prints, 'artEdition' refers to the total number of copies (in this example "20"). | |
| artMedium | The material used. (e.g. Oil, Watercolour, Acrylic, Linoprint, Marble, Cyanotype, Digital, Lithograph, DryPoint, Intaglio, Pastel, Woodcut, Pencil, Mixed Media, etc.) | |
| arterialBranch | The branches that comprise the arterial structure. | |
| artform | e.g. Painting, Drawing, Sculpture, Print, Photograph, Assemblage, Collage, etc. | |
| articleBody | The actual body of the article. | |
| articleSection | Articles may belong to one or more 'sections' in a magazine or newspaper, such as Sports, Lifestyle, etc. | |
| artist | The primary artist for a work in a medium other than pencils or digital line art--for example, if the primary artwork is done in watercolors or digital paints. | |
| artworkSurface | The supporting materials for the artwork, e.g. Canvas, Paper, Wood, Board, etc. | |
| aspect | An aspect of medical practice that is considered on the page, such as 'diagnosis', 'treatment', 'causes', 'prognosis', 'etiology', 'epidemiology', etc. | |
| assembly | Library file name e.g., mscorlib.dll, system.web.dll. | |
| assemblyVersion | Associated product/technology version. e.g., .NET Framework 4.5. | |
| assesses | The item being described is intended to assess the competency or learning outcome defined by the referenced term. | |
| associatedAnatomy | The anatomy of the underlying organ system or structures associated with this entity. | |
| associatedArticle | A NewsArticle associated with the Media Object. | |
| associatedMedia | A media object that encodes this CreativeWork. This property is a synonym for encoding. | |
| associatedPathophysiology | If applicable, a description of the pathophysiology associated with the anatomical system, including potential abnormal changes in the mechanical, physical, and biochemical functions of the system. | |
| athlete | A person that acts as performing member of a sports team; a player as opposed to a coach. | |
| attendee | A person or organization attending the event. | |
| attendees | A person attending the event. | |
| audience | An intended audience, i.e. a group for whom something was created. | |
| audienceType | The target group associated with a given audience (e.g. veterans, car owners, musicians, etc.). | |
| audio | An embedded audio object. | |
| authenticator | The Organization responsible for authenticating the user's subscription. For example, many media apps require a cable/satellite provider to authenticate your subscription before playing media. | |
| author | The author of this content or rating. Please note that author is special in that HTML 5 provides a special mechanism for indicating authorship via the rel tag. That is equivalent to this and may be used interchangeably. | |
| availability | The availability of this item—for example In stock, Out of stock, Pre-order, etc. | |
| availabilityEnds | The end of the availability of the product or service included in the offer. | |
| availabilityStarts | The beginning of the availability of the product or service included in the offer. | |
| availableAtOrFrom | The place(s) from which the offer can be obtained (e.g. store locations). | |
| availableChannel | A means of accessing the service (e.g. a phone bank, a web site, a location, etc.). | |
| availableDeliveryMethod | The delivery method(s) available for this offer. | |
| availableFrom | When the item is available for pickup from the store, locker, etc. | |
| availableIn | The location in which the strength is available. | |
| availableLanguage | A language someone may use with or at the item, service or place. Please use one of the language codes from the IETF BCP 47 standard. See also inLanguage | |
| availableOnDevice | Device required to run the application. Used in cases where a specific make/model is required to run the application. | |
| availableService | A medical service available from this provider. | |
| availableStrength | An available dosage strength for the drug. | |
| availableTest | A diagnostic test or procedure offered by this lab. | |
| availableThrough | After this date, the item will no longer be available for pickup. | |
| award | An award won by or for this item. | |
| awards | Awards won by or for this item. | |
| awayTeam | The away team in a sports event. | |
| backstory | For an Article, typically a NewsArticle, the backstory property provides a textual summary giving a brief explanation of why and how an article was created. In a journalistic setting this could include information about reporting process, methods, interviews, data sources, etc. | |
| bankAccountType | The type of a bank account. | |
| baseSalary | The base salary of the job or of an employee in an EmployeeRole. | |
| bccRecipient | A sub property of recipient. The recipient blind copied on a message. | |
| bed | The type of bed or beds included in the accommodation. For the single case of just one bed of a certain type, you use bed directly with a text. If you want to indicate the quantity of a certain kind of bed, use an instance of BedDetails. For more detailed information, use the amenityFeature property. | |
| beforeMedia | A media object representing the circumstances before performing this direction. | |
| beneficiaryBank | A bank or bank’s branch, financial institution or international financial institution operating the beneficiary’s bank account or releasing funds for the beneficiary. | |
| benefits | Description of benefits associated with the job. | |
| benefitsSummaryUrl | The URL that goes directly to the summary of benefits and coverage for the specific standard plan or plan variation. | |
| bestRating | The highest value allowed in this rating system. If bestRating is omitted, 5 is assumed. | |
| billingAddress | The billing address for the order. | |
| billingDuration | Specifies for how long this price (or price component) will be billed. Can be used, for example, to model the contractual duration of a subscription or payment plan. Type can be either a Duration or a Number (in which case the unit of measurement, for example month, is specified by the unitCode property). | |
| billingIncrement | This property specifies the minimal quantity and rounding increment that will be the basis for the billing. The unit of measurement is specified by the unitCode property. | |
| billingPeriod | The time interval used to compute the invoice. | |
| billingStart | Specifies after how much time this price (or price component) becomes valid and billing starts. Can be used, for example, to model a price increase after the first year of a subscription. The unit of measurement is specified by the unitCode property. | |
| biomechnicalClass | The biomechanical properties of the bone. | |
| birthDate | Date of birth. | |
| birthPlace | The place where the person was born. | |
| bitrate | The bitrate of the media object. | |
| blogPost | A posting that is part of this blog. | |
| blogPosts | The postings that are part of this blog. | |
| bloodSupply | The blood vessel that carries blood from the heart to the muscle. | |
| boardingGroup | The airline-specific indicator of boarding order / preference. | |
| boardingPolicy | The type of boarding policy used by the airline (e.g. zone-based or group-based). | |
| bodyLocation | Location in the body of the anatomical structure. | |
| bodyType | Indicates the design and body style of the vehicle (e.g. station wagon, hatchback, etc.). | |
| bookEdition | The edition of the book. | |
| bookFormat | The format of the book. | |
| bookingAgent | 'bookingAgent' is an out-dated term indicating a 'broker' that serves as a booking agent. | |
| bookingTime | The date and time the reservation was booked. | |
| borrower | A sub property of participant. The person that borrows the object being lent. | |
| box | A box is the area enclosed by the rectangle formed by two points. The first point is the lower corner, the second point is the upper corner. A box is expressed as two points separated by a space character. | |
| branch | The branches that delineate from the nerve bundle. Not to be confused with branchOf. | |
| branchCode | A short textual code (also called "store code") that uniquely identifies a place of business. The code is typically assigned by the parentOrganization and used in structured URLs. For example, in the URL http://www.starbucks.co.uk/store-locator/etc/detail/3047 the code "3047" is a branchCode for a particular branch. |
|
| branchOf | The larger organization that this local business is a branch of, if any. Not to be confused with (anatomical)branch. | |
| brand | The brand(s) associated with a product or service, or the brand(s) maintained by an organization or business person. | |
| breadcrumb | A set of links that can help a user understand and navigate a website hierarchy. | |
| breastfeedingWarning | Any precaution, guidance, contraindication, etc. related to this drug's use by breastfeeding mothers. | |
| broadcastAffiliateOf | The media network(s) whose content is broadcast on this station. | |
| broadcastChannelId | The unique address by which the BroadcastService can be identified in a provider lineup. In US, this is typically a number. | |
| broadcastDisplayName | The name displayed in the channel guide. For many US affiliates, it is the network name. | |
| broadcastFrequency | The frequency used for over-the-air broadcasts. Numeric values or simple ranges e.g. 87-99. In addition a shortcut idiom is supported for frequences of AM and FM radio channels, e.g. "87 FM". | |
| broadcastFrequencyValue | The frequency in MHz for a particular broadcast. | |
| broadcastOfEvent | The event being broadcast such as a sporting event or awards ceremony. | |
| broadcastServiceTier | The type of service required to have access to the channel (e.g. Standard or Premium). | |
| broadcastSignalModulation | The modulation (e.g. FM, AM, etc) used by a particular broadcast service. | |
| broadcastSubChannel | The subchannel used for the broadcast. | |
| broadcastTimezone | The timezone in ISO 8601 format for which the service bases its broadcasts | |
| broadcaster | The organization owning or operating the broadcast service. | |
| broker | An entity that arranges for an exchange between a buyer and a seller. In most cases a broker never acquires or releases ownership of a product or service involved in an exchange. If it is not clear whether an entity is a broker, seller, or buyer, the latter two terms are preferred. | |
| browserRequirements | Specifies browser requirements in human-readable text. For example, 'requires HTML5 support'. | |
| busName | The name of the bus (e.g. Bolt Express). | |
| busNumber | The unique identifier for the bus. | |
| businessDays | Days of the week when the merchant typically operates, indicated via opening hours markup. | |
| businessFunction | The business function (e.g. sell, lease, repair, dispose) of the offer or component of a bundle (TypeAndQuantityNode). The default is http://purl.org/goodrelations/v1#Sell. | |
| buyer | A sub property of participant. The participant/person/organization that bought the object. | |
| byArtist | The artist that performed this album or recording. | |
| byDay | Defines the day(s) of the week on which a recurring Event takes place. May be specified using either DayOfWeek, or alternatively Text conforming to iCal's syntax for byDay recurrence rules. | |
| byMonth | Defines the month(s) of the year on which a recurring Event takes place. Specified as an Integer between 1-12. January is 1. | |
| byMonthDay | Defines the day(s) of the month on which a recurring Event takes place. Specified as an Integer between 1-31. | |
| byMonthWeek | Defines the week(s) of the month on which a recurring Event takes place. Specified as an Integer between 1-5. For clarity, byMonthWeek is best used in conjunction with byDay to indicate concepts like the first and third Mondays of a month. | |
| callSign | A callsign, as used in broadcasting and radio communications to identify people, radio and TV stations, or vehicles. | |
| calories | The number of calories. | |
| candidate | A sub property of object. The candidate subject of this action. | |
| caption | The caption for this object. For downloadable machine formats (closed caption, subtitles etc.) use MediaObject and indicate the encodingFormat. | |
| carbohydrateContent | The number of grams of carbohydrates. | |
| cargoVolume | The available volume for cargo or luggage. For automobiles, this is usually the trunk volume. Typical unit code(s): LTR for liters, FTQ for cubic foot/feet Note: You can use minValue and maxValue to indicate ranges. |
|
| carrier | 'carrier' is an out-dated term indicating the 'provider' for parcel delivery and flights. | |
| carrierRequirements | Specifies specific carrier(s) requirements for the application (e.g. an application may only work on a specific carrier network). | |
| cashBack | A cardholder benefit that pays the cardholder a small percentage of their net expenditures. | |
| catalog | A data catalog which contains this dataset. | |
| catalogNumber | The catalog number for the release. | |
| category | A category for the item. Greater signs or slashes can be used to informally indicate a category hierarchy. | |
| causeOf | The condition, complication, symptom, sign, etc. caused. | |
| ccRecipient | A sub property of recipient. The recipient copied on a message. | |
| character | Fictional person connected with a creative work. | |
| characterAttribute | A piece of data that represents a particular aspect of a fictional character (skill, power, character points, advantage, disadvantage). | |
| characterName | The name of a character played in some acting or performing role, i.e. in a PerformanceRole. | |
| cheatCode | Cheat codes to the game. | |
| checkinTime | The earliest someone may check into a lodging establishment. | |
| checkoutTime | The latest someone may check out of a lodging establishment. | |
| childMaxAge | Maximal age of the child. | |
| childMinAge | Minimal age of the child. | |
| children | A child of the person. | |
| cholesterolContent | The number of milligrams of cholesterol. | |
| circle | A circle is the circular region of a specified radius centered at a specified latitude and longitude. A circle is expressed as a pair followed by a radius in meters. | |
| citation | A citation or reference to another creative work, such as another publication, web page, scholarly article, etc. | |
| claimReviewed | A short summary of the specific claims reviewed in a ClaimReview. | |
| clincalPharmacology | Description of the absorption and elimination of drugs, including their concentration (pharmacokinetics, pK) and biological effects (pharmacodynamics, pD). | |
| clinicalPharmacology | Description of the absorption and elimination of drugs, including their concentration (pharmacokinetics, pK) and biological effects (pharmacodynamics, pD). | |
| clipNumber | Position of the clip within an ordered group of clips. | |
| closes | The closing hour of the place or service on the given day(s) of the week. | |
| coach | A person that acts in a coaching role for a sports team. | |
| code | A medical code for the entity, taken from a controlled vocabulary or ontology such as ICD-9, DiseasesDB, MeSH, SNOMED-CT, RxNorm, etc. | |
| codeRepository | Link to the repository where the un-compiled, human readable code and related code is located (SVN, github, CodePlex). | |
| codeSampleType | What type of code sample: full (compile ready) solution, code snippet, inline code, scripts, template. | |
| codeValue | A short textual code that uniquely identifies the value. | |
| codingSystem | The coding system, e.g. 'ICD-10'. | |
| colleague | A colleague of the person. | |
| colleagues | A colleague of the person. | |
| collection | A sub property of object. The collection target of the action. | |
| collectionSize | The number of items in the Collection. | |
| color | The color of the product. | |
| colorist | The individual who adds color to inked drawings. | |
| comment | Comments, typically from users. | |
| commentCount | The number of comments this CreativeWork (e.g. Article, Question or Answer) has received. This is most applicable to works published in Web sites with commenting system; additional comments may exist elsewhere. | |
| commentText | The text of the UserComment. | |
| commentTime | The time at which the UserComment was made. | |
| competencyRequired | Knowledge, skill, ability or personal attribute that must be demonstrated by a person or other entity in order to do something such as earn an Educational Occupational Credential or understand a LearningResource. | |
| competitor | A competitor in a sports event. | |
| composer | The person or organization who wrote a composition, or who is the composer of a work performed at some event. | |
| comprisedOf | Specifying something physically contained by something else. Typically used here for the underlying anatomical structures, such as organs, that comprise the anatomical system. | |
| conditionsOfAccess | Conditions that affect the availability of, or method(s) of access to, an item. Typically used for real world items such as an ArchiveComponent held by an ArchiveOrganization. This property is not suitable for use as a general Web access control mechanism. It is expressed only in natural language. For example "Available by appointment from the Reading Room" or "Accessible only from logged-in accounts ". |
|
| confirmationNumber | A number that confirms the given order or payment has been received. | |
| connectedTo | Other anatomical structures to which this structure is connected. | |
| constrainingProperty | Indicates a property used as a constraint to define a StatisticalPopulation with respect to the set of entities corresponding to an indicated type (via populationType). | |
| contactOption | An option available on this contact point (e.g. a toll-free number or support for hearing-impaired callers). | |
| contactPoint | A contact point for a person or organization. | |
| contactPoints | A contact point for a person or organization. | |
| contactType | A person or organization can have different contact points, for different purposes. For example, a sales contact point, a PR contact point and so on. This property is used to specify the kind of contact point. | |
| contactlessPayment | A secure method for consumers to purchase products or services via debit, credit or smartcards by using RFID or NFC technology. | |
| containedIn | The basic containment relation between a place and one that contains it. | |
| containedInPlace | The basic containment relation between a place and one that contains it. | |
| containsPlace | The basic containment relation between a place and another that it contains. | |
| containsSeason | A season that is part of the media series. | |
| contentLocation | The location depicted or described in the content. For example, the location in a photograph or painting. | |
| contentRating | Official rating of a piece of content—for example,'MPAA PG-13'. | |
| contentReferenceTime | The specific time described by a creative work, for works (e.g. articles, video objects etc.) that emphasise a particular moment within an Event. | |
| contentSize | File size in (mega/kilo) bytes. | |
| contentType | The supported content type(s) for an EntryPoint response. | |
| contentUrl | Actual bytes of the media object, for example the image file or video file. | |
| contraindication | A contraindication for this therapy. | |
| contributor | A secondary contributor to the CreativeWork or Event. | |
| cookTime | The time it takes to actually cook the dish, in ISO 8601 duration format. | |
| cookingMethod | The method of cooking, such as Frying, Steaming, ... | |
| copyrightHolder | The party holding the legal copyright to the CreativeWork. | |
| copyrightNotice | Text of a notice appropriate for describing the copyright aspects of this Creative Work, ideally indicating the owner of the copyright for the Work. | |
| copyrightYear | The year during which the claimed copyright for the CreativeWork was first asserted. | |
| correction | Indicates a correction to a CreativeWork, either via a CorrectionComment, textually or in another document. | |
| correctionsPolicy | For an Organization (e.g. NewsMediaOrganization), a statement describing (in news media, the newsroom’s) disclosure and correction policy for errors. | |
| costCategory | The category of cost, such as wholesale, retail, reimbursement cap, etc. | |
| costCurrency | The currency (in 3-letter of the drug cost. See: http://en.wikipedia.org/wiki/ISO_4217. | |
| costOrigin | Additional details to capture the origin of the cost data. For example, 'Medicare Part B'. | |
| costPerUnit | The cost per unit of the drug. | |
| countriesNotSupported | Countries for which the application is not supported. You can also provide the two-letter ISO 3166-1 alpha-2 country code. | |
| countriesSupported | Countries for which the application is supported. You can also provide the two-letter ISO 3166-1 alpha-2 country code. | |
| countryOfOrigin | The country of the principal offices of the production company or individual responsible for the movie or program. | |
| course | A sub property of location. The course where this action was taken. | |
| courseCode | The identifier for the Course used by the course provider (e.g. CS101 or 6.001). | |
| courseMode | The medium or means of delivery of the course instance or the mode of study, either as a text label (e.g. "online", "onsite" or "blended"; "synchronous" or "asynchronous"; "full-time" or "part-time") or as a URL reference to a term from a controlled vocabulary (e.g. https://ceds.ed.gov/element/001311#Asynchronous ). | |
| coursePrerequisites | Requirements for taking the Course. May be completion of another Course or a textual description like "permission of instructor". Requirements may be a pre-requisite competency, referenced using AlignmentObject. | |
| courseWorkload | The amount of work expected of students taking the course, often provided as a figure per week or per month, and may be broken down by type. For example, "2 hours of lectures, 1 hour of lab work and 3 hours of independent study per week". | |
| coverageEndTime | The time when the live blog will stop covering the Event. Note that coverage may continue after the Event concludes. | |
| coverageStartTime | The time when the live blog will begin covering the Event. Note that coverage may begin before the Event's start time. The LiveBlogPosting may also be created before coverage begins. | |
| creativeWorkStatus | The status of a creative work in terms of its stage in a lifecycle. Example terms include Incomplete, Draft, Published, Obsolete. Some organizations define a set of terms for the stages of their publication lifecycle. | |
| creator | The creator/author of this CreativeWork. This is the same as the Author property for CreativeWork. | |
| credentialCategory | The category or type of credential being described, for example "degree”, “certificate”, “badge”, or more specific term. | |
| creditText | Text that can be used to credit person(s) and/or organization(s) associated with a published Creative Work. | |
| creditedTo | The group the release is credited to if different than the byArtist. For example, Red and Blue is credited to "Stefani Germanotta Band", but by Lady Gaga. | |
| cssSelector | A CSS selector, e.g. of a SpeakableSpecification or WebPageElement. In the latter case, multiple matches within a page can constitute a single conceptual "Web page element". | |
| currenciesAccepted | The currency accepted. Use standard formats: ISO 4217 currency format e.g. "USD"; Ticker symbol for cryptocurrencies e.g. "BTC"; well known names for Local Exchange Tradings Systems (LETS) and other currency types e.g. "Ithaca HOUR". |
|
| currency | The currency in which the monetary amount is expressed. Use standard formats: ISO 4217 currency format e.g. "USD"; Ticker symbol for cryptocurrencies e.g. "BTC"; well known names for Local Exchange Tradings Systems (LETS) and other currency types e.g. "Ithaca HOUR". |
|
| currentExchangeRate | The current price of a currency. | |
| customer | Party placing the order or paying the invoice. | |
| cutoffTime | Order cutoff time allows merchants to describe the time after which they will no longer process orders received on that day. For orders processed after cutoff time, one day gets added to the delivery time estimate. This property is expected to be most typically used via the ShippingRateSettings publication pattern. The time is indicated using the ISO-8601 Time format, e.g. "23:30:00-05:00" would represent 6:30 pm Eastern Standard Time (EST) which is 5 hours behind Coordinated Universal Time (UTC). | |
| cvdCollectionDate | collectiondate - Date for which patient counts are reported. | |
| cvdFacilityCounty | Name of the County of the NHSN facility that this data record applies to. Use cvdFacilityId to identify the facility. To provide other details, healthcareReportingData can be used on a Hospital entry. | |
| cvdFacilityId | Identifier of the NHSN facility that this data record applies to. Use cvdFacilityCounty to indicate the county. To provide other details, healthcareReportingData can be used on a Hospital entry. | |
| cvdNumBeds | numbeds - HOSPITAL INPATIENT BEDS: Inpatient beds, including all staffed, licensed, and overflow (surge) beds used for inpatients. | |
| cvdNumBedsOcc | numbedsocc - HOSPITAL INPATIENT BED OCCUPANCY: Total number of staffed inpatient beds that are occupied. | |
| cvdNumC19Died | numc19died - DEATHS: Patients with suspected or confirmed COVID-19 who died in the hospital, ED, or any overflow location. | |
| cvdNumC19HOPats | numc19hopats - HOSPITAL ONSET: Patients hospitalized in an NHSN inpatient care location with onset of suspected or confirmed COVID-19 14 or more days after hospitalization. | |
| cvdNumC19HospPats | numc19hosppats - HOSPITALIZED: Patients currently hospitalized in an inpatient care location who have suspected or confirmed COVID-19. | |
| cvdNumC19MechVentPats | numc19mechventpats - HOSPITALIZED and VENTILATED: Patients hospitalized in an NHSN inpatient care location who have suspected or confirmed COVID-19 and are on a mechanical ventilator. | |
| cvdNumC19OFMechVentPats | numc19ofmechventpats - ED/OVERFLOW and VENTILATED: Patients with suspected or confirmed COVID-19 who are in the ED or any overflow location awaiting an inpatient bed and on a mechanical ventilator. | |
| cvdNumC19OverflowPats | numc19overflowpats - ED/OVERFLOW: Patients with suspected or confirmed COVID-19 who are in the ED or any overflow location awaiting an inpatient bed. | |
| cvdNumICUBeds | numicubeds - ICU BEDS: Total number of staffed inpatient intensive care unit (ICU) beds. | |
| cvdNumICUBedsOcc | numicubedsocc - ICU BED OCCUPANCY: Total number of staffed inpatient ICU beds that are occupied. | |
| cvdNumTotBeds | numtotbeds - ALL HOSPITAL BEDS: Total number of all Inpatient and outpatient beds, including all staffed,ICU, licensed, and overflow (surge) beds used for inpatients or outpatients. | |
| cvdNumVent | numvent - MECHANICAL VENTILATORS: Total number of ventilators available. | |
| cvdNumVentUse | numventuse - MECHANICAL VENTILATORS IN USE: Total number of ventilators in use. | |
| dataFeedElement | An item within in a data feed. Data feeds may have many elements. | |
| dataset | A dataset contained in this catalog. | |
| datasetTimeInterval | The range of temporal applicability of a dataset, e.g. for a 2011 census dataset, the year 2011 (in ISO 8601 time interval format). | |
| dateCreated | The date on which the CreativeWork was created or the item was added to a DataFeed. | |
| dateDeleted | The datetime the item was removed from the DataFeed. | |
| dateIssued | The date the ticket was issued. | |
| dateModified | The date on which the CreativeWork was most recently modified or when the item's entry was modified within a DataFeed. | |
| datePosted | Publication date of an online listing. | |
| datePublished | Date of first broadcast/publication. | |
| dateRead | The date/time at which the message has been read by the recipient if a single recipient exists. | |
| dateReceived | The date/time the message was received if a single recipient exists. | |
| dateSent | The date/time at which the message was sent. | |
| dateVehicleFirstRegistered | The date of the first registration of the vehicle with the respective public authorities. | |
| dateline | A dateline is a brief piece of text included in news articles that describes where and when the story was written or filed though the date is often omitted. Sometimes only a placename is provided. Structured representations of dateline-related information can also be expressed more explicitly using locationCreated (which represents where a work was created e.g. where a news report was written). For location depicted or described in the content, use contentLocation. Dateline summaries are oriented more towards human readers than towards automated processing, and can vary substantially. Some examples: "BEIRUT, Lebanon, June 2.", "Paris, France", "December 19, 2017 11:43AM Reporting from Washington", "Beijing/Moscow", "QUEZON CITY, Philippines". |
|
| dayOfWeek | The day of the week for which these opening hours are valid. | |
| deathDate | Date of death. | |
| deathPlace | The place where the person died. | |
| defaultValue | The default value of the input. For properties that expect a literal, the default is a literal value, for properties that expect an object, it's an ID reference to one of the current values. | |
| deliveryAddress | Destination address. | |
| deliveryLeadTime | The typical delay between the receipt of the order and the goods either leaving the warehouse or being prepared for pickup, in case the delivery method is on site pickup. | |
| deliveryMethod | A sub property of instrument. The method of delivery. | |
| deliveryStatus | New entry added as the package passes through each leg of its journey (from shipment to final delivery). | |
| deliveryTime | The total delay between the receipt of the order and the goods reaching the final customer. | |
| department | A relationship between an organization and a department of that organization, also described as an organization (allowing different urls, logos, opening hours). For example: a store with a pharmacy, or a bakery with a cafe. | |
| departureAirport | The airport where the flight originates. | |
| departureBoatTerminal | The terminal or port from which the boat departs. | |
| departureBusStop | The stop or station from which the bus departs. | |
| departureGate | Identifier of the flight's departure gate. | |
| departurePlatform | The platform from which the train departs. | |
| departureStation | The station from which the train departs. | |
| departureTerminal | Identifier of the flight's departure terminal. | |
| departureTime | The expected departure time. | |
| dependencies | Prerequisites needed to fulfill steps in article. | |
| depth | The depth of the item. | |
| description | A description of the item. | |
| device | Device required to run the application. Used in cases where a specific make/model is required to run the application. | |
| diagnosis | One or more alternative conditions considered in the differential diagnosis process as output of a diagnosis process. | |
| diagram | An image containing a diagram that illustrates the structure and/or its component substructures and/or connections with other structures. | |
| diet | A sub property of instrument. The diet used in this action. | |
| dietFeatures | Nutritional information specific to the dietary plan. May include dietary recommendations on what foods to avoid, what foods to consume, and specific alterations/deviations from the USDA or other regulatory body's approved dietary guidelines. | |
| differentialDiagnosis | One of a set of differential diagnoses for the condition. Specifically, a closely-related or competing diagnosis typically considered later in the cognitive process whereby this medical condition is distinguished from others most likely responsible for a similar collection of signs and symptoms to reach the most parsimonious diagnosis or diagnoses in a patient. | |
| director | A director of e.g. tv, radio, movie, video gaming etc. content, or of an event. Directors can be associated with individual items or with a series, episode, clip. | |
| directors | A director of e.g. tv, radio, movie, video games etc. content. Directors can be associated with individual items or with a series, episode, clip. | |
| disambiguatingDescription | A sub property of description. A short description of the item used to disambiguate from other, similar items. Information from other properties (in particular, name) may be necessary for the description to be useful for disambiguation. | |
| discount | Any discount applied (to an Order). | |
| discountCode | Code used to redeem a discount. | |
| discountCurrency | The currency of the discount. Use standard formats: ISO 4217 currency format e.g. "USD"; Ticker symbol for cryptocurrencies e.g. "BTC"; well known names for Local Exchange Tradings Systems (LETS) and other currency types e.g. "Ithaca HOUR". |
|
| discusses | Specifies the CreativeWork associated with the UserComment. | |
| discussionUrl | A link to the page containing the comments of the CreativeWork. | |
| diseasePreventionInfo | Information about disease prevention. | |
| diseaseSpreadStatistics | Statistical information about the spread of a disease, either as WebContent, or described directly as a Dataset, or the specific Observations in the dataset. When a WebContent URL is provided, the page indicated might also contain more such markup. | |
| dissolutionDate | The date that this organization was dissolved. | |
| distance | The distance travelled, e.g. exercising or travelling. | |
| distinguishingSign | One of a set of signs and symptoms that can be used to distinguish this diagnosis from others in the differential diagnosis. | |
| distribution | A downloadable form of this dataset, at a specific location, in a specific format. | |
| diversityPolicy | Statement on diversity policy by an Organization e.g. a NewsMediaOrganization. For a NewsMediaOrganization, a statement describing the newsroom’s diversity policy on both staffing and sources, typically providing staffing data. | |
| diversityStaffingReport | For an Organization (often but not necessarily a NewsMediaOrganization), a report on staffing diversity issues. In a news context this might be for example ASNE or RTDNA (US) reports, or self-reported. | |
| documentation | Further documentation describing the Web API in more detail. | |
| doesNotShip | Indicates when shipping to a particular shippingDestination is not available. | |
| domainIncludes | Relates a property to a class that is (one of) the type(s) the property is expected to be used on. | |
| domiciledMortgage | Whether borrower is a resident of the jurisdiction where the property is located. | |
| doorTime | The time admission will commence. | |
| dosageForm | A dosage form in which this drug/supplement is available, e.g. 'tablet', 'suspension', 'injection'. | |
| doseSchedule | A dosing schedule for the drug for a given population, either observed, recommended, or maximum dose based on the type used. | |
| doseUnit | The unit of the dose, e.g. 'mg'. | |
| doseValue | The value of the dose, e.g. 500. | |
| downPayment | a type of payment made in cash during the onset of the purchase of an expensive good/service. The payment typically represents only a percentage of the full purchase price. | |
| downloadUrl | If the file can be downloaded, URL to download the binary. | |
| downvoteCount | The number of downvotes this question, answer or comment has received from the community. | |
| drainsTo | The vasculature that the vein drains into. | |
| driveWheelConfiguration | The drive wheel configuration, i.e. which roadwheels will receive torque from the vehicle's engine via the drivetrain. | |
| dropoffLocation | Where a rental car can be dropped off. | |
| dropoffTime | When a rental car can be dropped off. | |
| drug | Specifying a drug or medicine used in a medication procedure. | |
| drugClass | The class of drug this belongs to (e.g., statins). | |
| drugUnit | The unit in which the drug is measured, e.g. '5 mg tablet'. | |
| duns | The Dun & Bradstreet DUNS number for identifying an organization or business person. | |
| duplicateTherapy | A therapy that duplicates or overlaps this one. | |
| duration | The duration of the item (movie, audio recording, event, etc.) in ISO 8601 date format. | |
| durationOfWarranty | The duration of the warranty promise. Common unitCode values are ANN for year, MON for months, or DAY for days. | |
| duringMedia | A media object representing the circumstances while performing this direction. | |
| earlyPrepaymentPenalty | The amount to be paid as a penalty in the event of early payment of the loan. | |
| editEIDR | An EIDR (Entertainment Identifier Registry) identifier representing a specific edit / edition for a work of film or television. For example, the motion picture known as "Ghostbusters" whose titleEIDR is "10.5240/7EC7-228A-510A-053E-CBB8-J", has several edits e.g. "10.5240/1F2A-E1C5-680A-14C6-E76B-I" and "10.5240/8A35-3BEE-6497-5D12-9E4F-3". Since schema.org types like Movie and TVEpisode can be used for both works and their multiple expressions, it is possible to use titleEIDR alone (for a general description), or alongside editEIDR for a more edit-specific description. |
|
| editor | Specifies the Person who edited the CreativeWork. | |
| eduQuestionType | For questions that are part of learning resources (e.g. Quiz), eduQuestionType indicates the format of question being given. Example: "Multiple choice", "Open ended", "Flashcard". | |
| educationRequirements | Educational background needed for the position or Occupation. | |
| educationalAlignment | An alignment to an established educational framework. This property should not be used where the nature of the alignment can be described using a simple property, for example to express that a resource teaches or assesses a competency. |
|
| educationalCredentialAwarded | A description of the qualification, award, certificate, diploma or other educational credential awarded as a consequence of successful completion of this course or program. | |
| educationalFramework | The framework to which the resource being described is aligned. | |
| educationalLevel | The level in terms of progression through an educational or training context. Examples of educational levels include 'beginner', 'intermediate' or 'advanced', and formal sets of level indicators. | |
| educationalProgramMode | Similar to courseMode, The medium or means of delivery of the program as a whole. The value may either be a text label (e.g. "online", "onsite" or "blended"; "synchronous" or "asynchronous"; "full-time" or "part-time") or a URL reference to a term from a controlled vocabulary (e.g. https://ceds.ed.gov/element/001311#Asynchronous ). | |
| educationalRole | An educationalRole of an EducationalAudience. | |
| educationalUse | The purpose of a work in the context of education; for example, 'assignment', 'group work'. | |
| elevation | The elevation of a location (WGS 84). Values may be of the form 'NUMBER UNITOFMEASUREMENT' (e.g., '1,000 m', '3,200 ft') while numbers alone should be assumed to be a value in meters. | |
| eligibilityToWorkRequirement | The legal requirements such as citizenship, visa and other documentation required for an applicant to this job. | |
| eligibleCustomerType | The type(s) of customers for which the given offer is valid. | |
| eligibleDuration | The duration for which the given offer is valid. | |
| eligibleQuantity | The interval and unit of measurement of ordering quantities for which the offer or price specification is valid. This allows e.g. specifying that a certain freight charge is valid only for a certain quantity. | |
| eligibleRegion | The ISO 3166-1 (ISO 3166-1 alpha-2) or ISO 3166-2 code, the place, or the GeoShape for the geo-political region(s) for which the offer or delivery charge specification is valid. See also ineligibleRegion. |
|
| eligibleTransactionVolume | The transaction volume, in a monetary unit, for which the offer or price specification is valid, e.g. for indicating a minimal purchasing volume, to express free shipping above a certain order volume, or to limit the acceptance of credit cards to purchases to a certain minimal amount. | |
| Email address. | ||
| embedUrl | A URL pointing to a player for a specific video. In general, this is the information in the src element of an embed tag and should not be the same as the content of the loc tag. |
|
| emissionsCO2 | The CO2 emissions in g/km. When used in combination with a QuantitativeValue, put "g/km" into the unitText property of that value, since there is no UN/CEFACT Common Code for "g/km". | |
| employee | Someone working for this organization. | |
| employees | People working for this organization. | |
| employerOverview | A description of the employer, career opportunities and work environment for this position. | |
| employmentType | Type of employment (e.g. full-time, part-time, contract, temporary, seasonal, internship). | |
| employmentUnit | Indicates the department, unit and/or facility where the employee reports and/or in which the job is to be performed. | |
| encodesCreativeWork | The CreativeWork encoded by this media object. | |
| encoding | A media object that encodes this CreativeWork. This property is a synonym for associatedMedia. | |
| encodingFormat | Media type typically expressed using a MIME format (see IANA site and MDN reference) e.g. application/zip for a SoftwareApplication binary, audio/mpeg for .mp3 etc.). In cases where a CreativeWork has several media type representations, encoding can be used to indicate each MediaObject alongside particular encodingFormat information. Unregistered or niche encoding and file formats can be indicated instead via the most appropriate URL, e.g. defining Web page or a Wikipedia/Wikidata entry. |
|
| encodingType | The supported encoding type(s) for an EntryPoint request. | |
| encodings | A media object that encodes this CreativeWork. | |
| endDate | The end date and time of the item (in ISO 8601 date format). | |
| endOffset | The end time of the clip expressed as the number of seconds from the beginning of the work. | |
| endTime | The endTime of something. For a reserved event or service (e.g. FoodEstablishmentReservation), the time that it is expected to end. For actions that span a period of time, when the action was performed. e.g. John wrote a book from January to December. For media, including audio and video, it's the time offset of the end of a clip within a larger file. Note that Event uses startDate/endDate instead of startTime/endTime, even when describing dates with times. This situation may be clarified in future revisions. |
|
| endorsee | A sub property of participant. The person/organization being supported. | |
| endorsers | People or organizations that endorse the plan. | |
| energyEfficiencyScaleMax | Specifies the most energy efficient class on the regulated EU energy consumption scale for the product category a product belongs to. For example, energy consumption for televisions placed on the market after January 1, 2020 is scaled from D to A+++. | |
| energyEfficiencyScaleMin | Specifies the least energy efficient class on the regulated EU energy consumption scale for the product category a product belongs to. For example, energy consumption for televisions placed on the market after January 1, 2020 is scaled from D to A+++. | |
| engineDisplacement | The volume swept by all of the pistons inside the cylinders of an internal combustion engine in a single movement. Typical unit code(s): CMQ for cubic centimeter, LTR for liters, INQ for cubic inches * Note 1: You can link to information about how the given value has been determined using the valueReference property. * Note 2: You can use minValue and maxValue to indicate ranges. |
|
| enginePower | The power of the vehicle's engine.
Typical unit code(s): KWT for kilowatt, BHP for brake horsepower, N12 for metric horsepower (PS, with 1 PS = 735,49875 W)
|
|
| engineType | The type of engine or engines powering the vehicle. | |
| entertainmentBusiness | A sub property of location. The entertainment business where the action occurred. | |
| epidemiology | The characteristics of associated patients, such as age, gender, race etc. | |
| episode | An episode of a tv, radio or game media within a series or season. | |
| episodeNumber | Position of the episode within an ordered group of episodes. | |
| episodes | An episode of a TV/radio series or season. | |
| equal | This ordering relation for qualitative values indicates that the subject is equal to the object. | |
| error | For failed actions, more information on the cause of the failure. | |
| estimatedCost | The estimated cost of the supply or supplies consumed when performing instructions. | |
| estimatedFlightDuration | The estimated time the flight will take. | |
| estimatedSalary | An estimated salary for a job posting or occupation, based on a variety of variables including, but not limited to industry, job title, and location. Estimated salaries are often computed by outside organizations rather than the hiring organization, who may not have committed to the estimated value. | |
| estimatesRiskOf | The condition, complication, or symptom whose risk is being estimated. | |
| ethicsPolicy | Statement about ethics policy, e.g. of a NewsMediaOrganization regarding journalistic and publishing practices, or of a Restaurant, a page describing food source policies. In the case of a NewsMediaOrganization, an ethicsPolicy is typically a statement describing the personal, organizational, and corporate standards of behavior expected by the organization. | |
| event | Upcoming or past event associated with this place, organization, or action. | |
| eventAttendanceMode | The eventAttendanceMode of an event indicates whether it occurs online, offline, or a mix. | |
| eventSchedule | Associates an Event with a Schedule. There are circumstances where it is preferable to share a schedule for a series of repeating events rather than data on the individual events themselves. For example, a website or application might prefer to publish a schedule for a weekly gym class rather than provide data on every event. A schedule could be processed by applications to add forthcoming events to a calendar. An Event that is associated with a Schedule using this property should not have startDate or endDate properties. These are instead defined within the associated Schedule, this avoids any ambiguity for clients using the data. The property might have repeated values to specify different schedules, e.g. for different months or seasons. | |
| eventStatus | An eventStatus of an event represents its status; particularly useful when an event is cancelled or rescheduled. | |
| events | Upcoming or past events associated with this place or organization. | |
| evidenceLevel | Strength of evidence of the data used to formulate the guideline (enumerated). | |
| evidenceOrigin | Source of the data used to formulate the guidance, e.g. RCT, consensus opinion, etc. | |
| exampleOfWork | A creative work that this work is an example/instance/realization/derivation of. | |
| exceptDate | Defines a Date or DateTime during which a scheduled Event will not take place. The property allows exceptions to a Schedule to be specified. If an exception is specified as a DateTime then only the event that would have started at that specific date and time should be excluded from the schedule. If an exception is specified as a Date then any event that is scheduled for that 24 hour period should be excluded from the schedule. This allows a whole day to be excluded from the schedule without having to itemise every scheduled event. | |
| exchangeRateSpread | The difference between the price at which a broker or other intermediary buys and sells foreign currency. | |
| executableLibraryName | Library file name e.g., mscorlib.dll, system.web.dll. | |
| exerciseCourse | A sub property of location. The course where this action was taken. | |
| exercisePlan | A sub property of instrument. The exercise plan used on this action. | |
| exerciseRelatedDiet | A sub property of instrument. The diet used in this action. | |
| exerciseType | Type(s) of exercise or activity, such as strength training, flexibility training, aerobics, cardiac rehabilitation, etc. | |
| exifData | exif data for this object. | |
| expectedArrivalFrom | The earliest date the package may arrive. | |
| expectedArrivalUntil | The latest date the package may arrive. | |
| expectedPrognosis | The likely outcome in either the short term or long term of the medical condition. | |
| expectsAcceptanceOf | An Offer which must be accepted before the user can perform the Action. For example, the user may need to buy a movie before being able to watch it. | |
| experienceInPlaceOfEducation | Indicates whether a JobPosting will accept experience (as indicated by OccupationalExperienceRequirements) in place of its formal educational qualifications (as indicated by educationRequirements). If true, indicates that satisfying one of these requirements is sufficient. | |
| experienceRequirements | Description of skills and experience needed for the position or Occupation. | |
| expertConsiderations | Medical expert advice related to the plan. | |
| expires | Date the content expires and is no longer useful or available. For example a VideoObject or NewsArticle whose availability or relevance is time-limited, or a ClaimReview fact check whose publisher wants to indicate that it may no longer be relevant (or helpful to highlight) after some date. | |
| familyName | Family name. In the U.S., the last name of a Person. | |
| fatContent | The number of grams of fat. | |
| faxNumber | The fax number. | |
| featureList | Features or modules provided by this application (and possibly required by other applications). | |
| feesAndCommissionsSpecification | Description of fees, commissions, and other terms applied either to a class of financial product, or by a financial service organization. | |
| fiberContent | The number of grams of fiber. | |
| fileFormat | Media type, typically MIME format (see IANA site) of the content e.g. application/zip of a SoftwareApplication binary. In cases where a CreativeWork has several media type representations, 'encoding' can be used to indicate each MediaObject alongside particular fileFormat information. Unregistered or niche file formats can be indicated instead via the most appropriate URL, e.g. defining Web page or a Wikipedia entry. | |
| fileSize | Size of the application / package (e.g. 18MB). In the absence of a unit (MB, KB etc.), KB will be assumed. | |
| financialAidEligible | A financial aid type or program which students may use to pay for tuition or fees associated with the program. | |
| firstAppearance | Indicates the first known occurence of a Claim in some CreativeWork. | |
| firstPerformance | The date and place the work was first performed. | |
| flightDistance | The distance of the flight. | |
| flightNumber | The unique identifier for a flight including the airline IATA code. For example, if describing United flight 110, where the IATA code for United is 'UA', the flightNumber is 'UA110'. | |
| floorLevel | The floor level for an Accommodation in a multi-storey building. Since counting systems vary internationally, the local system should be used where possible. | |
| floorLimit | A floor limit is the amount of money above which credit card transactions must be authorized. | |
| floorSize | The size of the accommodation, e.g. in square meter or squarefoot. Typical unit code(s): MTK for square meter, FTK for square foot, or YDK for square yard | |
| followee | A sub property of object. The person or organization being followed. | |
| follows | The most generic uni-directional social relation. | |
| followup | Typical or recommended followup care after the procedure is performed. | |
| foodEstablishment | A sub property of location. The specific food establishment where the action occurred. | |
| foodEvent | A sub property of location. The specific food event where the action occurred. | |
| foodWarning | Any precaution, guidance, contraindication, etc. related to consumption of specific foods while taking this drug. | |
| founder | A person who founded this organization. | |
| founders | A person who founded this organization. | |
| foundingDate | The date that this organization was founded. | |
| foundingLocation | The place where the Organization was founded. | |
| free | A flag to signal that the item, event, or place is accessible for free. | |
| freeShippingThreshold | A monetary value above which (or equal to) the shipping rate becomes free. Intended to be used via an OfferShippingDetails with shippingSettingsLink matching this ShippingRateSettings. | |
| frequency | How often the dose is taken, e.g. 'daily'. | |
| fromLocation | A sub property of location. The original location of the object or the agent before the action. | |
| fuelCapacity | The capacity of the fuel tank or in the case of electric cars, the battery. If there are multiple components for storage, this should indicate the total of all storage of the same type. Typical unit code(s): LTR for liters, GLL of US gallons, GLI for UK / imperial gallons, AMH for ampere-hours (for electrical vehicles). |
|
| fuelConsumption | The amount of fuel consumed for traveling a particular distance or temporal duration with the given vehicle (e.g. liters per 100 km).
|
|
| fuelEfficiency | The distance traveled per unit of fuel used; most commonly miles per gallon (mpg) or kilometers per liter (km/L).
|
|
| fuelType | The type of fuel suitable for the engine or engines of the vehicle. If the vehicle has only one engine, this property can be attached directly to the vehicle. | |
| functionalClass | The degree of mobility the joint allows. | |
| fundedItem | Indicates an item funded or sponsored through a Grant. | |
| funder | A person or organization that supports (sponsors) something through some kind of financial contribution. | |
| game | Video game which is played on this server. | |
| gameItem | An item is an object within the game world that can be collected by a player or, occasionally, a non-player character. | |
| gameLocation | Real or fictional location of the game (or part of game). | |
| gamePlatform | The electronic systems used to play video games. | |
| gameServer | The server on which it is possible to play the game. | |
| gameTip | Links to tips, tactics, etc. | |
| gender | Gender of something, typically a Person, but possibly also fictional characters, animals, etc. While https://schema.org/Male and https://schema.org/Female may be used, text strings are also acceptable for people who do not identify as a binary gender. The gender property can also be used in an extended sense to cover e.g. the gender of sports teams. As with the gender of individuals, we do not try to enumerate all possibilities. A mixed-gender SportsTeam can be indicated with a text value of "Mixed". | |
| genre | Genre of the creative work, broadcast channel or group. | |
| geo | The geo coordinates of the place. | |
| geoContains | Represents a relationship between two geometries (or the places they represent), relating a containing geometry to a contained geometry. "a contains b iff no points of b lie in the exterior of a, and at least one point of the interior of b lies in the interior of a". As defined in DE-9IM. | |
| geoCoveredBy | Represents a relationship between two geometries (or the places they represent), relating a geometry to another that covers it. As defined in DE-9IM. | |
| geoCovers | Represents a relationship between two geometries (or the places they represent), relating a covering geometry to a covered geometry. "Every point of b is a point of (the interior or boundary of) a". As defined in DE-9IM. | |
| geoCrosses | Represents a relationship between two geometries (or the places they represent), relating a geometry to another that crosses it: "a crosses b: they have some but not all interior points in common, and the dimension of the intersection is less than that of at least one of them". As defined in DE-9IM. | |
| geoDisjoint | Represents spatial relations in which two geometries (or the places they represent) are topologically disjoint: they have no point in common. They form a set of disconnected geometries." (a symmetric relationship, as defined in DE-9IM) | |
| geoEquals | Represents spatial relations in which two geometries (or the places they represent) are topologically equal, as defined in DE-9IM. "Two geometries are topologically equal if their interiors intersect and no part of the interior or boundary of one geometry intersects the exterior of the other" (a symmetric relationship) | |
| geoIntersects | Represents spatial relations in which two geometries (or the places they represent) have at least one point in common. As defined in DE-9IM. | |
| geoMidpoint | Indicates the GeoCoordinates at the centre of a GeoShape e.g. GeoCircle. | |
| geoOverlaps | Represents a relationship between two geometries (or the places they represent), relating a geometry to another that geospatially overlaps it, i.e. they have some but not all points in common. As defined in DE-9IM. | |
| geoRadius | Indicates the approximate radius of a GeoCircle (metres unless indicated otherwise via Distance notation). | |
| geoTouches | Represents spatial relations in which two geometries (or the places they represent) touch: they have at least one boundary point in common, but no interior points." (a symmetric relationship, as defined in DE-9IM ) | |
| geoWithin | Represents a relationship between two geometries (or the places they represent), relating a geometry to one that contains it, i.e. it is inside (i.e. within) its interior. As defined in DE-9IM. | |
| geographicArea | The geographic area associated with the audience. | |
| gettingTestedInfo | Information about getting tested (for a MedicalCondition), e.g. in the context of a pandemic. | |
| givenName | Given name. In the U.S., the first name of a Person. | |
| globalLocationNumber | The Global Location Number (GLN, sometimes also referred to as International Location Number or ILN) of the respective organization, person, or place. The GLN is a 13-digit number used to identify parties and physical locations. | |
| governmentBenefitsInfo | governmentBenefitsInfo provides information about government benefits associated with a SpecialAnnouncement. | |
| gracePeriod | The period of time after any due date that the borrower has to fulfil its obligations before a default (failure to pay) is deemed to have occurred. | |
| grantee | The person, organization, contact point, or audience that has been granted this permission. | |
| greater | This ordering relation for qualitative values indicates that the subject is greater than the object. | |
| greaterOrEqual | This ordering relation for qualitative values indicates that the subject is greater than or equal to the object. | |
| gtin | A Global Trade Item Number (GTIN). GTINs identify trade items, including products and services, using numeric identification codes. The gtin property generalizes the earlier gtin8, gtin12, gtin13, and gtin14 properties. The GS1 digital link specifications express GTINs as URLs. A correct gtin value should be a valid GTIN, which means that it should be an all-numeric string of either 8, 12, 13 or 14 digits, or a "GS1 Digital Link" URL based on such a string. The numeric component should also have a valid GS1 check digit and meet the other rules for valid GTINs. See also GS1's GTIN Summary and Wikipedia for more details. Left-padding of the gtin values is not required or encouraged. | |
| gtin12 | The GTIN-12 code of the product, or the product to which the offer refers. The GTIN-12 is the 12-digit GS1 Identification Key composed of a U.P.C. Company Prefix, Item Reference, and Check Digit used to identify trade items. See GS1 GTIN Summary for more details. | |
| gtin13 | The GTIN-13 code of the product, or the product to which the offer refers. This is equivalent to 13-digit ISBN codes and EAN UCC-13. Former 12-digit UPC codes can be converted into a GTIN-13 code by simply adding a preceding zero. See GS1 GTIN Summary for more details. | |
| gtin14 | The GTIN-14 code of the product, or the product to which the offer refers. See GS1 GTIN Summary for more details. | |
| gtin8 | The GTIN-8 code of the product, or the product to which the offer refers. This code is also known as EAN/UCC-8 or 8-digit EAN. See GS1 GTIN Summary for more details. | |
| guideline | A medical guideline related to this entity. | |
| guidelineDate | Date on which this guideline's recommendation was made. | |
| guidelineSubject | The medical conditions, treatments, etc. that are the subject of the guideline. | |
| handlingTime | The typical delay between the receipt of the order and the goods either leaving the warehouse or being prepared for pickup, in case the delivery method is on site pickup. Typical properties: minValue, maxValue, unitCode (d for DAY). This is by common convention assumed to mean business days (if a unitCode is used, coded as "d"), i.e. only counting days when the business normally operates. | |
| hasBroadcastChannel | A broadcast channel of a broadcast service. | |
| hasCategoryCode | A Category code contained in this code set. | |
| hasCourse | A course or class that is one of the learning opportunities that constitute an educational / occupational program. No information is implied about whether the course is mandatory or optional; no guarantee is implied about whether the course will be available to everyone on the program. | |
| hasCourseInstance | An offering of the course at a specific time and place or through specific media or mode of study or to a specific section of students. | |
| hasCredential | A credential awarded to the Person or Organization. | |
| hasDefinedTerm | A Defined Term contained in this term set. | |
| hasDeliveryMethod | Method used for delivery or shipping. | |
| hasDigitalDocumentPermission | A permission related to the access to this document (e.g. permission to read or write an electronic document). For a public document, specify a grantee with an Audience with audienceType equal to "public". | |
| hasDriveThroughService | Indicates whether some facility (e.g. FoodEstablishment, CovidTestingFacility) offers a service that can be used by driving through in a car. In the case of CovidTestingFacility such facilities could potentially help with social distancing from other potentially-infected users. | |
| hasEnergyConsumptionDetails | Defines the energy efficiency Category (also known as "class" or "rating") for a product according to an international energy efficiency standard. | |
| hasEnergyEfficiencyCategory | Defines the energy efficiency Category (which could be either a rating out of range of values or a yes/no certification) for a product according to an international energy efficiency standard. | |
| hasHealthAspect | Indicates the aspect or aspects specifically addressed in some HealthTopicContent. For example, that the content is an overview, or that it talks about treatment, self-care, treatments or their side-effects. | |
| hasMap | A URL to a map of the place. | |
| hasMeasurement | A product measurement, for example the inseam of pants, the wheel size of a bicycle, or the gauge of a screw. Usually an exact measurement, but can also be a range of measurements for adjustable products, for example belts and ski bindings. | |
| hasMenu | Either the actual menu as a structured representation, as text, or a URL of the menu. | |
| hasMenuItem | A food or drink item contained in a menu or menu section. | |
| hasMenuSection | A subgrouping of the menu (by dishes, course, serving time period, etc.). | |
| hasMerchantReturnPolicy | Indicates a MerchantReturnPolicy that may be applicable. | |
| hasOccupation | The Person's occupation. For past professions, use Role for expressing dates. | |
| hasOfferCatalog | Indicates an OfferCatalog listing for this Organization, Person, or Service. | |
| hasPOS | Points-of-Sales operated by the organization or person. | |
| hasPart | Indicates an item or CreativeWork that is part of this item, or CreativeWork (in some sense). | |
| hasVariant | Indicates a Product that is a member of this ProductGroup (or ProductModel). | |
| headline | Headline of the article. | |
| healthCondition | Specifying the health condition(s) of a patient, medical study, or other target audience. | |
| healthPlanCoinsuranceOption | Whether the coinsurance applies before or after deductible, etc. TODO: Is this a closed set? | |
| healthPlanCoinsuranceRate | Whether The rate of coinsurance expressed as a number between 0.0 and 1.0. | |
| healthPlanCopay | Whether The copay amount. | |
| healthPlanCopayOption | Whether the copay is before or after deductible, etc. TODO: Is this a closed set? | |
| healthPlanCostSharing | Whether The costs to the patient for services under this network or formulary. | |
| healthPlanDrugOption | TODO. | |
| healthPlanDrugTier | The tier(s) of drugs offered by this formulary or insurance plan. | |
| healthPlanId | The 14-character, HIOS-generated Plan ID number. (Plan IDs must be unique, even across different markets.) | |
| healthPlanMarketingUrl | The URL that goes directly to the plan brochure for the specific standard plan or plan variation. | |
| healthPlanNetworkId | Name or unique ID of network. (Networks are often reused across different insurance plans). | |
| healthPlanNetworkTier | The tier(s) for this network. | |
| healthPlanPharmacyCategory | The category or type of pharmacy associated with this cost sharing. | |
| healthcareReportingData | Indicates data describing a hospital, e.g. a CDC CDCPMDRecord or as some kind of Dataset. | |
| height | The height of the item. | |
| highPrice | The highest price of all offers available. Usage guidelines:
|
|
| hiringOrganization | Organization offering the job position. | |
| holdingArchive | ArchiveOrganization that holds, keeps or maintains the ArchiveComponent. | |
| homeLocation | A contact location for a person's residence. | |
| homeTeam | The home team in a sports event. | |
| honorificPrefix | An honorific prefix preceding a Person's name such as Dr/Mrs/Mr. | |
| honorificSuffix | An honorific suffix following a Person's name such as M.D. /PhD/MSCSW. | |
| hospitalAffiliation | A hospital with which the physician or office is affiliated. | |
| hostingOrganization | The organization (airline, travelers' club, etc.) the membership is made with. | |
| hoursAvailable | The hours during which this service or contact is available. | |
| howPerformed | How the procedure is performed. | |
| httpMethod | An HTTP method that specifies the appropriate HTTP method for a request to an HTTP EntryPoint. Values are capitalized strings as used in HTTP. | |
| iataCode | IATA identifier for an airline or airport. | |
| icaoCode | ICAO identifier for an airport. | |
| identifier | The identifier property represents any kind of identifier for any kind of Thing, such as ISBNs, GTIN codes, UUIDs etc. Schema.org provides dedicated properties for representing many of these, either as textual strings or as URL (URI) links. See background notes for more details. | |
| identifyingExam | A physical examination that can identify this sign. | |
| identifyingTest | A diagnostic test that can identify this sign. | |
| illustrator | The illustrator of the book. | |
| image | An image of the item. This can be a URL or a fully described ImageObject. | |
| imagingTechnique | Imaging technique used. | |
| inAlbum | The album to which this recording belongs. | |
| inBroadcastLineup | The CableOrSatelliteService offering the channel. | |
| inCodeSet | A CategoryCodeSet that contains this category code. | |
| inDefinedTermSet | A DefinedTermSet that contains this term. | |
| inLanguage | The language of the content or performance or used in an action. Please use one of the language codes from the IETF BCP 47 standard. See also availableLanguage. | |
| inPlaylist | The playlist to which this recording belongs. | |
| inProductGroupWithID | Indicates the productGroupID for a ProductGroup that this product isVariantOf. | |
| inStoreReturnsOffered | Are in-store returns offered? | |
| inSupportOf | Qualification, candidature, degree, application that Thesis supports. | |
| incentiveCompensation | Description of bonus and commission compensation aspects of the job. | |
| incentives | Description of bonus and commission compensation aspects of the job. | |
| includedComposition | Smaller compositions included in this work (e.g. a movement in a symphony). | |
| includedDataCatalog | A data catalog which contains this dataset (this property was previously 'catalog', preferred name is now 'includedInDataCatalog'). | |
| includedInDataCatalog | A data catalog which contains this dataset. | |
| includedInHealthInsurancePlan | The insurance plans that cover this drug. | |
| includedRiskFactor | A modifiable or non-modifiable risk factor included in the calculation, e.g. age, coexisting condition. | |
| includesAttraction | Attraction located at destination. | |
| includesHealthPlanFormulary | Formularies covered by this plan. | |
| includesHealthPlanNetwork | Networks covered by this plan. | |
| includesObject | This links to a node or nodes indicating the exact quantity of the products included in an Offer or ProductCollection. | |
| increasesRiskOf | The condition, complication, etc. influenced by this factor. | |
| industry | The industry associated with the job position. | |
| ineligibleRegion | The ISO 3166-1 (ISO 3166-1 alpha-2) or ISO 3166-2 code, the place, or the GeoShape for the geo-political region(s) for which the offer or delivery charge specification is not valid, e.g. a region where the transaction is not allowed. See also eligibleRegion. |
|
| infectiousAgent | The actual infectious agent, such as a specific bacterium. | |
| infectiousAgentClass | The class of infectious agent (bacteria, prion, etc.) that causes the disease. | |
| ingredients | A single ingredient used in the recipe, e.g. sugar, flour or garlic. | |
| inker | The individual who traces over the pencil drawings in ink after pencils are complete. | |
| insertion | The place of attachment of a muscle, or what the muscle moves. | |
| installUrl | URL at which the app may be installed, if different from the URL of the item. | |
| instructor | A person assigned to instruct or provide instructional assistance for the CourseInstance. | |
| instrument | The object that helped the agent perform the action. e.g. John wrote a book with a pen. | |
| intensity | Quantitative measure gauging the degree of force involved in the exercise, for example, heartbeats per minute. May include the velocity of the movement. | |
| interactingDrug | Another drug that is known to interact with this drug in a way that impacts the effect of this drug or causes a risk to the patient. Note: disease interactions are typically captured as contraindications. | |
| interactionCount | This property is deprecated, alongside the UserInteraction types on which it depended. | |
| interactionService | The WebSite or SoftwareApplication where the interactions took place. | |
| interactionStatistic | The number of interactions for the CreativeWork using the WebSite or SoftwareApplication. The most specific child type of InteractionCounter should be used. | |
| interactionType | The Action representing the type of interaction. For up votes, +1s, etc. use LikeAction. For down votes use DislikeAction. Otherwise, use the most specific Action. | |
| interactivityType | The predominant mode of learning supported by the learning resource. Acceptable values are 'active', 'expositive', or 'mixed'. | |
| interestRate | The interest rate, charged or paid, applicable to the financial product. Note: This is different from the calculated annualPercentageRate. | |
| inventoryLevel | The current approximate inventory level for the item or items. | |
| inverseOf | Relates a property to a property that is its inverse. Inverse properties relate the same pairs of items to each other, but in reversed direction. For example, the 'alumni' and 'alumniOf' properties are inverseOf each other. Some properties don't have explicit inverses; in these situations RDFa and JSON-LD syntax for reverse properties can be used. | |
| isAcceptingNewPatients | Whether the provider is accepting new patients. | |
| isAccessibleForFree | A flag to signal that the item, event, or place is accessible for free. | |
| isAccessoryOrSparePartFor | A pointer to another product (or multiple products) for which this product is an accessory or spare part. | |
| isAvailableGenerically | True if the drug is available in a generic form (regardless of name). | |
| isBasedOn | A resource from which this work is derived or from which it is a modification or adaption. | |
| isBasedOnUrl | A resource that was used in the creation of this resource. This term can be repeated for multiple sources. For example, http://example.com/great-multiplication-intro.html. | |
| isConsumableFor | A pointer to another product (or multiple products) for which this product is a consumable. | |
| isFamilyFriendly | Indicates whether this content is family friendly. | |
| isGift | Was the offer accepted as a gift for someone other than the buyer. | |
| isLiveBroadcast | True if the broadcast is of a live event. | |
| isPartOf | Indicates an item or CreativeWork that this item, or CreativeWork (in some sense), is part of. | |
| isPlanForApartment | Indicates some accommodation that this floor plan describes. | |
| isProprietary | True if this item's name is a proprietary/brand name (vs. generic name). | |
| isRelatedTo | A pointer to another, somehow related product (or multiple products). | |
| isResizable | Whether the 3DModel allows resizing. For example, room layout applications often do not allow 3DModel elements to be resized to reflect reality. | |
| isSimilarTo | A pointer to another, functionally similar product (or multiple products). | |
| isUnlabelledFallback | This can be marked 'true' to indicate that some published DeliveryTimeSettings or ShippingRateSettings are intended to apply to all OfferShippingDetails published by the same merchant, when referenced by a shippingSettingsLink in those settings. It is not meaningful to use a 'true' value for this property alongside a transitTimeLabel (for DeliveryTimeSettings) or shippingLabel (for ShippingRateSettings), since this property is for use with unlabelled settings. | |
| isVariantOf | Indicates the kind of product that this is a variant of. In the case of ProductModel, this is a pointer (from a ProductModel) to a base product from which this product is a variant. It is safe to infer that the variant inherits all product features from the base model, unless defined locally. This is not transitive. In the case of a ProductGroup, the group description also serves as a template, representing a set of Products that vary on explicitly defined, specific dimensions only (so it defines both a set of variants, as well as which values distinguish amongst those variants). When used with ProductGroup, this property can apply to any Product included in the group. | |
| isbn | The ISBN of the book. | |
| isicV4 | The International Standard of Industrial Classification of All Economic Activities (ISIC), Revision 4 code for a particular organization, business person, or place. | |
| isrcCode | The International Standard Recording Code for the recording. | |
| issn | The International Standard Serial Number (ISSN) that identifies this serial publication. You can repeat this property to identify different formats of, or the linking ISSN (ISSN-L) for, this serial publication. | |
| issueNumber | Identifies the issue of publication; for example, "iii" or "2". | |
| issuedBy | The organization issuing the ticket or permit. | |
| issuedThrough | The service through with the permit was granted. | |
| iswcCode | The International Standard Musical Work Code for the composition. | |
| item | An entity represented by an entry in a list or data feed (e.g. an 'artist' in a list of 'artists')’. | |
| itemCondition | A predefined value from OfferItemCondition or a textual description of the condition of the product or service, or the products or services included in the offer. | |
| itemListElement | For itemListElement values, you can use simple strings (e.g. "Peter", "Paul", "Mary"), existing entities, or use ListItem. Text values are best if the elements in the list are plain strings. Existing entities are best for a simple, unordered list of existing things in your data. ListItem is used with ordered lists when you want to provide additional context about the element in that list or when the same item might be in different places in different lists. Note: The order of elements in your mark-up is not sufficient for indicating the order or elements. Use ListItem with a 'position' property in such cases. |
|
| itemListOrder | Type of ordering (e.g. Ascending, Descending, Unordered). | |
| itemLocation | Current location of the item. | |
| itemOffered | An item being offered (or demanded). The transactional nature of the offer or demand is documented using businessFunction, e.g. sell, lease etc. While several common expected types are listed explicitly in this definition, others can be used. Using a second type, such as Product or a subtype of Product, can clarify the nature of the offer. | |
| itemReviewed | The item that is being reviewed/rated. | |
| itemShipped | Item(s) being shipped. | |
| itinerary | Destination(s) ( Place ) that make up a trip. For a trip where destination order is important use ItemList to specify that order (see examples). | |
| jobBenefits | Description of benefits associated with the job. | |
| jobImmediateStart | An indicator as to whether a position is available for an immediate start. | |
| jobLocation | A (typically single) geographic location associated with the job position. | |
| jobLocationType | A description of the job location (e.g TELECOMMUTE for telecommute jobs). | |
| jobStartDate | The date on which a successful applicant for this job would be expected to start work. Choose a specific date in the future or use the jobImmediateStart property to indicate the position is to be filled as soon as possible. | |
| jobTitle | The job title of the person (for example, Financial Manager). | |
| jurisdiction | Indicates a legal jurisdiction, e.g. of some legislation, or where some government service is based. | |
| keywords | Keywords or tags used to describe this content. Multiple entries in a keywords list are typically delimited by commas. | |
| knownVehicleDamages | A textual description of known damages, both repaired and unrepaired. | |
| knows | The most generic bi-directional social/work relation. | |
| knowsAbout | Of a Person, and less typically of an Organization, to indicate a topic that is known about - suggesting possible expertise but not implying it. We do not distinguish skill levels here, or relate this to educational content, events, objectives or JobPosting descriptions. | |
| knowsLanguage | Of a Person, and less typically of an Organization, to indicate a known language. We do not distinguish skill levels or reading/writing/speaking/signing here. Use language codes from the IETF BCP 47 standard. | |
| labelDetails | Link to the drug's label details. | |
| landlord | A sub property of participant. The owner of the real estate property. | |
| language | A sub property of instrument. The language used on this action. | |
| lastReviewed | Date on which the content on this web page was last reviewed for accuracy and/or completeness. | |
| latitude | The latitude of a location. For example 37.42242 (WGS 84). |
|
| layoutImage | A schematic image showing the floorplan layout. | |
| learningResourceType | The predominant type or kind characterizing the learning resource. For example, 'presentation', 'handout'. | |
| leaseLength | Length of the lease for some Accommodation, either particular to some Offer or in some cases intrinsic to the property. | |
| legalName | The official name of the organization, e.g. the registered company name. | |
| legalStatus | The drug or supplement's legal status, including any controlled substance schedules that apply. | |
| legislationApplies | Indicates that this legislation (or part of a legislation) somehow transfers another legislation in a different legislative context. This is an informative link, and it has no legal value. For legally-binding links of transposition, use the legislationTransposes property. For example an informative consolidated law of a European Union's member state "applies" the consolidated version of the European Directive implemented in it. | |
| legislationChanges | Another legislation that this legislation changes. This encompasses the notions of amendment, replacement, correction, repeal, or other types of change. This may be a direct change (textual or non-textual amendment) or a consequential or indirect change. The property is to be used to express the existence of a change relationship between two acts rather than the existence of a consolidated version of the text that shows the result of the change. For consolidation relationships, use the legislationConsolidates property. | |
| legislationConsolidates | Indicates another legislation taken into account in this consolidated legislation (which is usually the product of an editorial process that revises the legislation). This property should be used multiple times to refer to both the original version or the previous consolidated version, and to the legislations making the change. | |
| legislationDate | The date of adoption or signature of the legislation. This is the date at which the text is officially aknowledged to be a legislation, even though it might not even be published or in force. | |
| legislationDateVersion | The point-in-time at which the provided description of the legislation is valid (e.g. : when looking at the law on the 2016-04-07 (= dateVersion), I get the consolidation of 2015-04-12 of the "National Insurance Contributions Act 2015") | |
| legislationIdentifier | An identifier for the legislation. This can be either a string-based identifier, like the CELEX at EU level or the NOR in France, or a web-based, URL/URI identifier, like an ELI (European Legislation Identifier) or an URN-Lex. | |
| legislationJurisdiction | The jurisdiction from which the legislation originates. | |
| legislationLegalForce | Whether the legislation is currently in force, not in force, or partially in force. | |
| legislationLegalValue | The legal value of this legislation file. The same legislation can be written in multiple files with different legal values. Typically a digitally signed PDF have a "stronger" legal value than the HTML file of the same act. | |
| legislationPassedBy | The person or organization that originally passed or made the law : typically parliament (for primary legislation) or government (for secondary legislation). This indicates the "legal author" of the law, as opposed to its physical author. | |
| legislationResponsible | An individual or organization that has some kind of responsibility for the legislation. Typically the ministry who is/was in charge of elaborating the legislation, or the adressee for potential questions about the legislation once it is published. | |
| legislationTransposes | Indicates that this legislation (or part of legislation) fulfills the objectives set by another legislation, by passing appropriate implementation measures. Typically, some legislations of European Union's member states or regions transpose European Directives. This indicates a legally binding link between the 2 legislations. | |
| legislationType | The type of the legislation. Examples of values are "law", "act", "directive", "decree", "regulation", "statutory instrument", "loi organique", "règlement grand-ducal", etc., depending on the country. | |
| leiCode | An organization identifier that uniquely identifies a legal entity as defined in ISO 17442. | |
| lender | A sub property of participant. The person that lends the object being borrowed. | |
| lesser | This ordering relation for qualitative values indicates that the subject is lesser than the object. | |
| lesserOrEqual | This ordering relation for qualitative values indicates that the subject is lesser than or equal to the object. | |
| letterer | The individual who adds lettering, including speech balloons and sound effects, to artwork. | |
| license | A license document that applies to this content, typically indicated by URL. | |
| line | A line is a point-to-point path consisting of two or more points. A line is expressed as a series of two or more point objects separated by space. | |
| linkRelationship | Indicates the relationship type of a Web link. | |
| liveBlogUpdate | An update to the LiveBlog. | |
| loanMortgageMandateAmount | Amount of mortgage mandate that can be converted into a proper mortgage at a later stage. | |
| loanPaymentAmount | The amount of money to pay in a single payment. | |
| loanPaymentFrequency | Frequency of payments due, i.e. number of months between payments. This is defined as a frequency, i.e. the reciprocal of a period of time. | |
| loanRepaymentForm | A form of paying back money previously borrowed from a lender. Repayment usually takes the form of periodic payments that normally include part principal plus interest in each payment. | |
| loanTerm | The duration of the loan or credit agreement. | |
| loanType | The type of a loan or credit. | |
| location | The location of, for example, where an event is happening, where an organization is located, or where an action takes place. | |
| locationCreated | The location where the CreativeWork was created, which may not be the same as the location depicted in the CreativeWork. | |
| lodgingUnitDescription | A full description of the lodging unit. | |
| lodgingUnitType | Textual description of the unit type (including suite vs. room, size of bed, etc.). | |
| logo | An associated logo. | |
| longitude | The longitude of a location. For example -122.08585 (WGS 84). |
|
| loser | A sub property of participant. The loser of the action. | |
| lowPrice | The lowest price of all offers available. Usage guidelines:
|
|
| lyricist | The person who wrote the words. | |
| lyrics | The words in the song. | |
| mainContentOfPage | Indicates if this web page element is the main subject of the page. | |
| mainEntity | Indicates the primary entity described in some page or other CreativeWork. | |
| mainEntityOfPage | Indicates a page (or other CreativeWork) for which this thing is the main entity being described. See background notes for details. | |
| maintainer | A maintainer of a Dataset, software package (SoftwareApplication), or other Project. A maintainer is a Person or Organization that manages contributions to, and/or publication of, some (typically complex) artifact. It is common for distributions of software and data to be based on "upstream" sources. When maintainer is applied to a specific version of something e.g. a particular version or packaging of a Dataset, it is always possible that the upstream source has a different maintainer. The isBasedOn property can be used to indicate such relationships between datasets to make the different maintenance roles clear. Similarly in the case of software, a package may have dedicated maintainers working on integration into software distributions such as Ubuntu, as well as upstream maintainers of the underlying work. | |
| makesOffer | A pointer to products or services offered by the organization or person. | |
| manufacturer | The manufacturer of the product. | |
| map | A URL to a map of the place. | |
| mapType | Indicates the kind of Map, from the MapCategoryType Enumeration. | |
| maps | A URL to a map of the place. | |
| marginOfError | A marginOfError for an Observation. | |
| masthead | For a NewsMediaOrganization, a link to the masthead page or a page listing top editorial management. | |
| material | A material that something is made from, e.g. leather, wool, cotton, paper. | |
| materialExtent | The quantity of the materials being described or an expression of the physical space they occupy. | |
| mathExpression | A mathematical expression (e.g. 'x^2-3x=0') that may be solved for a specific variable, simplified, or transformed. This can take many formats, e.g. LaTeX, Ascii-Math, or math as you would write with a keyboard. | |
| maxPrice | The highest price if the price is a range. | |
| maxValue | The upper value of some characteristic or property. | |
| maximumAttendeeCapacity | The total number of individuals that may attend an event or venue. | |
| maximumEnrollment | The maximum number of students who may be enrolled in the program. | |
| maximumIntake | Recommended intake of this supplement for a given population as defined by a specific recommending authority. | |
| maximumPhysicalAttendeeCapacity | The maximum physical attendee capacity of an Event whose eventAttendanceMode is OfflineEventAttendanceMode (or the offline aspects, in the case of a MixedEventAttendanceMode). | |
| maximumVirtualAttendeeCapacity | The maximum physical attendee capacity of an Event whose eventAttendanceMode is OnlineEventAttendanceMode (or the online aspects, in the case of a MixedEventAttendanceMode). | |
| mealService | Description of the meals that will be provided or available for purchase. | |
| measuredProperty | The measuredProperty of an Observation, either a schema.org property, a property from other RDF-compatible systems e.g. W3C RDF Data Cube, or schema.org extensions such as GS1's. | |
| measuredValue | The measuredValue of an Observation. | |
| measurementTechnique | A technique or technology used in a Dataset (or DataDownload, DataCatalog),
corresponding to the method used for measuring the corresponding variable(s) (described using variableMeasured). This is oriented towards scientific and scholarly dataset publication but may have broader applicability; it is not intended as a full representation of measurement, but rather as a high level summary for dataset discovery. For example, if variableMeasured is: molecule concentration, measurementTechnique could be: "mass spectrometry" or "nmr spectroscopy" or "colorimetry" or "immunofluorescence". If the variableMeasured is "depression rating", the measurementTechnique could be "Zung Scale" or "HAM-D" or "Beck Depression Inventory". If there are several variableMeasured properties recorded for some given data object, use a PropertyValue for each variableMeasured and attach the corresponding measurementTechnique. |
|
| mechanismOfAction | The specific biochemical interaction through which this drug or supplement produces its pharmacological effect. | |
| mediaAuthenticityCategory | Indicates a MediaManipulationRatingEnumeration classification of a media object (in the context of how it was published or shared). | |
| median | The median value. | |
| medicalAudience | Medical audience for page. | |
| medicalSpecialty | A medical specialty of the provider. | |
| medicineSystem | The system of medicine that includes this MedicalEntity, for example 'evidence-based', 'homeopathic', 'chiropractic', etc. | |
| meetsEmissionStandard | Indicates that the vehicle meets the respective emission standard. | |
| member | A member of an Organization or a ProgramMembership. Organizations can be members of organizations; ProgramMembership is typically for individuals. | |
| memberOf | An Organization (or ProgramMembership) to which this Person or Organization belongs. | |
| members | A member of this organization. | |
| membershipNumber | A unique identifier for the membership. | |
| membershipPointsEarned | The number of membership points earned by the member. If necessary, the unitText can be used to express the units the points are issued in. (e.g. stars, miles, etc.) | |
| memoryRequirements | Minimum memory requirements. | |
| mentions | Indicates that the CreativeWork contains a reference to, but is not necessarily about a concept. | |
| menu | Either the actual menu as a structured representation, as text, or a URL of the menu. | |
| menuAddOn | Additional menu item(s) such as a side dish of salad or side order of fries that can be added to this menu item. Additionally it can be a menu section containing allowed add-on menu items for this menu item. | |
| merchant | 'merchant' is an out-dated term for 'seller'. | |
| merchantReturnDays | The merchantReturnDays property indicates the number of days (from purchase) within which relevant merchant return policy is applicable. | |
| merchantReturnLink | Indicates a Web page or service by URL, for product return. | |
| messageAttachment | A CreativeWork attached to the message. | |
| mileageFromOdometer | The total distance travelled by the particular vehicle since its initial production, as read from its odometer. Typical unit code(s): KMT for kilometers, SMI for statute miles |
|
| minPrice | The lowest price if the price is a range. | |
| minValue | The lower value of some characteristic or property. | |
| minimumPaymentDue | The minimum payment required at this time. | |
| missionCoveragePrioritiesPolicy | For a NewsMediaOrganization, a statement on coverage priorities, including any public agenda or stance on issues. | |
| model | The model of the product. Use with the URL of a ProductModel or a textual representation of the model identifier. The URL of the ProductModel can be from an external source. It is recommended to additionally provide strong product identifiers via the gtin8/gtin13/gtin14 and mpn properties. | |
| modelDate | The release date of a vehicle model (often used to differentiate versions of the same make and model). | |
| modifiedTime | The date and time the reservation was modified. | |
| monthlyMinimumRepaymentAmount | The minimum payment is the lowest amount of money that one is required to pay on a credit card statement each month. | |
| monthsOfExperience | Indicates the minimal number of months of experience required for a position. | |
| mpn | The Manufacturer Part Number (MPN) of the product, or the product to which the offer refers. | |
| multipleValues | Whether multiple values are allowed for the property. Default is false. | |
| muscleAction | The movement the muscle generates. | |
| musicArrangement | An arrangement derived from the composition. | |
| musicBy | The composer of the soundtrack. | |
| musicCompositionForm | The type of composition (e.g. overture, sonata, symphony, etc.). | |
| musicGroupMember | A member of a music group—for example, John, Paul, George, or Ringo. | |
| musicReleaseFormat | Format of this release (the type of recording media used, ie. compact disc, digital media, LP, etc.). | |
| musicalKey | The key, mode, or scale this composition uses. | |
| naics | The North American Industry Classification System (NAICS) code for a particular organization or business person. | |
| name | The name of the item. | |
| namedPosition | A position played, performed or filled by a person or organization, as part of an organization. For example, an athlete in a SportsTeam might play in the position named 'Quarterback'. | |
| nationality | Nationality of the person. | |
| naturalProgression | The expected progression of the condition if it is not treated and allowed to progress naturally. | |
| nerve | The underlying innervation associated with the muscle. | |
| nerveMotor | The neurological pathway extension that involves muscle control. | |
| netWorth | The total financial value of the person as calculated by subtracting assets from liabilities. | |
| newsUpdatesAndGuidelines | Indicates a page with news updates and guidelines. This could often be (but is not required to be) the main page containing SpecialAnnouncement markup on a site. | |
| nextItem | A link to the ListItem that follows the current one. | |
| noBylinesPolicy | For a NewsMediaOrganization or other news-related Organization, a statement explaining when authors of articles are not named in bylines. | |
| nonEqual | This ordering relation for qualitative values indicates that the subject is not equal to the object. | |
| nonProprietaryName | The generic name of this drug or supplement. | |
| nonprofitStatus | nonprofit Status indicates the legal status of a non-profit organization in its primary place of business. | |
| normalRange | Range of acceptable values for a typical patient, when applicable. | |
| nsn | Indicates the NATO stock number (nsn) of a Product. | |
| numAdults | The number of adults staying in the unit. | |
| numChildren | The number of children staying in the unit. | |
| numConstraints | Indicates the number of constraints (not counting populationType) defined for a particular StatisticalPopulation. This helps applications understand if they have access to a sufficiently complete description of a StatisticalPopulation. | |
| numTracks | The number of tracks in this album or playlist. | |
| numberOfAccommodationUnits | Indicates the total (available plus unavailable) number of accommodation units in an ApartmentComplex, or the number of accommodation units for a specific FloorPlan (within its specific ApartmentComplex). See also numberOfAvailableAccommodationUnits. | |
| numberOfAirbags | The number or type of airbags in the vehicle. | |
| numberOfAvailableAccommodationUnits | Indicates the number of available accommodation units in an ApartmentComplex, or the number of accommodation units for a specific FloorPlan (within its specific ApartmentComplex). See also numberOfAccommodationUnits. | |
| numberOfAxles | The number of axles. Typical unit code(s): C62 |
|
| numberOfBathroomsTotal | The total integer number of bathrooms in a some Accommodation, following real estate conventions as documented in RESO: "The simple sum of the number of bathrooms. For example for a property with two Full Bathrooms and one Half Bathroom, the Bathrooms Total Integer will be 3.". See also numberOfRooms. | |
| numberOfBedrooms | The total integer number of bedrooms in a some Accommodation, ApartmentComplex or FloorPlan. | |
| numberOfBeds | The quantity of the given bed type available in the HotelRoom, Suite, House, or Apartment. | |
| numberOfCredits | The number of credits or units awarded by a Course or required to complete an EducationalOccupationalProgram. | |
| numberOfDoors | The number of doors. Typical unit code(s): C62 |
|
| numberOfEmployees | The number of employees in an organization e.g. business. | |
| numberOfEpisodes | The number of episodes in this season or series. | |
| numberOfForwardGears | The total number of forward gears available for the transmission system of the vehicle. Typical unit code(s): C62 |
|
| numberOfFullBathrooms | Number of full bathrooms - The total number of full and ¾ bathrooms in an Accommodation. This corresponds to the BathroomsFull field in RESO. | |
| numberOfItems | The number of items in an ItemList. Note that some descriptions might not fully describe all items in a list (e.g., multi-page pagination); in such cases, the numberOfItems would be for the entire list. | |
| numberOfLoanPayments | The number of payments contractually required at origination to repay the loan. For monthly paying loans this is the number of months from the contractual first payment date to the maturity date. | |
| numberOfPages | The number of pages in the book. | |
| numberOfPartialBathrooms | Number of partial bathrooms - The total number of half and ¼ bathrooms in an Accommodation. This corresponds to the BathroomsPartial field in RESO. | |
| numberOfPlayers | Indicate how many people can play this game (minimum, maximum, or range). | |
| numberOfPreviousOwners | The number of owners of the vehicle, including the current one. Typical unit code(s): C62 |
|
| numberOfRooms | The number of rooms (excluding bathrooms and closets) of the accommodation or lodging business. Typical unit code(s): ROM for room or C62 for no unit. The type of room can be put in the unitText property of the QuantitativeValue. | |
| numberOfSeasons | The number of seasons in this series. | |
| numberedPosition | A number associated with a role in an organization, for example, the number on an athlete's jersey. | |
| nutrition | Nutrition information about the recipe or menu item. | |
| object | The object upon which the action is carried out, whose state is kept intact or changed. Also known as the semantic roles patient, affected or undergoer (which change their state) or theme (which doesn't). e.g. John read a book. | |
| observationDate | The observationDate of an Observation. | |
| observedNode | The observedNode of an Observation, often a StatisticalPopulation. | |
| occupancy | The allowed total occupancy for the accommodation in persons (including infants etc). For individual accommodations, this is not necessarily the legal maximum but defines the permitted usage as per the contractual agreement (e.g. a double room used by a single person). Typical unit code(s): C62 for person | |
| occupationLocation | The region/country for which this occupational description is appropriate. Note that educational requirements and qualifications can vary between jurisdictions. | |
| occupationalCategory | A category describing the job, preferably using a term from a taxonomy such as BLS O*NET-SOC, ISCO-08 or similar, with the property repeated for each applicable value. Ideally the taxonomy should be identified, and both the textual label and formal code for the category should be provided. Note: for historical reasons, any textual label and formal code provided as a literal may be assumed to be from O*NET-SOC. |
|
| occupationalCredentialAwarded | A description of the qualification, award, certificate, diploma or other occupational credential awarded as a consequence of successful completion of this course or program. | |
| offerCount | The number of offers for the product. | |
| offeredBy | A pointer to the organization or person making the offer. | |
| offers | An offer to provide this item—for example, an offer to sell a product, rent the DVD of a movie, perform a service, or give away tickets to an event. Use businessFunction to indicate the kind of transaction offered, i.e. sell, lease, etc. This property can also be used to describe a Demand. While this property is listed as expected on a number of common types, it can be used in others. In that case, using a second type, such as Product or a subtype of Product, can clarify the nature of the offer. | |
| offersPrescriptionByMail | Whether prescriptions can be delivered by mail. | |
| openingHours | The general opening hours for a business. Opening hours can be specified as a weekly time range, starting with days, then times per day. Multiple days can be listed with commas ',' separating each day. Day or time ranges are specified using a hyphen '-'.
|
|
| openingHoursSpecification | The opening hours of a certain place. | |
| opens | The opening hour of the place or service on the given day(s) of the week. | |
| operatingSystem | Operating systems supported (Windows 7, OSX 10.6, Android 1.6). | |
| opponent | A sub property of participant. The opponent on this action. | |
| option | A sub property of object. The options subject to this action. | |
| orderDate | Date order was placed. | |
| orderDelivery | The delivery of the parcel related to this order or order item. | |
| orderItemNumber | The identifier of the order item. | |
| orderItemStatus | The current status of the order item. | |
| orderNumber | The identifier of the transaction. | |
| orderQuantity | The number of the item ordered. If the property is not set, assume the quantity is one. | |
| orderStatus | The current status of the order. | |
| orderedItem | The item ordered. | |
| organizer | An organizer of an Event. | |
| originAddress | Shipper's address. | |
| originatesFrom | The vasculature the lymphatic structure originates, or afferents, from. | |
| overdosage | Any information related to overdose on a drug, including signs or symptoms, treatments, contact information for emergency response. | |
| ownedFrom | The date and time of obtaining the product. | |
| ownedThrough | The date and time of giving up ownership on the product. | |
| ownershipFundingInfo | For an Organization (often but not necessarily a NewsMediaOrganization), a description of organizational ownership structure; funding and grants. In a news/media setting, this is with particular reference to editorial independence. Note that the funder is also available and can be used to make basic funder information machine-readable. | |
| owns | Products owned by the organization or person. | |
| pageEnd | The page on which the work ends; for example "138" or "xvi". | |
| pageStart | The page on which the work starts; for example "135" or "xiii". | |
| pagination | Any description of pages that is not separated into pageStart and pageEnd; for example, "1-6, 9, 55" or "10-12, 46-49". | |
| parent | A parent of this person. | |
| parentItem | The parent of a question, answer or item in general. | |
| parentOrganization | The larger organization that this organization is a subOrganization of, if any. | |
| parentService | A broadcast service to which the broadcast service may belong to such as regional variations of a national channel. | |
| parents | A parents of the person. | |
| partOfEpisode | The episode to which this clip belongs. | |
| partOfInvoice | The order is being paid as part of the referenced Invoice. | |
| partOfOrder | The overall order the items in this delivery were included in. | |
| partOfSeason | The season to which this episode belongs. | |
| partOfSeries | The series to which this episode or season belongs. | |
| partOfSystem | The anatomical or organ system that this structure is part of. | |
| partOfTVSeries | The TV series to which this episode or season belongs. | |
| partOfTrip | Identifies that this Trip is a subTrip of another Trip. For example Day 1, Day 2, etc. of a multi-day trip. | |
| participant | Other co-agents that participated in the action indirectly. e.g. John wrote a book with Steve. | |
| partySize | Number of people the reservation should accommodate. | |
| passengerPriorityStatus | The priority status assigned to a passenger for security or boarding (e.g. FastTrack or Priority). | |
| passengerSequenceNumber | The passenger's sequence number as assigned by the airline. | |
| pathophysiology | Changes in the normal mechanical, physical, and biochemical functions that are associated with this activity or condition. | |
| pattern | A pattern that something has, for example 'polka dot', 'striped', 'Canadian flag'. Values are typically expressed as text, although links to controlled value schemes are also supported. | |
| payload | The permitted weight of passengers and cargo, EXCLUDING the weight of the empty vehicle. Typical unit code(s): KGM for kilogram, LBR for pound
|
|
| paymentAccepted | Cash, Credit Card, Cryptocurrency, Local Exchange Tradings System, etc. | |
| paymentDue | The date that payment is due. | |
| paymentDueDate | The date that payment is due. | |
| paymentMethod | The name of the credit card or other method of payment for the order. | |
| paymentMethodId | An identifier for the method of payment used (e.g. the last 4 digits of the credit card). | |
| paymentStatus | The status of payment; whether the invoice has been paid or not. | |
| paymentUrl | The URL for sending a payment. | |
| penciler | The individual who draws the primary narrative artwork. | |
| percentile10 | The 10th percentile value. | |
| percentile25 | The 25th percentile value. | |
| percentile75 | The 75th percentile value. | |
| percentile90 | The 90th percentile value. | |
| performTime | The length of time it takes to perform instructions or a direction (not including time to prepare the supplies), in ISO 8601 duration format. | |
| performer | A performer at the event—for example, a presenter, musician, musical group or actor. | |
| performerIn | Event that this person is a performer or participant in. | |
| performers | The main performer or performers of the event—for example, a presenter, musician, or actor. | |
| permissionType | The type of permission granted the person, organization, or audience. | |
| permissions | Permission(s) required to run the app (for example, a mobile app may require full internet access or may run only on wifi). | |
| permitAudience | The target audience for this permit. | |
| permittedUsage | Indications regarding the permitted usage of the accommodation. | |
| petsAllowed | Indicates whether pets are allowed to enter the accommodation or lodging business. More detailed information can be put in a text value. | |
| phoneticText | Representation of a text textValue using the specified speechToTextMarkup. For example the city name of Houston in IPA: /ˈhjuːstən/. | |
| photo | A photograph of this place. | |
| photos | Photographs of this place. | |
| physicalRequirement | A description of the types of physical activity associated with the job. Defined terms such as those in O*net may be used, but note that there is no way to specify the level of ability as well as its nature when using a defined term. | |
| physiologicalBenefits | Specific physiologic benefits associated to the plan. | |
| pickupLocation | Where a taxi will pick up a passenger or a rental car can be picked up. | |
| pickupTime | When a taxi will pickup a passenger or a rental car can be picked up. | |
| playMode | Indicates whether this game is multi-player, co-op or single-player. The game can be marked as multi-player, co-op and single-player at the same time. | |
| playerType | Player type required—for example, Flash or Silverlight. | |
| playersOnline | Number of players on the server. | |
| polygon | A polygon is the area enclosed by a point-to-point path for which the starting and ending points are the same. A polygon is expressed as a series of four or more space delimited points where the first and final points are identical. | |
| populationType | Indicates the populationType common to all members of a StatisticalPopulation. | |
| position | The position of an item in a series or sequence of items. | |
| possibleComplication | A possible unexpected and unfavorable evolution of a medical condition. Complications may include worsening of the signs or symptoms of the disease, extension of the condition to other organ systems, etc. | |
| possibleTreatment | A possible treatment to address this condition, sign or symptom. | |
| postOfficeBoxNumber | The post office box number for PO box addresses. | |
| postOp | A description of the postoperative procedures, care, and/or followups for this device. | |
| postalCode | The postal code. For example, 94043. | |
| postalCodeBegin | First postal code in a range (included). | |
| postalCodeEnd | Last postal code in the range (included). Needs to be after postalCodeBegin. | |
| postalCodePrefix | A defined range of postal codes indicated by a common textual prefix. Used for non-numeric systems such as UK. | |
| postalCodeRange | A defined range of postal codes. | |
| potentialAction | Indicates a potential Action, which describes an idealized action in which this thing would play an 'object' role. | |
| preOp | A description of the workup, testing, and other preparations required before implanting this device. | |
| predecessorOf | A pointer from a previous, often discontinued variant of the product to its newer variant. | |
| pregnancyCategory | Pregnancy category of this drug. | |
| pregnancyWarning | Any precaution, guidance, contraindication, etc. related to this drug's use during pregnancy. | |
| prepTime | The length of time it takes to prepare the items to be used in instructions or a direction, in ISO 8601 duration format. | |
| preparation | Typical preparation that a patient must undergo before having the procedure performed. | |
| prescribingInfo | Link to prescribing information for the drug. | |
| prescriptionStatus | Indicates the status of drug prescription eg. local catalogs classifications or whether the drug is available by prescription or over-the-counter, etc. | |
| previousItem | A link to the ListItem that preceeds the current one. | |
| previousStartDate | Used in conjunction with eventStatus for rescheduled or cancelled events. This property contains the previously scheduled start date. For rescheduled events, the startDate property should be used for the newly scheduled start date. In the (rare) case of an event that has been postponed and rescheduled multiple times, this field may be repeated. | |
| price | The offer price of a product, or of a price component when attached to PriceSpecification and its subtypes. Usage guidelines:
|
|
| priceComponent | This property links to all UnitPriceSpecification nodes that apply in parallel for the CompoundPriceSpecification node. | |
| priceComponentType | Identifies a price component (for example, a line item on an invoice), part of the total price for an offer. | |
| priceCurrency | The currency of the price, or a price component when attached to PriceSpecification and its subtypes. Use standard formats: ISO 4217 currency format e.g. "USD"; Ticker symbol for cryptocurrencies e.g. "BTC"; well known names for Local Exchange Tradings Systems (LETS) and other currency types e.g. "Ithaca HOUR". |
|
| priceRange | The price range of the business, for example $$$. |
|
| priceSpecification | One or more detailed price specifications, indicating the unit price and delivery or payment charges. | |
| priceType | Defines the type of a price specified for an offered product, for example a list price, a (temporary) sale price or a manufacturer suggested retail price. If multiple prices are specified for an offer the priceType property can be used to identify the type of each such specified price. The value of priceType can be specified as a value from enumeration PriceTypeEnumeration or as a free form text string for price types that are not already predefined in PriceTypeEnumeration. | |
| priceValidUntil | The date after which the price is no longer available. | |
| primaryImageOfPage | Indicates the main image on the page. | |
| primaryPrevention | A preventative therapy used to prevent an initial occurrence of the medical condition, such as vaccination. | |
| printColumn | The number of the column in which the NewsArticle appears in the print edition. | |
| printEdition | The edition of the print product in which the NewsArticle appears. | |
| printPage | If this NewsArticle appears in print, this field indicates the name of the page on which the article is found. Please note that this field is intended for the exact page name (e.g. A5, B18). | |
| printSection | If this NewsArticle appears in print, this field indicates the print section in which the article appeared. | |
| procedure | A description of the procedure involved in setting up, using, and/or installing the device. | |
| procedureType | The type of procedure, for example Surgical, Noninvasive, or Percutaneous. | |
| processingTime | Estimated processing time for the service using this channel. | |
| processorRequirements | Processor architecture required to run the application (e.g. IA64). | |
| producer | The person or organization who produced the work (e.g. music album, movie, tv/radio series etc.). | |
| produces | The tangible thing generated by the service, e.g. a passport, permit, etc. | |
| productGroupID | Indicates a textual identifier for a ProductGroup. | |
| productID | The product identifier, such as ISBN. For example: meta itemprop="productID" content="isbn:123-456-789". |
|
| productSupported | The product or service this support contact point is related to (such as product support for a particular product line). This can be a specific product or product line (e.g. "iPhone") or a general category of products or services (e.g. "smartphones"). | |
| productionCompany | The production company or studio responsible for the item e.g. series, video game, episode etc. | |
| productionDate | The date of production of the item, e.g. vehicle. | |
| proficiencyLevel | Proficiency needed for this content; expected values: 'Beginner', 'Expert'. | |
| programMembershipUsed | Any membership in a frequent flyer, hotel loyalty program, etc. being applied to the reservation. | |
| programName | The program providing the membership. | |
| programPrerequisites | Prerequisites for enrolling in the program. | |
| programType | The type of educational or occupational program. For example, classroom, internship, alternance, etc.. | |
| programmingLanguage | The computer programming language. | |
| programmingModel | Indicates whether API is managed or unmanaged. | |
| propertyID | A commonly used identifier for the characteristic represented by the property, e.g. a manufacturer or a standard code for a property. propertyID can be (1) a prefixed string, mainly meant to be used with standards for product properties; (2) a site-specific, non-prefixed string (e.g. the primary key of the property or the vendor-specific id of the property), or (3) a URL indicating the type of the property, either pointing to an external vocabulary, or a Web resource that describes the property (e.g. a glossary entry). Standards bodies should promote a standard prefix for the identifiers of properties from their standards. | |
| proprietaryName | Proprietary name given to the diet plan, typically by its originator or creator. | |
| proteinContent | The number of grams of protein. | |
| provider | The service provider, service operator, or service performer; the goods producer. Another party (a seller) may offer those services or goods on behalf of the provider. A provider may also serve as the seller. | |
| providerMobility | Indicates the mobility of a provided service (e.g. 'static', 'dynamic'). | |
| providesBroadcastService | The BroadcastService offered on this channel. | |
| providesService | The service provided by this channel. | |
| publicAccess | A flag to signal that the Place is open to public visitors. If this property is omitted there is no assumed default boolean value | |
| publicTransportClosuresInfo | Information about public transport closures. | |
| publication | A publication event associated with the item. | |
| publicationType | The type of the medical article, taken from the US NLM MeSH publication type catalog. See also MeSH documentation. | |
| publishedBy | An agent associated with the publication event. | |
| publishedOn | A broadcast service associated with the publication event. | |
| publisher | The publisher of the creative work. | |
| publisherImprint | The publishing division which published the comic. | |
| publishingPrinciples | The publishingPrinciples property indicates (typically via URL) a document describing the editorial principles of an Organization (or individual e.g. a Person writing a blog) that relate to their activities as a publisher, e.g. ethics or diversity policies. When applied to a CreativeWork (e.g. NewsArticle) the principles are those of the party primarily responsible for the creation of the CreativeWork. While such policies are most typically expressed in natural language, sometimes related information (e.g. indicating a funder) can be expressed using schema.org terminology. |
|
| purchaseDate | The date the item e.g. vehicle was purchased by the current owner. | |
| qualifications | Specific qualifications required for this role or Occupation. | |
| quarantineGuidelines | Guidelines about quarantine rules, e.g. in the context of a pandemic. | |
| query | A sub property of instrument. The query used on this action. | |
| quest | The task that a player-controlled character, or group of characters may complete in order to gain a reward. | |
| question | A sub property of object. A question. | |
| rangeIncludes | Relates a property to a class that constitutes (one of) the expected type(s) for values of the property. | |
| ratingCount | The count of total number of ratings. | |
| ratingExplanation | A short explanation (e.g. one to two sentences) providing background context and other information that led to the conclusion expressed in the rating. This is particularly applicable to ratings associated with "fact check" markup using ClaimReview. | |
| ratingValue | The rating for the content. Usage guidelines:
|
|
| readBy | A person who reads (performs) the audiobook. | |
| readonlyValue | Whether or not a property is mutable. Default is false. Specifying this for a property that also has a value makes it act similar to a "hidden" input in an HTML form. | |
| realEstateAgent | A sub property of participant. The real estate agent involved in the action. | |
| recipe | A sub property of instrument. The recipe/instructions used to perform the action. | |
| recipeCategory | The category of the recipe—for example, appetizer, entree, etc. | |
| recipeCuisine | The cuisine of the recipe (for example, French or Ethiopian). | |
| recipeIngredient | A single ingredient used in the recipe, e.g. sugar, flour or garlic. | |
| recipeInstructions | A step in making the recipe, in the form of a single item (document, video, etc.) or an ordered list with HowToStep and/or HowToSection items. | |
| recipeYield | The quantity produced by the recipe (for example, number of people served, number of servings, etc). | |
| recipient | A sub property of participant. The participant who is at the receiving end of the action. | |
| recognizedBy | An organization that acknowledges the validity, value or utility of a credential. Note: recognition may include a process of quality assurance or accreditation. | |
| recognizingAuthority | If applicable, the organization that officially recognizes this entity as part of its endorsed system of medicine. | |
| recommendationStrength | Strength of the guideline's recommendation (e.g. 'class I'). | |
| recommendedIntake | Recommended intake of this supplement for a given population as defined by a specific recommending authority. | |
| recordLabel | The label that issued the release. | |
| recordedAs | An audio recording of the work. | |
| recordedAt | The Event where the CreativeWork was recorded. The CreativeWork may capture all or part of the event. | |
| recordedIn | The CreativeWork that captured all or part of this Event. | |
| recordingOf | The composition this track is a recording of. | |
| recourseLoan | The only way you get the money back in the event of default is the security. Recourse is where you still have the opportunity to go back to the borrower for the rest of the money. | |
| referenceQuantity | The reference quantity for which a certain price applies, e.g. 1 EUR per 4 kWh of electricity. This property is a replacement for unitOfMeasurement for the advanced cases where the price does not relate to a standard unit. | |
| referencesOrder | The Order(s) related to this Invoice. One or more Orders may be combined into a single Invoice. | |
| refundType | A refundType, from an enumerated list. | |
| regionDrained | The anatomical or organ system drained by this vessel; generally refers to a specific part of an organ. | |
| regionsAllowed | The regions where the media is allowed. If not specified, then it's assumed to be allowed everywhere. Specify the countries in ISO 3166 format. | |
| relatedAnatomy | Anatomical systems or structures that relate to the superficial anatomy. | |
| relatedCondition | A medical condition associated with this anatomy. | |
| relatedDrug | Any other drug related to this one, for example commonly-prescribed alternatives. | |
| relatedLink | A link related to this web page, for example to other related web pages. | |
| relatedStructure | Related anatomical structure(s) that are not part of the system but relate or connect to it, such as vascular bundles associated with an organ system. | |
| relatedTherapy | A medical therapy related to this anatomy. | |
| relatedTo | The most generic familial relation. | |
| releaseDate | The release date of a product or product model. This can be used to distinguish the exact variant of a product. | |
| releaseNotes | Description of what changed in this version. | |
| releaseOf | The album this is a release of. | |
| releasedEvent | The place and time the release was issued, expressed as a PublicationEvent. | |
| relevantOccupation | The Occupation for the JobPosting. | |
| relevantSpecialty | If applicable, a medical specialty in which this entity is relevant. | |
| remainingAttendeeCapacity | The number of attendee places for an event that remain unallocated. | |
| renegotiableLoan | Whether the terms for payment of interest can be renegotiated during the life of the loan. | |
| repeatCount | Defines the number of times a recurring Event will take place | |
| repeatFrequency | Defines the frequency at which Events will occur according to a schedule Schedule. The intervals between events should be defined as a Duration of time. | |
| repetitions | Number of times one should repeat the activity. | |
| replacee | A sub property of object. The object that is being replaced. | |
| replacer | A sub property of object. The object that replaces. | |
| replyToUrl | The URL at which a reply may be posted to the specified UserComment. | |
| reportNumber | The number or other unique designator assigned to a Report by the publishing organization. | |
| representativeOfPage | Indicates whether this image is representative of the content of the page. | |
| requiredCollateral | Assets required to secure loan or credit repayments. It may take form of third party pledge, goods, financial instruments (cash, securities, etc.) | |
| requiredGender | Audiences defined by a person's gender. | |
| requiredMaxAge | Audiences defined by a person's maximum age. | |
| requiredMinAge | Audiences defined by a person's minimum age. | |
| requiredQuantity | The required quantity of the item(s). | |
| requirements | Component dependency requirements for application. This includes runtime environments and shared libraries that are not included in the application distribution package, but required to run the application (Examples: DirectX, Java or .NET runtime). | |
| requiresSubscription | Indicates if use of the media require a subscription (either paid or free). Allowed values are true or false (note that an earlier version had 'yes', 'no'). |
|
| reservationFor | The thing -- flight, event, restaurant,etc. being reserved. | |
| reservationId | A unique identifier for the reservation. | |
| reservationStatus | The current status of the reservation. | |
| reservedTicket | A ticket associated with the reservation. | |
| responsibilities | Responsibilities associated with this role or Occupation. | |
| restPeriods | How often one should break from the activity. | |
| result | The result produced in the action. e.g. John wrote a book. | |
| resultComment | A sub property of result. The Comment created or sent as a result of this action. | |
| resultReview | A sub property of result. The review that resulted in the performing of the action. | |
| returnFees | Indicates (via enumerated options) the return fees policy for a MerchantReturnPolicy | |
| returnPolicyCategory | A returnPolicyCategory expresses at most one of several enumerated kinds of return. | |
| review | A review of the item. | |
| reviewAspect | This Review or Rating is relevant to this part or facet of the itemReviewed. | |
| reviewBody | The actual body of the review. | |
| reviewCount | The count of total number of reviews. | |
| reviewRating | The rating given in this review. Note that reviews can themselves be rated. The reviewRating applies to rating given by the review. The aggregateRating property applies to the review itself, as a creative work. |
|
| reviewedBy | People or organizations that have reviewed the content on this web page for accuracy and/or completeness. | |
| reviews | Review of the item. | |
| riskFactor | A modifiable or non-modifiable factor that increases the risk of a patient contracting this condition, e.g. age, coexisting condition. | |
| risks | Specific physiologic risks associated to the diet plan. | |
| roleName | A role played, performed or filled by a person or organization. For example, the team of creators for a comic book might fill the roles named 'inker', 'penciller', and 'letterer'; or an athlete in a SportsTeam might play in the position named 'Quarterback'. | |
| roofLoad | The permitted total weight of cargo and installations (e.g. a roof rack) on top of the vehicle. Typical unit code(s): KGM for kilogram, LBR for pound
|
|
| rsvpResponse | The response (yes, no, maybe) to the RSVP. | |
| runsTo | The vasculature the lymphatic structure runs, or efferents, to. | |
| runtime | Runtime platform or script interpreter dependencies (Example - Java v1, Python2.3, .Net Framework 3.0). | |
| runtimePlatform | Runtime platform or script interpreter dependencies (Example - Java v1, Python2.3, .Net Framework 3.0). | |
| rxcui | The RxCUI drug identifier from RXNORM. | |
| safetyConsideration | Any potential safety concern associated with the supplement. May include interactions with other drugs and foods, pregnancy, breastfeeding, known adverse reactions, and documented efficacy of the supplement. | |
| salaryCurrency | The currency (coded using ISO 4217 ) used for the main salary information in this job posting or for this employee. | |
| salaryUponCompletion | The expected salary upon completing the training. | |
| sameAs | URL of a reference Web page that unambiguously indicates the item's identity. E.g. the URL of the item's Wikipedia page, Wikidata entry, or official website. | |
| sampleType | What type of code sample: full (compile ready) solution, code snippet, inline code, scripts, template. | |
| saturatedFatContent | The number of grams of saturated fat. | |
| scheduleTimezone | Indicates the timezone for which the time(s) indicated in the Schedule are given. The value provided should be among those listed in the IANA Time Zone Database. | |
| scheduledPaymentDate | The date the invoice is scheduled to be paid. | |
| scheduledTime | The time the object is scheduled to. | |
| schemaVersion | Indicates (by URL or string) a particular version of a schema used in some CreativeWork. This property was created primarily to
indicate the use of a specific schema.org release, e.g. 10.0 as a simple string, or more explicitly via URL, https://schema.org/docs/releases.html#v10.0. There may be situations in which other schemas might usefully be referenced this way, e.g. http://dublincore.org/specifications/dublin-core/dces/1999-07-02/ but this has not been carefully explored in the community. |
|
| schoolClosuresInfo | Information about school closures. | |
| screenCount | The number of screens in the movie theater. | |
| screenshot | A link to a screenshot image of the app. | |
| sdDatePublished | Indicates the date on which the current structured data was generated / published. Typically used alongside sdPublisher | |
| sdLicense | A license document that applies to this structured data, typically indicated by URL. | |
| sdPublisher | Indicates the party responsible for generating and publishing the current structured data markup, typically in cases where the structured data is derived automatically from existing published content but published on a different site. For example, student projects and open data initiatives often re-publish existing content with more explicitly structured metadata. The sdPublisher property helps make such practices more explicit. | |
| season | A season in a media series. | |
| seasonNumber | Position of the season within an ordered group of seasons. | |
| seasons | A season in a media series. | |
| seatNumber | The location of the reserved seat (e.g., 27). | |
| seatRow | The row location of the reserved seat (e.g., B). | |
| seatSection | The section location of the reserved seat (e.g. Orchestra). | |
| seatingCapacity | The number of persons that can be seated (e.g. in a vehicle), both in terms of the physical space available, and in terms of limitations set by law. Typical unit code(s): C62 for persons |
|
| seatingType | The type/class of the seat. | |
| secondaryPrevention | A preventative therapy used to prevent reoccurrence of the medical condition after an initial episode of the condition. | |
| securityClearanceRequirement | A description of any security clearance requirements of the job. | |
| securityScreening | The type of security screening the passenger is subject to. | |
| seeks | A pointer to products or services sought by the organization or person (demand). | |
| seller | An entity which offers (sells / leases / lends / loans) the services / goods. A seller may also be a provider. | |
| sender | A sub property of participant. The participant who is at the sending end of the action. | |
| sensoryRequirement | A description of any sensory requirements and levels necessary to function on the job, including hearing and vision. Defined terms such as those in O*net may be used, but note that there is no way to specify the level of ability as well as its nature when using a defined term. | |
| sensoryUnit | The neurological pathway extension that inputs and sends information to the brain or spinal cord. | |
| serialNumber | The serial number or any alphanumeric identifier of a particular product. When attached to an offer, it is a shortcut for the serial number of the product included in the offer. | |
| seriousAdverseOutcome | A possible serious complication and/or serious side effect of this therapy. Serious adverse outcomes include those that are life-threatening; result in death, disability, or permanent damage; require hospitalization or prolong existing hospitalization; cause congenital anomalies or birth defects; or jeopardize the patient and may require medical or surgical intervention to prevent one of the outcomes in this definition. | |
| serverStatus | Status of a game server. | |
| servesCuisine | The cuisine of the restaurant. | |
| serviceArea | The geographic area where the service is provided. | |
| serviceAudience | The audience eligible for this service. | |
| serviceLocation | The location (e.g. civic structure, local business, etc.) where a person can go to access the service. | |
| serviceOperator | The operating organization, if different from the provider. This enables the representation of services that are provided by an organization, but operated by another organization like a subcontractor. | |
| serviceOutput | The tangible thing generated by the service, e.g. a passport, permit, etc. | |
| servicePhone | The phone number to use to access the service. | |
| servicePostalAddress | The address for accessing the service by mail. | |
| serviceSmsNumber | The number to access the service by text message. | |
| serviceType | The type of service being offered, e.g. veterans' benefits, emergency relief, etc. | |
| serviceUrl | The website to access the service. | |
| servingSize | The serving size, in terms of the number of volume or mass. | |
| sharedContent | A CreativeWork such as an image, video, or audio clip shared as part of this posting. | |
| shippingDestination | indicates (possibly multiple) shipping destinations. These can be defined in several ways e.g. postalCode ranges. | |
| shippingDetails | Indicates information about the shipping policies and options associated with an Offer. | |
| shippingLabel | Label to match an OfferShippingDetails with a ShippingRateSettings (within the context of a shippingSettingsLink cross-reference). | |
| shippingRate | The shipping rate is the cost of shipping to the specified destination. Typically, the maxValue and currency values (of the MonetaryAmount) are most appropriate. | |
| shippingSettingsLink | Link to a page containing ShippingRateSettings and DeliveryTimeSettings details. | |
| sibling | A sibling of the person. | |
| siblings | A sibling of the person. | |
| signDetected | A sign detected by the test. | |
| signOrSymptom | A sign or symptom of this condition. Signs are objective or physically observable manifestations of the medical condition while symptoms are the subjective experience of the medical condition. | |
| significance | The significance associated with the superficial anatomy; as an example, how characteristics of the superficial anatomy can suggest underlying medical conditions or courses of treatment. | |
| significantLink | One of the more significant URLs on the page. Typically, these are the non-navigation links that are clicked on the most. | |
| significantLinks | The most significant URLs on the page. Typically, these are the non-navigation links that are clicked on the most. | |
| size | A standardized size of a product or creative work, specified either through a simple textual string (for example 'XL', '32Wx34L'), a QuantitativeValue with a unitCode, or a comprehensive and structured SizeSpecification; in other cases, the width, height, depth and weight properties may be more applicable. | |
| sizeGroup | The size group (also known as "size type") for a product's size. Size groups are common in the fashion industry to define size segments and suggested audiences for wearable products. Multiple values can be combined, for example "men's big and tall", "petite maternity" or "regular" | |
| sizeSystem | The size system used to identify a product's size. Typically either a standard (for example, "GS1" or "ISO-EN13402"), country code (for example "US" or "JP"), or a measuring system (for example "Metric" or "Imperial"). | |
| skills | A statement of knowledge, skill, ability, task or any other assertion expressing a competency that is desired or required to fulfill this role or to work in this occupation. | |
| sku | The Stock Keeping Unit (SKU), i.e. a merchant-specific identifier for a product or service, or the product to which the offer refers. | |
| slogan | A slogan or motto associated with the item. | |
| smokingAllowed | Indicates whether it is allowed to smoke in the place, e.g. in the restaurant, hotel or hotel room. | |
| sodiumContent | The number of milligrams of sodium. | |
| softwareAddOn | Additional content for a software application. | |
| softwareHelp | Software application help. | |
| softwareRequirements | Component dependency requirements for application. This includes runtime environments and shared libraries that are not included in the application distribution package, but required to run the application (Examples: DirectX, Java or .NET runtime). | |
| softwareVersion | Version of the software instance. | |
| sourceOrganization | The Organization on whose behalf the creator was working. | |
| sourcedFrom | The neurological pathway that originates the neurons. | |
| spatial | The "spatial" property can be used in cases when more specific properties (e.g. locationCreated, spatialCoverage, contentLocation) are not known to be appropriate. | |
| spatialCoverage | The spatialCoverage of a CreativeWork indicates the place(s) which are the focus of the content. It is a subproperty of contentLocation intended primarily for more technical and detailed materials. For example with a Dataset, it indicates areas that the dataset describes: a dataset of New York weather would have spatialCoverage which was the place: the state of New York. | |
| speakable | Indicates sections of a Web page that are particularly 'speakable' in the sense of being highlighted as being especially appropriate for text-to-speech conversion. Other sections of a page may also be usefully spoken in particular circumstances; the 'speakable' property serves to indicate the parts most likely to be generally useful for speech. The speakable property can be repeated an arbitrary number of times, with three kinds of possible 'content-locator' values: 1.) id-value URL references - uses id-value of an element in the page being annotated. The simplest use of speakable has (potentially relative) URL values, referencing identified sections of the document concerned. 2.) CSS Selectors - addresses content in the annotated page, eg. via class attribute. Use the cssSelector property. 3.) XPaths - addresses content via XPaths (assuming an XML view of the content). Use the xpath property. For more sophisticated markup of speakable sections beyond simple ID references, either CSS selectors or XPath expressions to pick out document section(s) as speakable. For this we define a supporting type, SpeakableSpecification which is defined to be a possible value of the speakable property. |
|
| specialCommitments | Any special commitments associated with this job posting. Valid entries include VeteranCommit, MilitarySpouseCommit, etc. | |
| specialOpeningHoursSpecification | The special opening hours of a certain place. Use this to explicitly override general opening hours brought in scope by openingHoursSpecification or openingHours. |
|
| specialty | One of the domain specialities to which this web page's content applies. | |
| speechToTextMarkup | Form of markup used. eg. SSML or IPA. | |
| speed | The speed range of the vehicle. If the vehicle is powered by an engine, the upper limit of the speed range (indicated by maxValue should be the maximum speed achievable under regular conditions. Typical unit code(s): KMH for km/h, HM for mile per hour (0.447 04 m/s), KNT for knot *Note 1: Use minValue and maxValue to indicate the range. Typically, the minimal value is zero. * Note 2: There are many different ways of measuring the speed range. You can link to information about how the given value has been determined using the valueReference property. |
|
| spokenByCharacter | The (e.g. fictional) character, Person or Organization to whom the quotation is attributed within the containing CreativeWork. | |
| sponsor | A person or organization that supports a thing through a pledge, promise, or financial contribution. e.g. a sponsor of a Medical Study or a corporate sponsor of an event. | |
| sport | A type of sport (e.g. Baseball). | |
| sportsActivityLocation | A sub property of location. The sports activity location where this action occurred. | |
| sportsEvent | A sub property of location. The sports event where this action occurred. | |
| sportsTeam | A sub property of participant. The sports team that participated on this action. | |
| spouse | The person's spouse. | |
| stage | The stage of the condition, if applicable. | |
| stageAsNumber | The stage represented as a number, e.g. 3. | |
| starRating | An official rating for a lodging business or food establishment, e.g. from national associations or standards bodies. Use the author property to indicate the rating organization, e.g. as an Organization with name such as (e.g. HOTREC, DEHOGA, WHR, or Hotelstars). | |
| startDate | The start date and time of the item (in ISO 8601 date format). | |
| startOffset | The start time of the clip expressed as the number of seconds from the beginning of the work. | |
| startTime | The startTime of something. For a reserved event or service (e.g. FoodEstablishmentReservation), the time that it is expected to start. For actions that span a period of time, when the action was performed. e.g. John wrote a book from January to December. For media, including audio and video, it's the time offset of the start of a clip within a larger file. Note that Event uses startDate/endDate instead of startTime/endTime, even when describing dates with times. This situation may be clarified in future revisions. |
|
| status | The status of the study (enumerated). | |
| steeringPosition | The position of the steering wheel or similar device (mostly for cars). | |
| step | A single step item (as HowToStep, text, document, video, etc.) or a HowToSection. | |
| stepValue | The stepValue attribute indicates the granularity that is expected (and required) of the value in a PropertyValueSpecification. | |
| steps | A single step item (as HowToStep, text, document, video, etc.) or a HowToSection (originally misnamed 'steps'; 'step' is preferred). | |
| storageRequirements | Storage requirements (free space required). | |
| streetAddress | The street address. For example, 1600 Amphitheatre Pkwy. | |
| strengthUnit | The units of an active ingredient's strength, e.g. mg. | |
| strengthValue | The value of an active ingredient's strength, e.g. 325. | |
| structuralClass | The name given to how bone physically connects to each other. | |
| study | A medical study or trial related to this entity. | |
| studyDesign | Specifics about the observational study design (enumerated). | |
| studyLocation | The location in which the study is taking/took place. | |
| studySubject | A subject of the study, i.e. one of the medical conditions, therapies, devices, drugs, etc. investigated by the study. | |
| subEvent | An Event that is part of this event. For example, a conference event includes many presentations, each of which is a subEvent of the conference. | |
| subEvents | Events that are a part of this event. For example, a conference event includes many presentations, each subEvents of the conference. | |
| subOrganization | A relationship between two organizations where the first includes the second, e.g., as a subsidiary. See also: the more specific 'department' property. | |
| subReservation | The individual reservations included in the package. Typically a repeated property. | |
| subStageSuffix | The substage, e.g. 'a' for Stage IIIa. | |
| subStructure | Component (sub-)structure(s) that comprise this anatomical structure. | |
| subTest | A component test of the panel. | |
| subTrip | Identifies a Trip that is a subTrip of this Trip. For example Day 1, Day 2, etc. of a multi-day trip. | |
| subjectOf | A CreativeWork or Event about this Thing. | |
| subtitleLanguage | Languages in which subtitles/captions are available, in IETF BCP 47 standard format. | |
| successorOf | A pointer from a newer variant of a product to its previous, often discontinued predecessor. | |
| sugarContent | The number of grams of sugar. | |
| suggestedAge | The age or age range for the intended audience or person, for example 3-12 months for infants, 1-5 years for toddlers. | |
| suggestedAnswer | An answer (possibly one of several, possibly incorrect) to a Question, e.g. on a Question/Answer site. | |
| suggestedGender | The suggested gender of the intended person or audience, for example "male", "female", or "unisex". | |
| suggestedMaxAge | Maximum recommended age in years for the audience or user. | |
| suggestedMeasurement | A suggested range of body measurements for the intended audience or person, for example inseam between 32 and 34 inches or height between 170 and 190 cm. Typically found on a size chart for wearable products. | |
| suggestedMinAge | Minimum recommended age in years for the audience or user. | |
| suitableForDiet | Indicates a dietary restriction or guideline for which this recipe or menu item is suitable, e.g. diabetic, halal etc. | |
| superEvent | An event that this event is a part of. For example, a collection of individual music performances might each have a music festival as their superEvent. | |
| supersededBy | Relates a term (i.e. a property, class or enumeration) to one that supersedes it. | |
| supply | A sub-property of instrument. A supply consumed when performing instructions or a direction. | |
| supplyTo | The area to which the artery supplies blood. | |
| supportingData | Supporting data for a SoftwareApplication. | |
| surface | A material used as a surface in some artwork, e.g. Canvas, Paper, Wood, Board, etc. | |
| target | Indicates a target EntryPoint for an Action. | |
| targetCollection | A sub property of object. The collection target of the action. | |
| targetDescription | The description of a node in an established educational framework. | |
| targetName | The name of a node in an established educational framework. | |
| targetPlatform | Type of app development: phone, Metro style, desktop, XBox, etc. | |
| targetPopulation | Characteristics of the population for which this is intended, or which typically uses it, e.g. 'adults'. | |
| targetProduct | Target Operating System / Product to which the code applies. If applies to several versions, just the product name can be used. | |
| targetUrl | The URL of a node in an established educational framework. | |
| taxID | The Tax / Fiscal ID of the organization or person, e.g. the TIN in the US or the CIF/NIF in Spain. | |
| teaches | The item being described is intended to help a person learn the competency or learning outcome defined by the referenced term. | |
| telephone | The telephone number. | |
| temporal | The "temporal" property can be used in cases where more specific properties (e.g. temporalCoverage, dateCreated, dateModified, datePublished) are not known to be appropriate. | |
| temporalCoverage | The temporalCoverage of a CreativeWork indicates the period that the content applies to, i.e. that it describes, either as a DateTime or as a textual string indicating a time period in ISO 8601 time interval format. In
the case of a Dataset it will typically indicate the relevant time period in a precise notation (e.g. for a 2011 census dataset, the year 2011 would be written "2011/2012"). Other forms of content e.g. ScholarlyArticle, Book, TVSeries or TVEpisode may indicate their temporalCoverage in broader terms - textually or via well-known URL.
Written works such as books may sometimes have precise temporal coverage too, e.g. a work set in 1939 - 1945 can be indicated in ISO 8601 interval format format via "1939/1945". Open-ended date ranges can be written with ".." in place of the end date. For example, "2015-11/.." indicates a range beginning in November 2015 and with no specified final date. This is tentative and might be updated in future when ISO 8601 is officially updated. |
|
| termCode | A code that identifies this DefinedTerm within a DefinedTermSet | |
| termDuration | The amount of time in a term as defined by the institution. A term is a length of time where students take one or more classes. Semesters and quarters are common units for term. | |
| termsOfService | Human-readable terms of service documentation. | |
| termsPerYear | The number of times terms of study are offered per year. Semesters and quarters are common units for term. For example, if the student can only take 2 semesters for the program in one year, then termsPerYear should be 2. | |
| text | The textual content of this CreativeWork. | |
| textValue | Text value being annotated. | |
| thumbnail | Thumbnail image for an image or video. | |
| thumbnailUrl | A thumbnail image relevant to the Thing. | |
| tickerSymbol | The exchange traded instrument associated with a Corporation object. The tickerSymbol is expressed as an exchange and an instrument name separated by a space character. For the exchange component of the tickerSymbol attribute, we recommend using the controlled vocabulary of Market Identifier Codes (MIC) specified in ISO15022. | |
| ticketNumber | The unique identifier for the ticket. | |
| ticketToken | Reference to an asset (e.g., Barcode, QR code image or PDF) usable for entrance. | |
| ticketedSeat | The seat associated with the ticket. | |
| timeOfDay | The time of day the program normally runs. For example, "evenings". | |
| timeRequired | Approximate or typical time it takes to work with or through this learning resource for the typical intended target audience, e.g. 'PT30M', 'PT1H25M'. | |
| timeToComplete | The expected length of time to complete the program if attending full-time. | |
| tissueSample | The type of tissue sample required for the test. | |
| title | The title of the job. | |
| titleEIDR | An EIDR (Entertainment Identifier Registry) identifier representing at the most general/abstract level, a work of film or television. For example, the motion picture known as "Ghostbusters" has a titleEIDR of "10.5240/7EC7-228A-510A-053E-CBB8-J". This title (or work) may have several variants, which EIDR calls "edits". See editEIDR. Since schema.org types like Movie and TVEpisode can be used for both works and their multiple expressions, it is possible to use titleEIDR alone (for a general description), or alongside editEIDR for a more edit-specific description. |
|
| toLocation | A sub property of location. The final location of the object or the agent after the action. | |
| toRecipient | A sub property of recipient. The recipient who was directly sent the message. | |
| tocContinuation | A HyperTocEntry can have a tocContinuation indicated, which is another HyperTocEntry that would be the default next item to play or render. | |
| tocEntry | Indicates a HyperTocEntry in a HyperToc. | |
| tongueWeight | The permitted vertical load (TWR) of a trailer attached to the vehicle. Also referred to as Tongue Load Rating (TLR) or Vertical Load Rating (VLR) Typical unit code(s): KGM for kilogram, LBR for pound
|
|
| tool | A sub property of instrument. An object used (but not consumed) when performing instructions or a direction. | |
| torque | The torque (turning force) of the vehicle's engine. Typical unit code(s): NU for newton metre (N m), F17 for pound-force per foot, or F48 for pound-force per inch
|
|
| totalJobOpenings | The number of positions open for this job posting. Use a positive integer. Do not use if the number of positions is unclear or not known. | |
| totalPaymentDue | The total amount due. | |
| totalPrice | The total price for the reservation or ticket, including applicable taxes, shipping, etc. Usage guidelines:
|
|
| totalTime | The total time required to perform instructions or a direction (including time to prepare the supplies), in ISO 8601 duration format. | |
| tourBookingPage | A page providing information on how to book a tour of some Place, such as an Accommodation or ApartmentComplex in a real estate setting, as well as other kinds of tours as appropriate. | |
| touristType | Attraction suitable for type(s) of tourist. eg. Children, visitors from a particular country, etc. | |
| track | A music recording (track)—usually a single song. If an ItemList is given, the list should contain items of type MusicRecording. | |
| trackingNumber | Shipper tracking number. | |
| trackingUrl | Tracking url for the parcel delivery. | |
| tracks | A music recording (track)—usually a single song. | |
| trailer | The trailer of a movie or tv/radio series, season, episode, etc. | |
| trailerWeight | The permitted weight of a trailer attached to the vehicle. Typical unit code(s): KGM for kilogram, LBR for pound * Note 1: You can indicate additional information in the name of the QuantitativeValue node. * Note 2: You may also link to a QualitativeValue node that provides additional information using valueReference. * Note 3: Note that you can use minValue and maxValue to indicate ranges. |
|
| trainName | The name of the train (e.g. The Orient Express). | |
| trainNumber | The unique identifier for the train. | |
| trainingSalary | The estimated salary earned while in the program. | |
| transFatContent | The number of grams of trans fat. | |
| transcript | If this MediaObject is an AudioObject or VideoObject, the transcript of that object. | |
| transitTime | The typical delay the order has been sent for delivery and the goods reach the final customer. Typical properties: minValue, maxValue, unitCode (d for DAY). | |
| transitTimeLabel | Label to match an OfferShippingDetails with a DeliveryTimeSettings (within the context of a shippingSettingsLink cross-reference). | |
| translationOfWork | The work that this work has been translated from. e.g. 物种起源 is a translationOf “On the Origin of Species” | |
| translator | Organization or person who adapts a creative work to different languages, regional differences and technical requirements of a target market, or that translates during some event. | |
| transmissionMethod | How the disease spreads, either as a route or vector, for example 'direct contact', 'Aedes aegypti', etc. | |
| travelBans | Information about travel bans, e.g. in the context of a pandemic. | |
| trialDesign | Specifics about the trial design (enumerated). | |
| tributary | The anatomical or organ system that the vein flows into; a larger structure that the vein connects to. | |
| typeOfBed | The type of bed to which the BedDetail refers, i.e. the type of bed available in the quantity indicated by quantity. | |
| typeOfGood | The product that this structured value is referring to. | |
| typicalAgeRange | The typical expected age range, e.g. '7-9', '11-'. | |
| typicalCreditsPerTerm | The number of credits or units a full-time student would be expected to take in 1 term however 'term' is defined by the institution. | |
| typicalTest | A medical test typically performed given this condition. | |
| underName | The person or organization the reservation or ticket is for. | |
| unitCode | The unit of measurement given using the UN/CEFACT Common Code (3 characters) or a URL. Other codes than the UN/CEFACT Common Code may be used with a prefix followed by a colon. | |
| unitText | A string or text indicating the unit of measurement. Useful if you cannot provide a standard unit code for unitCode. | |
| unnamedSourcesPolicy | For an Organization (typically a NewsMediaOrganization), a statement about policy on use of unnamed sources and the decision process required. | |
| unsaturatedFatContent | The number of grams of unsaturated fat. | |
| uploadDate | Date when this media object was uploaded to this site. | |
| upvoteCount | The number of upvotes this question, answer or comment has received from the community. | |
| url | URL of the item. | |
| urlTemplate | An url template (RFC6570) that will be used to construct the target of the execution of the action. | |
| usageInfo | The schema.org usageInfo property indicates further information about a CreativeWork. This property is applicable both to works that are freely available and to those that require payment or other transactions. It can reference additional information e.g. community expectations on preferred linking and citation conventions, as well as purchasing details. For something that can be commercially licensed, usageInfo can provide detailed, resource-specific information about licensing options. This property can be used alongside the license property which indicates license(s) applicable to some piece of content. The usageInfo property can provide information about other licensing options, e.g. acquiring commercial usage rights for an image that is also available under non-commercial creative commons licenses. |
|
| usedToDiagnose | A condition the test is used to diagnose. | |
| userInteractionCount | The number of interactions for the CreativeWork using the WebSite or SoftwareApplication. | |
| usesDevice | Device used to perform the test. | |
| usesHealthPlanIdStandard | The standard for interpreting thePlan ID. The preferred is "HIOS". See the Centers for Medicare & Medicaid Services for more details. | |
| utterances | Text of an utterances (spoken words, lyrics etc.) that occurs at a certain section of a media object, represented as a HyperTocEntry. | |
| validFor | The duration of validity of a permit or similar thing. | |
| validFrom | The date when the item becomes valid. | |
| validIn | The geographic area where a permit or similar thing is valid. | |
| validThrough | The date after when the item is not valid. For example the end of an offer, salary period, or a period of opening hours. | |
| validUntil | The date when the item is no longer valid. | |
| value | The value of the quantitative value or property value node.
|
|
| valueAddedTaxIncluded | Specifies whether the applicable value-added tax (VAT) is included in the price specification or not. | |
| valueMaxLength | Specifies the allowed range for number of characters in a literal value. | |
| valueMinLength | Specifies the minimum allowed range for number of characters in a literal value. | |
| valueName | Indicates the name of the PropertyValueSpecification to be used in URL templates and form encoding in a manner analogous to HTML's input@name. | |
| valuePattern | Specifies a regular expression for testing literal values according to the HTML spec. | |
| valueReference | A secondary value that provides additional information on the original value, e.g. a reference temperature or a type of measurement. | |
| valueRequired | Whether the property must be filled in to complete the action. Default is false. | |
| variableMeasured | The variableMeasured property can indicate (repeated as necessary) the variables that are measured in some dataset, either described as text or as pairs of identifier and description using PropertyValue. | |
| variantCover | A description of the variant cover for the issue, if the issue is a variant printing. For example, "Bryan Hitch Variant Cover" or "2nd Printing Variant". | |
| variesBy | Indicates the property or properties by which the variants in a ProductGroup vary, e.g. their size, color etc. Schema.org properties can be referenced by their short name e.g. "color"; terms defined elsewhere can be referenced with their URIs. | |
| vatID | The Value-added Tax ID of the organization or person. | |
| vehicleConfiguration | A short text indicating the configuration of the vehicle, e.g. '5dr hatchback ST 2.5 MT 225 hp' or 'limited edition'. | |
| vehicleEngine | Information about the engine or engines of the vehicle. | |
| vehicleIdentificationNumber | The Vehicle Identification Number (VIN) is a unique serial number used by the automotive industry to identify individual motor vehicles. | |
| vehicleInteriorColor | The color or color combination of the interior of the vehicle. | |
| vehicleInteriorType | The type or material of the interior of the vehicle (e.g. synthetic fabric, leather, wood, etc.). While most interior types are characterized by the material used, an interior type can also be based on vehicle usage or target audience. | |
| vehicleModelDate | The release date of a vehicle model (often used to differentiate versions of the same make and model). | |
| vehicleSeatingCapacity | The number of passengers that can be seated in the vehicle, both in terms of the physical space available, and in terms of limitations set by law. Typical unit code(s): C62 for persons. |
|
| vehicleSpecialUsage | Indicates whether the vehicle has been used for special purposes, like commercial rental, driving school, or as a taxi. The legislation in many countries requires this information to be revealed when offering a car for sale. | |
| vehicleTransmission | The type of component used for transmitting the power from a rotating power source to the wheels or other relevant component(s) ("gearbox" for cars). | |
| vendor | 'vendor' is an earlier term for 'seller'. | |
| verificationFactCheckingPolicy | Disclosure about verification and fact-checking processes for a NewsMediaOrganization or other fact-checking Organization. | |
| version | The version of the CreativeWork embodied by a specified resource. | |
| video | An embedded video object. | |
| videoFormat | The type of screening or video broadcast used (e.g. IMAX, 3D, SD, HD, etc.). | |
| videoFrameSize | The frame size of the video. | |
| videoQuality | The quality of the video. | |
| volumeNumber | Identifies the volume of publication or multi-part work; for example, "iii" or "2". | |
| warning | Any FDA or other warnings about the drug (text or URL). | |
| warranty | The warranty promise(s) included in the offer. | |
| warrantyPromise | The warranty promise(s) included in the offer. | |
| warrantyScope | The scope of the warranty promise. | |
| webCheckinTime | The time when a passenger can check into the flight online. | |
| webFeed | The URL for a feed, e.g. associated with a podcast series, blog, or series of date-stamped updates. This is usually RSS or Atom. | |
| weight | The weight of the product or person. | |
| weightTotal | The permitted total weight of the loaded vehicle, including passengers and cargo and the weight of the empty vehicle. Typical unit code(s): KGM for kilogram, LBR for pound
|
|
| wheelbase | The distance between the centers of the front and rear wheels. Typical unit code(s): CMT for centimeters, MTR for meters, INH for inches, FOT for foot/feet |
|
| width | The width of the item. | |
| winner | A sub property of participant. The winner of the action. | |
| wordCount | The number of words in the text of the Article. | |
| workExample | Example/instance/realization/derivation of the concept of this creative work. eg. The paperback edition, first edition, or eBook. | |
| workFeatured | A work featured in some event, e.g. exhibited in an ExhibitionEvent. Specific subproperties are available for workPerformed (e.g. a play), or a workPresented (a Movie at a ScreeningEvent). | |
| workHours | The typical working hours for this job (e.g. 1st shift, night shift, 8am-5pm). | |
| workLocation | A contact location for a person's place of work. | |
| workPerformed | A work performed in some event, for example a play performed in a TheaterEvent. | |
| workPresented | The movie presented during this event. | |
| workTranslation | A work that is a translation of the content of this work. e.g. 西遊記 has an English workTranslation “Journey to the West”,a German workTranslation “Monkeys Pilgerfahrt” and a Vietnamese translation Tây du ký bình khảo. | |
| workload | Quantitative measure of the physiologic output of the exercise; also referred to as energy expenditure. | |
| worksFor | Organizations that the person works for. | |
| worstRating | The lowest value allowed in this rating system. If worstRating is omitted, 1 is assumed. | |
| xpath | An XPath, e.g. of a SpeakableSpecification or WebPageElement. In the latter case, multiple matches within a page can constitute a single conceptual "Web page element". | |
| yearBuilt | The year an Accommodation was constructed. This corresponds to the YearBuilt field in RESO. | |
| yearlyRevenue | The size of the business in annual revenue. | |
| yearsInOperation | The age of the business. | |
| yield | The quantity that results by performing instructions. For example, a paper airplane, 10 personalized candles. |
Types
| Type | Description | Meta information |
|---|---|---|
| 3DModel | A 3D model represents some kind of 3D content, which may have encodings in one or more MediaObjects. Many 3D formats are available (e.g. see Wikipedia); specific encoding formats can be represented using the encodingFormat property applied to the relevant MediaObject. For the case of a single file published after Zip compression, the convention of appending '+zip' to the encodingFormat can be used. Geospatial, AR/VR, artistic/animation, gaming, engineering and scientific content can all be represented using 3DModel. | |
| AMRadioChannel | A radio channel that uses AM. | |
| APIReference | Reference documentation for application programming interfaces (APIs). | |
| Abdomen | Abdomen clinical examination. | |
| AboutPage | Web page type: About page. | |
| AcceptAction | The act of committing to/adopting an object. Related actions:
|
|
| Accommodation | An accommodation is a place that can accommodate human beings, e.g. a hotel room, a camping pitch, or a meeting room. Many accommodations are for overnight stays, but this is not a mandatory requirement.
For more specific types of accommodations not defined in schema.org, one can use additionalType with external vocabularies.
See also the dedicated document on the use of schema.org for marking up hotels and other forms of accommodations. |
|
| AccountingService | Accountancy business. As a LocalBusiness it can be described as a provider of one or more Service(s). |
|
| AchieveAction | The act of accomplishing something via previous efforts. It is an instantaneous action rather than an ongoing process. | |
| Action | An action performed by a direct agent and indirect participants upon a direct object. Optionally happens at a location with the help of an inanimate instrument. The execution of the action may produce a result. Specific action sub-type documentation specifies the exact expectation of each argument/role. See also blog post and Actions overview document. |
|
| ActionAccessSpecification | A set of requirements that a must be fulfilled in order to perform an Action. | |
| ActionStatusType | The status of an Action. | |
| ActivateAction | The act of starting or activating a device or application (e.g. starting a timer or turning on a flashlight). | |
| ActivationFee | Represents the activation fee part of the total price for an offered product, for example a cellphone contract. | |
| ActiveActionStatus | An in-progress action (e.g, while watching the movie, or driving to a location). | |
| ActiveNotRecruiting | Active, but not recruiting new participants. | |
| AddAction | The act of editing by adding an object to a collection. | |
| AdministrativeArea | A geographical region, typically under the jurisdiction of a particular government. | |
| AdultEntertainment | An adult entertainment establishment. | |
| AdvertiserContentArticle | An Article that an external entity has paid to place or to produce to its specifications. Includes advertorials, sponsored content, native advertising and other paid content. | |
| AerobicActivity | Physical activity of relatively low intensity that depends primarily on the aerobic energy-generating process; during activity, the aerobic metabolism uses oxygen to adequately meet energy demands during exercise. | |
| AggregateOffer | When a single product is associated with multiple offers (for example, the same pair of shoes is offered by different merchants), then AggregateOffer can be used. Note: AggregateOffers are normally expected to associate multiple offers that all share the same defined businessFunction value, or default to http://purl.org/goodrelations/v1#Sell if businessFunction is not explicitly defined. |
|
| AggregateRating | The average rating based on multiple ratings or reviews. | |
| AgreeAction | The act of expressing a consistency of opinion with the object. An agent agrees to/about an object (a proposition, topic or theme) with participants. | |
| Airline | An organization that provides flights for passengers. | |
| Airport | An airport. | |
| AlbumRelease | AlbumRelease. | |
| AlignmentObject | An intangible item that describes an alignment between a learning resource and a node in an educational framework. Should not be used where the nature of the alignment can be described using a simple property, for example to express that a resource teaches or assesses a competency. |
|
| AllWheelDriveConfiguration | All-wheel Drive is a transmission layout where the engine drives all four wheels. | |
| AllergiesHealthAspect | Content about the allergy-related aspects of a health topic. | |
| AllocateAction | The act of organizing tasks/objects/events by associating resources to it. | |
| AmpStory | A creative work with a visual storytelling format intended to be viewed online, particularly on mobile devices. | |
| AmusementPark | An amusement park. | |
| AnaerobicActivity | Physical activity that is of high-intensity which utilizes the anaerobic metabolism of the body. | |
| AnalysisNewsArticle | An AnalysisNewsArticle is a NewsArticle that, while based on factual reporting, incorporates the expertise of the author/producer, offering interpretations and conclusions. | |
| AnatomicalStructure | Any part of the human body, typically a component of an anatomical system. Organs, tissues, and cells are all anatomical structures. | |
| AnatomicalSystem | An anatomical system is a group of anatomical structures that work together to perform a certain task. Anatomical systems, such as organ systems, are one organizing principle of anatomy, and can includes circulatory, digestive, endocrine, integumentary, immune, lymphatic, muscular, nervous, reproductive, respiratory, skeletal, urinary, vestibular, and other systems. | |
| Anesthesia | A specific branch of medical science that pertains to study of anesthetics and their application. | |
| AnimalShelter | Animal shelter. | |
| Answer | An answer offered to a question; perhaps correct, perhaps opinionated or wrong. | |
| Apartment | An apartment (in American English) or flat (in British English) is a self-contained housing unit (a type of residential real estate) that occupies only part of a building (Source: Wikipedia, the free encyclopedia, see http://en.wikipedia.org/wiki/Apartment). | |
| ApartmentComplex | Residence type: Apartment complex. | |
| Appearance | Appearance assessment with clinical examination. | |
| AppendAction | The act of inserting at the end if an ordered collection. | |
| ApplyAction | The act of registering to an organization/service without the guarantee to receive it. Related actions:
|
|
| ApprovedIndication | An indication for a medical therapy that has been formally specified or approved by a regulatory body that regulates use of the therapy; for example, the US FDA approves indications for most drugs in the US. | |
| Aquarium | Aquarium. | |
| ArchiveComponent | An intangible type to be applied to any archive content, carrying with it a set of properties required to describe archival items and collections. | |
| ArchiveOrganization | An organization with archival holdings. An organization which keeps and preserves archival material and typically makes it accessible to the public. | |
| ArriveAction | The act of arriving at a place. An agent arrives at a destination from a fromLocation, optionally with participants. | |
| ArtGallery | An art gallery. | |
| Artery | A type of blood vessel that specifically carries blood away from the heart. | |
| Article | An article, such as a news article or piece of investigative report. Newspapers and magazines have articles of many different types and this is intended to cover them all. See also blog post. |
|
| AskAction | The act of posing a question / favor to someone. Related actions:
|
|
| AskPublicNewsArticle | A NewsArticle expressing an open call by a NewsMediaOrganization asking the public for input, insights, clarifications, anecdotes, documentation, etc., on an issue, for reporting purposes. | |
| AssessAction | The act of forming one's opinion, reaction or sentiment. | |
| AssignAction | The act of allocating an action/event/task to some destination (someone or something). | |
| Atlas | A collection or bound volume of maps, charts, plates or tables, physical or in media form illustrating any subject. | |
| Attorney | Professional service: Attorney. This type is deprecated - LegalService is more inclusive and less ambiguous. |
|
| Audience | Intended audience for an item, i.e. the group for whom the item was created. | |
| AudioObject | An audio file. | |
| Audiobook | An audiobook. | |
| AudiobookFormat | Book format: Audiobook. This is an enumerated value for use with the bookFormat property. There is also a type 'Audiobook' in the bib extension which includes Audiobook specific properties. | |
| AuthoritativeLegalValue | Indicates that the publisher gives some special status to the publication of the document. ("The Queens Printer" version of a UK Act of Parliament, or the PDF version of a Directive published by the EU Office of Publications). Something "Authoritative" is considered to be also OfficialLegalValue". | |
| AuthorizeAction | The act of granting permission to an object. | |
| AutoBodyShop | Auto body shop. | |
| AutoDealer | An car dealership. | |
| AutoPartsStore | An auto parts store. | |
| AutoRental | A car rental business. | |
| AutoRepair | Car repair business. | |
| AutoWash | A car wash business. | |
| AutomatedTeller | ATM/cash machine. | |
| AutomotiveBusiness | Car repair, sales, or parts. | |
| Ayurvedic | A system of medicine that originated in India over thousands of years and that focuses on integrating and balancing the body, mind, and spirit. | |
| BackOrder | Indicates that the item is available on back order. | |
| BackgroundNewsArticle | A NewsArticle providing historical context, definition and detail on a specific topic (aka "explainer" or "backgrounder"). For example, an in-depth article or frequently-asked-questions (FAQ) document on topics such as Climate Change or the European Union. Other kinds of background material from a non-news setting are often described using Book or Article, in particular ScholarlyArticle. See also NewsArticle for related vocabulary from a learning/education perspective. | |
| Bacteria | Pathogenic bacteria that cause bacterial infection. | |
| Bakery | A bakery. | |
| Balance | Physical activity that is engaged to help maintain posture and balance. | |
| BankAccount | A product or service offered by a bank whereby one may deposit, withdraw or transfer money and in some cases be paid interest. | |
| BankOrCreditUnion | Bank or credit union. | |
| BarOrPub | A bar or pub. | |
| Barcode | An image of a visual machine-readable code such as a barcode or QR code. | |
| BasicIncome | BasicIncome: this is a benefit for basic income. | |
| Beach | Beach. | |
| BeautySalon | Beauty salon. | |
| BedAndBreakfast | Bed and breakfast.
See also the dedicated document on the use of schema.org for marking up hotels and other forms of accommodations. |
|
| BedDetails | An entity holding detailed information about the available bed types, e.g. the quantity of twin beds for a hotel room. For the single case of just one bed of a certain type, you can use bed directly with a text. See also BedType (under development). | |
| BedType | A type of bed. This is used for indicating the bed or beds available in an accommodation. | |
| BefriendAction | The act of forming a personal connection with someone (object) mutually/bidirectionally/symmetrically. Related actions:
|
|
| BenefitsHealthAspect | Content about the benefits and advantages of usage or utilization of topic. | |
| BikeStore | A bike store. | |
| Blog | A blog. | |
| BlogPosting | A blog post. | |
| BloodTest | A medical test performed on a sample of a patient's blood. | |
| BoardingPolicyType | A type of boarding policy used by an airline. | |
| BoatReservation | A reservation for boat travel. Note: This type is for information about actual reservations, e.g. in confirmation emails or HTML pages with individual confirmations of reservations. For offers of tickets, use Offer. |
|
| BoatTerminal | A terminal for boats, ships, and other water vessels. | |
| BoatTrip | A trip on a commercial ferry line. | |
| BodyMeasurementArm | Arm length (measured between arms/shoulder line intersection and the prominent wrist bone). Used, for example, to fit shirts. | |
| BodyMeasurementBust | Maximum girth of bust. Used, for example, to fit women's suits. | |
| BodyMeasurementChest | Maximum girth of chest. Used, for example, to fit men's suits. | |
| BodyMeasurementFoot | Foot length (measured between end of the most prominent toe and the most prominent part of the heel). Used, for example, to measure socks. | |
| BodyMeasurementHand | Maximum hand girth (measured over the knuckles of the open right hand excluding thumb, fingers together). Used, for example, to fit gloves. | |
| BodyMeasurementHead | Maximum girth of head above the ears. Used, for example, to fit hats. | |
| BodyMeasurementHeight | Body height (measured between crown of head and soles of feet). Used, for example, to fit jackets. | |
| BodyMeasurementHips | Girth of hips (measured around the buttocks). Used, for example, to fit skirts. | |
| BodyMeasurementInsideLeg | Inside leg (measured between crotch and soles of feet). Used, for example, to fit pants. | |
| BodyMeasurementNeck | Girth of neck. Used, for example, to fit shirts. | |
| BodyMeasurementTypeEnumeration | Enumerates types (or dimensions) of a person's body measurements, for example for fitting of clothes. | |
| BodyMeasurementUnderbust | Girth of body just below the bust. Used, for example, to fit women's swimwear. | |
| BodyMeasurementWaist | Girth of natural waistline (between hip bones and lower ribs). Used, for example, to fit pants. | |
| BodyMeasurementWeight | Body weight. Used, for example, to measure pantyhose. | |
| BodyOfWater | A body of water, such as a sea, ocean, or lake. | |
| Bone | Rigid connective tissue that comprises up the skeletal structure of the human body. | |
| Book | A book. | |
| BookFormatType | The publication format of the book. | |
| BookSeries | A series of books. Included books can be indicated with the hasPart property. | |
| BookStore | A bookstore. | |
| BookmarkAction | An agent bookmarks/flags/labels/tags/marks an object. | |
| Boolean | Boolean: True or False. | |
| BorrowAction | The act of obtaining an object under an agreement to return it at a later date. Reciprocal of LendAction. Related actions:
|
|
| BowlingAlley | A bowling alley. | |
| BrainStructure | Any anatomical structure which pertains to the soft nervous tissue functioning as the coordinating center of sensation and intellectual and nervous activity. | |
| Brand | A brand is a name used by an organization or business person for labeling a product, product group, or similar. | |
| BreadcrumbList | A BreadcrumbList is an ItemList consisting of a chain of linked Web pages, typically described using at least their URL and their name, and typically ending with the current page. The position property is used to reconstruct the order of the items in a BreadcrumbList The convention is that a breadcrumb list has an itemListOrder of ItemListOrderAscending (lower values listed first), and that the first items in this list correspond to the "top" or beginning of the breadcrumb trail, e.g. with a site or section homepage. The specific values of 'position' are not assigned meaning for a BreadcrumbList, but they should be integers, e.g. beginning with '1' for the first item in the list. |
|
| Brewery | Brewery. | |
| Bridge | A bridge. | |
| BroadcastChannel | A unique instance of a BroadcastService on a CableOrSatelliteService lineup. | |
| BroadcastEvent | An over the air or online broadcast event. | |
| BroadcastFrequencySpecification | The frequency in MHz and the modulation used for a particular BroadcastService. | |
| BroadcastRelease | BroadcastRelease. | |
| BroadcastService | A delivery service through which content is provided via broadcast over the air or online. | |
| BrokerageAccount | An account that allows an investor to deposit funds and place investment orders with a licensed broker or brokerage firm. | |
| BuddhistTemple | A Buddhist temple. | |
| BusOrCoach | A bus (also omnibus or autobus) is a road vehicle designed to carry passengers. Coaches are luxury busses, usually in service for long distance travel. | |
| BusReservation | A reservation for bus travel. Note: This type is for information about actual reservations, e.g. in confirmation emails or HTML pages with individual confirmations of reservations. For offers of tickets, use Offer. |
|
| BusStation | A bus station. | |
| BusStop | A bus stop. | |
| BusTrip | A trip on a commercial bus line. | |
| BusinessAudience | A set of characteristics belonging to businesses, e.g. who compose an item's target audience. | |
| BusinessEntityType | A business entity type is a conceptual entity representing the legal form, the size, the main line of business, the position in the value chain, or any combination thereof, of an organization or business person. Commonly used values:
|
|
| BusinessEvent | Event type: Business event. | |
| BusinessFunction | The business function specifies the type of activity or access (i.e., the bundle of rights) offered by the organization or business person through the offer. Typical are sell, rental or lease, maintenance or repair, manufacture / produce, recycle / dispose, engineering / construction, or installation. Proprietary specifications of access rights are also instances of this class. Commonly used values:
|
|
| BusinessSupport | BusinessSupport: this is a benefit for supporting businesses. | |
| BuyAction | The act of giving money to a seller in exchange for goods or services rendered. An agent buys an object, product, or service from a seller for a price. Reciprocal of SellAction. | |
| CDCPMDRecord | A CDCPMDRecord is a data structure representing a record in a CDC tabular data format used for hospital data reporting. See documentation for details, and the linked CDC materials for authoritative definitions used as the source here. | |
| CDFormat | CDFormat. | |
| CT | X-ray computed tomography imaging. | |
| CableOrSatelliteService | A service which provides access to media programming like TV or radio. Access may be via cable or satellite. | |
| CafeOrCoffeeShop | A cafe or coffee shop. | |
| Campground | A camping site, campsite, or Campground is a place used for overnight stay in the outdoors, typically containing individual CampingPitch locations. In British English a campsite is an area, usually divided into a number of pitches, where people can camp overnight using tents or camper vans or caravans; this British English use of the word is synonymous with the American English expression campground. In American English the term campsite generally means an area where an individual, family, group, or military unit can pitch a tent or park a camper; a campground may contain many campsites (Source: Wikipedia see https://en.wikipedia.org/wiki/Campsite). See also the dedicated document on the use of schema.org for marking up hotels and other forms of accommodations. |
|
| CampingPitch | A CampingPitch is an individual place for overnight stay in the outdoors, typically being part of a larger camping site, or Campground. In British English a campsite, or campground, is an area, usually divided into a number of pitches, where people can camp overnight using tents or camper vans or caravans; this British English use of the word is synonymous with the American English expression campground. In American English the term campsite generally means an area where an individual, family, group, or military unit can pitch a tent or park a camper; a campground may contain many campsites. (Source: Wikipedia see https://en.wikipedia.org/wiki/Campsite). See also the dedicated document on the use of schema.org for marking up hotels and other forms of accommodations. |
|
| Canal | A canal, like the Panama Canal. | |
| CancelAction | The act of asserting that a future event/action is no longer going to happen. Related actions:
|
|
| Car | A car is a wheeled, self-powered motor vehicle used for transportation. | |
| CarUsageType | A value indicating a special usage of a car, e.g. commercial rental, driving school, or as a taxi. | |
| Cardiovascular | A specific branch of medical science that pertains to diagnosis and treatment of disorders of heart and vasculature. | |
| CardiovascularExam | Cardiovascular system assessment withclinical examination. | |
| CaseSeries | A case series (also known as a clinical series) is a medical research study that tracks patients with a known exposure given similar treatment or examines their medical records for exposure and outcome. A case series can be retrospective or prospective and usually involves a smaller number of patients than the more powerful case-control studies or randomized controlled trials. Case series may be consecutive or non-consecutive, depending on whether all cases presenting to the reporting authors over a period of time were included, or only a selection. | |
| Casino | A casino. | |
| CassetteFormat | CassetteFormat. | |
| CategoryCode | A Category Code. | |
| CategoryCodeSet | A set of Category Code values. | |
| CatholicChurch | A Catholic church. | |
| CausesHealthAspect | Information about the causes and main actions that gave rise to the topic. | |
| Cemetery | A graveyard. | |
| Chapter | One of the sections into which a book is divided. A chapter usually has a section number or a name. | |
| CharitableIncorporatedOrganization | CharitableIncorporatedOrganization: Non-profit type referring to a Charitable Incorporated Organization (UK). | |
| CheckAction | An agent inspects, determines, investigates, inquires, or examines an object's accuracy, quality, condition, or state. | |
| CheckInAction | The act of an agent communicating (service provider, social media, etc) their arrival by registering/confirming for a previously reserved service (e.g. flight check in) or at a place (e.g. hotel), possibly resulting in a result (boarding pass, etc). Related actions:
|
|
| CheckOutAction | The act of an agent communicating (service provider, social media, etc) their departure of a previously reserved service (e.g. flight check in) or place (e.g. hotel). Related actions:
|
|
| CheckoutPage | Web page type: Checkout page. | |
| ChildCare | A Childcare center. | |
| ChildrensEvent | Event type: Children's event. | |
| Chiropractic | A system of medicine focused on the relationship between the body's structure, mainly the spine, and its functioning. | |
| ChooseAction | The act of expressing a preference from a set of options or a large or unbounded set of choices/options. | |
| Church | A church. | |
| City | A city or town. | |
| CityHall | A city hall. | |
| CivicStructure | A public structure, such as a town hall or concert hall. | |
| Claim | A Claim in Schema.org represents a specific, factually-oriented claim that could be the itemReviewed in a ClaimReview. The content of a claim can be summarized with the text property. Variations on well known claims can have their common identity indicated via sameAs links, and summarized with a name. Ideally, a Claim description includes enough contextual information to minimize the risk of ambiguity or inclarity. In practice, many claims are better understood in the context in which they appear or the interpretations provided by claim reviews. Beyond ClaimReview, the Claim type can be associated with related creative works - for example a ScholarlyArticle or Question might be about some Claim. At this time, Schema.org does not define any types of relationship between claims. This is a natural area for future exploration. |
|
| ClaimReview | A fact-checking review of claims made (or reported) in some creative work (referenced via itemReviewed). | |
| Class | A class, also often called a 'Type'; equivalent to rdfs:Class. | |
| CleaningFee | Represents the cleaning fee part of the total price for an offered product, for example a vacation rental. | |
| Clinician | Medical clinicians, including practicing physicians and other medical professionals involved in clinical practice. | |
| Clip | A short TV or radio program or a segment/part of a program. | |
| ClothingStore | A clothing store. | |
| CoOp | Play mode: CoOp. Co-operative games, where you play on the same team with friends. | |
| Code | Computer programming source code. Example: Full (compile ready) solutions, code snippet samples, scripts, templates. | |
| CohortStudy | Also known as a panel study. A cohort study is a form of longitudinal study used in medicine and social science. It is one type of study design and should be compared with a cross-sectional study. A cohort is a group of people who share a common characteristic or experience within a defined period (e.g., are born, leave school, lose their job, are exposed to a drug or a vaccine, etc.). The comparison group may be the general population from which the cohort is drawn, or it may be another cohort of persons thought to have had little or no exposure to the substance under investigation, but otherwise similar. Alternatively, subgroups within the cohort may be compared with each other. | |
| Collection | A collection of items e.g. creative works or products. | |
| CollectionPage | Web page type: Collection page. | |
| CollegeOrUniversity | A college, university, or other third-level educational institution. | |
| ComedyClub | A comedy club. | |
| ComedyEvent | Event type: Comedy event. | |
| ComicCoverArt | The artwork on the cover of a comic. | |
| ComicIssue | Individual comic issues are serially published as part of a larger series. For the sake of consistency, even one-shot issues belong to a series comprised of a single issue. All comic issues can be uniquely identified by: the combination of the name and volume number of the series to which the issue belongs; the issue number; and the variant description of the issue (if any). | |
| ComicSeries | A sequential publication of comic stories under a unifying title, for example "The Amazing Spider-Man" or "Groo the Wanderer". | |
| ComicStory | The term "story" is any indivisible, re-printable unit of a comic, including the interior stories, covers, and backmatter. Most comics have at least two stories: a cover (ComicCoverArt) and an interior story. | |
| Comment | A comment on an item - for example, a comment on a blog post. The comment's content is expressed via the text property, and its topic via about, properties shared with all CreativeWorks. | |
| CommentAction | The act of generating a comment about a subject. | |
| CommentPermission | Permission to add comments to the document. | |
| CommunicateAction | The act of conveying information to another person via a communication medium (instrument) such as speech, email, or telephone conversation. | |
| CommunityHealth | A field of public health focusing on improving health characteristics of a defined population in relation with their geographical or environment areas. | |
| CompilationAlbum | CompilationAlbum. | |
| CompleteDataFeed | A CompleteDataFeed is a DataFeed whose standard representation includes content for every item currently in the feed. This is the equivalent of Atom's element as defined in Feed Paging and Archiving RFC 5005, For example (and as defined for Atom), when using data from a feed that represents a collection of items that varies over time (e.g. "Top Twenty Records") there is no need to have newer entries mixed in alongside older, obsolete entries. By marking this feed as a CompleteDataFeed, old entries can be safely discarded when the feed is refreshed, since we can assume the feed has provided descriptions for all current items. |
|
| Completed | Completed. | |
| CompletedActionStatus | An action that has already taken place. | |
| CompoundPriceSpecification | A compound price specification is one that bundles multiple prices that all apply in combination for different dimensions of consumption. Use the name property of the attached unit price specification for indicating the dimension of a price component (e.g. "electricity" or "final cleaning"). | |
| ComputerLanguage | This type covers computer programming languages such as Scheme and Lisp, as well as other language-like computer representations. Natural languages are best represented with the Language type. | |
| ComputerStore | A computer store. | |
| ConfirmAction | The act of notifying someone that a future event/action is going to happen as expected. Related actions:
|
|
| Consortium | A Consortium is a membership Organization whose members are typically Organizations. | |
| ConsumeAction | The act of ingesting information/resources/food. | |
| ContactPage | Web page type: Contact page. | |
| ContactPoint | A contact point—for example, a Customer Complaints department. | |
| ContactPointOption | Enumerated options related to a ContactPoint. | |
| ContagiousnessHealthAspect | Content about contagion mechanisms and contagiousness information over the topic. | |
| Continent | One of the continents (for example, Europe or Africa). | |
| ControlAction | An agent controls a device or application. | |
| ConvenienceStore | A convenience store. | |
| Conversation | One or more messages between organizations or people on a particular topic. Individual messages can be linked to the conversation with isPartOf or hasPart properties. | |
| CookAction | The act of producing/preparing food. | |
| Corporation | Organization: A business corporation. | |
| CorrectionComment | A comment that corrects CreativeWork. | |
| Country | A country. | |
| Course | A description of an educational course which may be offered as distinct instances at which take place at different times or take place at different locations, or be offered through different media or modes of study. An educational course is a sequence of one or more educational events and/or creative works which aims to build knowledge, competence or ability of learners. | |
| CourseInstance | An instance of a Course which is distinct from other instances because it is offered at a different time or location or through different media or modes of study or to a specific section of students. | |
| Courthouse | A courthouse. | |
| CoverArt | The artwork on the outer surface of a CreativeWork. | |
| CovidTestingFacility | A CovidTestingFacility is a MedicalClinic where testing for the COVID-19 Coronavirus disease is available. If the facility is being made available from an established Pharmacy, Hotel, or other non-medical organization, multiple types can be listed. This makes it easier to re-use existing schema.org information about that place e.g. contact info, address, opening hours. Note that in an emergency, such information may not always be reliable. | |
| CreateAction | The act of deliberately creating/producing/generating/building a result out of the agent. | |
| CreativeWork | The most generic kind of creative work, including books, movies, photographs, software programs, etc. | |
| CreativeWorkSeason | A media season e.g. tv, radio, video game etc. | |
| CreativeWorkSeries | A CreativeWorkSeries in schema.org is a group of related items, typically but not necessarily of the same kind. CreativeWorkSeries are usually organized into some order, often chronological. Unlike ItemList which is a general purpose data structure for lists of things, the emphasis with CreativeWorkSeries is on published materials (written e.g. books and periodicals, or media such as tv, radio and games). Specific subtypes are available for describing TVSeries, RadioSeries, MovieSeries, BookSeries, Periodical and VideoGameSeries. In each case, the hasPart / isPartOf properties can be used to relate the CreativeWorkSeries to its parts. The general CreativeWorkSeries type serves largely just to organize these more specific and practical subtypes. It is common for properties applicable to an item from the series to be usefully applied to the containing group. Schema.org attempts to anticipate some of these cases, but publishers should be free to apply properties of the series parts to the series as a whole wherever they seem appropriate. |
|
| CreditCard | A card payment method of a particular brand or name. Used to mark up a particular payment method and/or the financial product/service that supplies the card account. Commonly used values:
|
|
| Crematorium | A crematorium. | |
| CriticReview | A CriticReview is a more specialized form of Review written or published by a source that is recognized for its reviewing activities. These can include online columns, travel and food guides, TV and radio shows, blogs and other independent Web sites. CriticReviews are typically more in-depth and professionally written. For simpler, casually written user/visitor/viewer/customer reviews, it is more appropriate to use the UserReview type. Review aggregator sites such as Metacritic already separate out the site's user reviews from selected critic reviews that originate from third-party sources. | |
| CrossSectional | Studies carried out on pre-existing data (usually from 'snapshot' surveys), such as that collected by the Census Bureau. Sometimes called Prevalence Studies. | |
| CssSelectorType | Text representing a CSS selector. | |
| CurrencyConversionService | A service to convert funds from one currency to another currency. | |
| DDxElement | An alternative, closely-related condition typically considered later in the differential diagnosis process along with the signs that are used to distinguish it. | |
| DJMixAlbum | DJMixAlbum. | |
| DVDFormat | DVDFormat. | |
| DamagedCondition | Indicates that the item is damaged. | |
| DanceEvent | Event type: A social dance. | |
| DanceGroup | A dance group—for example, the Alvin Ailey Dance Theater or Riverdance. | |
| DataCatalog | A collection of datasets. | |
| DataDownload | A dataset in downloadable form. | |
| DataFeed | A single feed providing structured information about one or more entities or topics. | |
| DataFeedItem | A single item within a larger data feed. | |
| DataType | The basic data types such as Integers, Strings, etc. | |
| Dataset | A body of structured information describing some topic(s) of interest. | |
| Date | A date value in ISO 8601 date format. | |
| DateTime | A combination of date and time of day in the form [-]CCYY-MM-DDThh:mm:ss[Z|(+|-)hh:mm] (see Chapter 5.4 of ISO 8601). | |
| DatedMoneySpecification | A DatedMoneySpecification represents monetary values with optional start and end dates. For example, this could represent an employee's salary over a specific period of time. Note: This type has been superseded by MonetaryAmount use of that type is recommended | |
| DayOfWeek | The day of the week, e.g. used to specify to which day the opening hours of an OpeningHoursSpecification refer. Originally, URLs from GoodRelations were used (for Monday, Tuesday, Wednesday, Thursday, Friday, Saturday, Sunday plus a special entry for PublicHolidays); these have now been integrated directly into schema.org. |
|
| DaySpa | A day spa. | |
| DeactivateAction | The act of stopping or deactivating a device or application (e.g. stopping a timer or turning off a flashlight). | |
| DecontextualizedContent | Content coded 'missing context' in a MediaReview, considered in the context of how it was published or shared. For a VideoObject to be 'missing context': Presenting unaltered video in an inaccurate manner that misrepresents the footage. For example, using incorrect dates or locations, altering the transcript or sharing brief clips from a longer video to mislead viewers. (A video rated 'original' can also be missing context.) For an ImageObject to be 'missing context': Presenting unaltered images in an inaccurate manner to misrepresent the image and mislead the viewer. For example, a common tactic is using an unaltered image but saying it came from a different time or place. (An image rated 'original' can also be missing context.) For an ImageObject with embedded text to be 'missing context': An unaltered image presented in an inaccurate manner to misrepresent the image and mislead the viewer. For example, a common tactic is using an unaltered image but saying it came from a different time or place. (An 'original' image with inaccurate text would generally fall in this category.) For an AudioObject to be 'missing context': Unaltered audio presented in an inaccurate manner that misrepresents it. For example, using incorrect dates or locations, or sharing brief clips from a longer recording to mislead viewers. (Audio rated “original” can also be missing context.) |
|
| DefenceEstablishment | A defence establishment, such as an army or navy base. | |
| DefinedRegion | A DefinedRegion is a geographic area defined by potentially arbitrary (rather than political, administrative or natural geographical) criteria. Properties are provided for defining a region by reference to sets of postal codes. Examples: a delivery destination when shopping. Region where regional pricing is configured. Requirement 1: Country: US States: "NY", "CA" Requirement 2: Country: US PostalCode Set: { [94000-94585], [97000, 97999], [13000, 13599]} { [12345, 12345], [78945, 78945], } Region = state, canton, prefecture, autonomous community... |
|
| DefinedTerm | A word, name, acronym, phrase, etc. with a formal definition. Often used in the context of category or subject classification, glossaries or dictionaries, product or creative work types, etc. Use the name property for the term being defined, use termCode if the term has an alpha-numeric code allocated, use description to provide the definition of the term. | |
| DefinedTermSet | A set of defined terms for example a set of categories or a classification scheme, a glossary, dictionary or enumeration. | |
| DefinitiveLegalValue | Indicates a document for which the text is conclusively what the law says and is legally binding. (e.g. The digitally signed version of an Official Journal.) Something "Definitive" is considered to be also AuthoritativeLegalValue. | |
| DeleteAction | The act of editing a recipient by removing one of its objects. | |
| DeliveryChargeSpecification | The price for the delivery of an offer using a particular delivery method. | |
| DeliveryEvent | An event involving the delivery of an item. | |
| DeliveryMethod | A delivery method is a standardized procedure for transferring the product or service to the destination of fulfillment chosen by the customer. Delivery methods are characterized by the means of transportation used, and by the organization or group that is the contracting party for the sending organization or person. Commonly used values:
|
|
| DeliveryTimeSettings | A DeliveryTimeSettings represents re-usable pieces of shipping information, relating to timing. It is designed for publication on an URL that may be referenced via the shippingSettingsLink property of a OfferShippingDetails. Several occurrences can be published, distinguished (and identified/referenced) by their different values for transitTimeLabel. | |
| Demand | A demand entity represents the public, not necessarily binding, not necessarily exclusive, announcement by an organization or person to seek a certain type of goods or services. For describing demand using this type, the very same properties used for Offer apply. | |
| DemoAlbum | DemoAlbum. | |
| Dentist | A dentist. | |
| Dentistry | A branch of medicine that is involved in the dental care. | |
| DepartAction | The act of departing from a place. An agent departs from an fromLocation for a destination, optionally with participants. | |
| DepartmentStore | A department store. | |
| DepositAccount | A type of Bank Account with a main purpose of depositing funds to gain interest or other benefits. | |
| Dermatologic | Something relating to or practicing dermatology. | |
| Dermatology | A specific branch of medical science that pertains to diagnosis and treatment of disorders of skin. | |
| DiabeticDiet | A diet appropriate for people with diabetes. | |
| Diagnostic | A medical device used for diagnostic purposes. | |
| DiagnosticLab | A medical laboratory that offers on-site or off-site diagnostic services. | |
| DiagnosticProcedure | A medical procedure intended primarily for diagnostic, as opposed to therapeutic, purposes. | |
| Diet | A strategy of regulating the intake of food to achieve or maintain a specific health-related goal. | |
| DietNutrition | Dietetic and nutrition as a medical specialty. | |
| DietarySupplement | A product taken by mouth that contains a dietary ingredient intended to supplement the diet. Dietary ingredients may include vitamins, minerals, herbs or other botanicals, amino acids, and substances such as enzymes, organ tissues, glandulars and metabolites. | |
| DigitalAudioTapeFormat | DigitalAudioTapeFormat. | |
| DigitalDocument | An electronic file or document. | |
| DigitalDocumentPermission | A permission for a particular person or group to access a particular file. | |
| DigitalDocumentPermissionType | A type of permission which can be granted for accessing a digital document. | |
| DigitalFormat | DigitalFormat. | |
| DisabilitySupport | DisabilitySupport: this is a benefit for disability support. | |
| DisagreeAction | The act of expressing a difference of opinion with the object. An agent disagrees to/about an object (a proposition, topic or theme) with participants. | |
| Discontinued | Indicates that the item has been discontinued. | |
| DiscoverAction | The act of discovering/finding an object. | |
| DiscussionForumPosting | A posting to a discussion forum. | |
| DislikeAction | The act of expressing a negative sentiment about the object. An agent dislikes an object (a proposition, topic or theme) with participants. | |
| Distance | Properties that take Distances as values are of the form '<Number> <Length unit of measure>'. E.g., '7 ft'. | |
| DistanceFee | Represents the distance fee (e.g., price per km or mile) part of the total price for an offered product, for example a car rental. | |
| Distillery | A distillery. | |
| DonateAction | The act of providing goods, services, or money without compensation, often for philanthropic reasons. | |
| DoseSchedule | A specific dosing schedule for a drug or supplement. | |
| DoubleBlindedTrial | A trial design in which neither the researcher nor the patient knows the details of the treatment the patient was randomly assigned to. | |
| DownloadAction | The act of downloading an object. | |
| Downpayment | Represents the downpayment (up-front payment) price component of the total price for an offered product that has additional installment payments. | |
| DrawAction | The act of producing a visual/graphical representation of an object, typically with a pen/pencil and paper as instruments. | |
| Drawing | A picture or diagram made with a pencil, pen, or crayon rather than paint. | |
| DrinkAction | The act of swallowing liquids. | |
| DriveWheelConfigurationValue | A value indicating which roadwheels will receive torque. | |
| DrivingSchoolVehicleUsage | Indicates the usage of the vehicle for driving school. | |
| Drug | A chemical or biologic substance, used as a medical therapy, that has a physiological effect on an organism. Here the term drug is used interchangeably with the term medicine although clinical knowledge make a clear difference between them. | |
| DrugClass | A class of medical drugs, e.g., statins. Classes can represent general pharmacological class, common mechanisms of action, common physiological effects, etc. | |
| DrugCost | The cost per unit of a medical drug. Note that this type is not meant to represent the price in an offer of a drug for sale; see the Offer type for that. This type will typically be used to tag wholesale or average retail cost of a drug, or maximum reimbursable cost. Costs of medical drugs vary widely depending on how and where they are paid for, so while this type captures some of the variables, costs should be used with caution by consumers of this schema's markup. | |
| DrugCostCategory | Enumerated categories of medical drug costs. | |
| DrugLegalStatus | The legal availability status of a medical drug. | |
| DrugPregnancyCategory | Categories that represent an assessment of the risk of fetal injury due to a drug or pharmaceutical used as directed by the mother during pregnancy. | |
| DrugPrescriptionStatus | Indicates whether this drug is available by prescription or over-the-counter. | |
| DrugStrength | A specific strength in which a medical drug is available in a specific country. | |
| DryCleaningOrLaundry | A dry-cleaning business. | |
| Duration | Quantity: Duration (use ISO 8601 duration format). | |
| EBook | Book format: Ebook. | |
| EPRelease | EPRelease. | |
| EUEnergyEfficiencyCategoryA | Represents EU Energy Efficiency Class A as defined in EU energy labeling regulations. | |
| EUEnergyEfficiencyCategoryA1Plus | Represents EU Energy Efficiency Class A+ as defined in EU energy labeling regulations. | |
| EUEnergyEfficiencyCategoryA2Plus | Represents EU Energy Efficiency Class A++ as defined in EU energy labeling regulations. | |
| EUEnergyEfficiencyCategoryA3Plus | Represents EU Energy Efficiency Class A+++ as defined in EU energy labeling regulations. | |
| EUEnergyEfficiencyCategoryB | Represents EU Energy Efficiency Class B as defined in EU energy labeling regulations. | |
| EUEnergyEfficiencyCategoryC | Represents EU Energy Efficiency Class C as defined in EU energy labeling regulations. | |
| EUEnergyEfficiencyCategoryD | Represents EU Energy Efficiency Class D as defined in EU energy labeling regulations. | |
| EUEnergyEfficiencyCategoryE | Represents EU Energy Efficiency Class E as defined in EU energy labeling regulations. | |
| EUEnergyEfficiencyCategoryF | Represents EU Energy Efficiency Class F as defined in EU energy labeling regulations. | |
| EUEnergyEfficiencyCategoryG | Represents EU Energy Efficiency Class G as defined in EU energy labeling regulations. | |
| EUEnergyEfficiencyEnumeration | Enumerates the EU energy efficiency classes A-G as well as A+, A++, and A+++ as defined in EU directive 2017/1369. | |
| Ear | Ear function assessment with clinical examination. | |
| EatAction | The act of swallowing solid objects. | |
| EditedOrCroppedContent | Content coded 'edited or cropped content' in a MediaReview, considered in the context of how it was published or shared. For a VideoObject to be 'edited or cropped content': The video has been edited or rearranged. This category applies to time edits, including editing multiple videos together to alter the story being told or editing out large portions from a video. For an ImageObject to be 'edited or cropped content': Presenting a part of an image from a larger whole to mislead the viewer. For an ImageObject with embedded text to be 'edited or cropped content': Presenting a part of an image from a larger whole to mislead the viewer. For an AudioObject to be 'edited or cropped content': The audio has been edited or rearranged. This category applies to time edits, including editing multiple audio clips together to alter the story being told or editing out large portions from the recording. |
|
| EducationEvent | Event type: Education event. | |
| EducationalAudience | An EducationalAudience. | |
| EducationalOccupationalCredential | An educational or occupational credential. A diploma, academic degree, certification, qualification, badge, etc., that may be awarded to a person or other entity that meets the requirements defined by the credentialer. | |
| EducationalOccupationalProgram | A program offered by an institution which determines the learning progress to achieve an outcome, usually a credential like a degree or certificate. This would define a discrete set of opportunities (e.g., job, courses) that together constitute a program with a clear start, end, set of requirements, and transition to a new occupational opportunity (e.g., a job), or sometimes a higher educational opportunity (e.g., an advanced degree). | |
| EducationalOrganization | An educational organization. | |
| EffectivenessHealthAspect | Content about the effectiveness-related aspects of a health topic. | |
| Electrician | An electrician. | |
| ElectronicsStore | An electronics store. | |
| ElementarySchool | An elementary school. | |
| EmailMessage | An email message. | |
| Embassy | An embassy. | |
| Emergency | A specific branch of medical science that deals with the evaluation and initial treatment of medical conditions caused by trauma or sudden illness. | |
| EmergencyService | An emergency service, such as a fire station or ER. | |
| EmployeeRole | A subclass of OrganizationRole used to describe employee relationships. | |
| EmployerAggregateRating | An aggregate rating of an Organization related to its role as an employer. | |
| EmployerReview | An EmployerReview is a review of an Organization regarding its role as an employer, written by a current or former employee of that organization. | |
| EmploymentAgency | An employment agency. | |
| Endocrine | A specific branch of medical science that pertains to diagnosis and treatment of disorders of endocrine glands and their secretions. | |
| EndorseAction | An agent approves/certifies/likes/supports/sanction an object. | |
| EndorsementRating | An EndorsementRating is a rating that expresses some level of endorsement, for example inclusion in a "critic's pick" blog, a
"Like" or "+1" on a social network. It can be considered the result of an EndorseAction in which the object of the action is rated positively by
some agent. As is common elsewhere in schema.org, it is sometimes more useful to describe the results of such an action without explicitly describing the Action. An EndorsementRating may be part of a numeric scale or organized system, but this is not required: having an explicit type for indicating a positive, endorsement rating is particularly useful in the absence of numeric scales as it helps consumers understand that the rating is broadly positive. |
|
| Energy | Properties that take Energy as values are of the form '<Number> <Energy unit of measure>'. | |
| EnergyConsumptionDetails | EnergyConsumptionDetails represents information related to the energy efficiency of a product that consumes energy. The information that can be provided is based on international regulations such as for example EU directive 2017/1369 for energy labeling and the Energy labeling rule under the Energy Policy and Conservation Act (EPCA) in the US. | |
| EnergyEfficiencyEnumeration | Enumerates energy efficiency levels (also known as "classes" or "ratings") and certifications that are part of several international energy efficiency standards. | |
| EnergyStarCertified | Represents EnergyStar certification. | |
| EnergyStarEnergyEfficiencyEnumeration | Used to indicate whether a product is EnergyStar certified. | |
| EngineSpecification | Information about the engine of the vehicle. A vehicle can have multiple engines represented by multiple engine specification entities. | |
| EnrollingByInvitation | Enrolling participants by invitation only. | |
| EntertainmentBusiness | A business providing entertainment. | |
| EntryPoint | An entry point, within some Web-based protocol. | |
| Enumeration | Lists or enumerations—for example, a list of cuisines or music genres, etc. | |
| Episode | A media episode (e.g. TV, radio, video game) which can be part of a series or season. | |
| Event | An event happening at a certain time and location, such as a concert, lecture, or festival. Ticketing information may be added via the offers property. Repeated events may be structured as separate Event objects. | |
| EventAttendanceModeEnumeration | An EventAttendanceModeEnumeration value is one of potentially several modes of organising an event, relating to whether it is online or offline. | |
| EventCancelled | The event has been cancelled. If the event has multiple startDate values, all are assumed to be cancelled. Either startDate or previousStartDate may be used to specify the event's cancelled date(s). | |
| EventMovedOnline | Indicates that the event was changed to allow online participation. See eventAttendanceMode for specifics of whether it is now fully or partially online. | |
| EventPostponed | The event has been postponed and no new date has been set. The event's previousStartDate should be set. | |
| EventRescheduled | The event has been rescheduled. The event's previousStartDate should be set to the old date and the startDate should be set to the event's new date. (If the event has been rescheduled multiple times, the previousStartDate property may be repeated). | |
| EventReservation | A reservation for an event like a concert, sporting event, or lecture. Note: This type is for information about actual reservations, e.g. in confirmation emails or HTML pages with individual confirmations of reservations. For offers of tickets, use Offer. |
|
| EventScheduled | The event is taking place or has taken place on the startDate as scheduled. Use of this value is optional, as it is assumed by default. | |
| EventSeries | A series of Events. Included events can relate with the series using the superEvent property. An EventSeries is a collection of events that share some unifying characteristic. For example, "The Olympic Games" is a series, which is repeated regularly. The "2012 London Olympics" can be presented both as an Event in the series "Olympic Games", and as an EventSeries that included a number of sporting competitions as Events. The nature of the association between the events in an EventSeries can vary, but typical examples could include a thematic event series (e.g. topical meetups or classes), or a series of regular events that share a location, attendee group and/or organizers. EventSeries has been defined as a kind of Event to make it easy for publishers to use it in an Event context without worrying about which kinds of series are really event-like enough to call an Event. In general an EventSeries may seem more Event-like when the period of time is compact and when aspects such as location are fixed, but it may also sometimes prove useful to describe a longer-term series as an Event. |
|
| EventStatusType | EventStatusType is an enumeration type whose instances represent several states that an Event may be in. | |
| EventVenue | An event venue. | |
| EvidenceLevelA | Data derived from multiple randomized clinical trials or meta-analyses. | |
| EvidenceLevelB | Data derived from a single randomized trial, or nonrandomized studies. | |
| EvidenceLevelC | Only consensus opinion of experts, case studies, or standard-of-care. | |
| ExchangeRateSpecification | A structured value representing exchange rate. | |
| ExchangeRefund | A ExchangeRefund ... | |
| ExerciseAction | The act of participating in exertive activity for the purposes of improving health and fitness. | |
| ExerciseGym | A gym. | |
| ExercisePlan | Fitness-related activity designed for a specific health-related purpose, including defined exercise routines as well as activity prescribed by a clinician. | |
| ExhibitionEvent | Event type: Exhibition event, e.g. at a museum, library, archive, tradeshow, ... | |
| Eye | Eye or ophtalmological function assessment with clinical examination. | |
| FAQPage | A FAQPage is a WebPage presenting one or more "Frequently asked questions" (see also QAPage). | |
| FDAcategoryA | A designation by the US FDA signifying that adequate and well-controlled studies have failed to demonstrate a risk to the fetus in the first trimester of pregnancy (and there is no evidence of risk in later trimesters). | |
| FDAcategoryB | A designation by the US FDA signifying that animal reproduction studies have failed to demonstrate a risk to the fetus and there are no adequate and well-controlled studies in pregnant women. | |
| FDAcategoryC | A designation by the US FDA signifying that animal reproduction studies have shown an adverse effect on the fetus and there are no adequate and well-controlled studies in humans, but potential benefits may warrant use of the drug in pregnant women despite potential risks. | |
| FDAcategoryD | A designation by the US FDA signifying that there is positive evidence of human fetal risk based on adverse reaction data from investigational or marketing experience or studies in humans, but potential benefits may warrant use of the drug in pregnant women despite potential risks. | |
| FDAcategoryX | A designation by the US FDA signifying that studies in animals or humans have demonstrated fetal abnormalities and/or there is positive evidence of human fetal risk based on adverse reaction data from investigational or marketing experience, and the risks involved in use of the drug in pregnant women clearly outweigh potential benefits. | |
| FDAnotEvaluated | A designation that the drug in question has not been assigned a pregnancy category designation by the US FDA. | |
| FMRadioChannel | A radio channel that uses FM. | |
| FailedActionStatus | An action that failed to complete. The action's error property and the HTTP return code contain more information about the failure. | |
| False | The boolean value false. | |
| FastFoodRestaurant | A fast-food restaurant. | |
| Female | The female gender. | |
| Festival | Event type: Festival. | |
| FilmAction | The act of capturing sound and moving images on film, video, or digitally. | |
| FinancialProduct | A product provided to consumers and businesses by financial institutions such as banks, insurance companies, brokerage firms, consumer finance companies, and investment companies which comprise the financial services industry. | |
| FinancialService | Financial services business. | |
| FindAction | The act of finding an object. Related actions:
|
|
| FireStation | A fire station. With firemen. | |
| Flexibility | Physical activity that is engaged in to improve joint and muscle flexibility. | |
| Flight | An airline flight. | |
| FlightReservation | A reservation for air travel. Note: This type is for information about actual reservations, e.g. in confirmation emails or HTML pages with individual confirmations of reservations. For offers of tickets, use Offer. |
|
| Float | Data type: Floating number. | |
| FloorPlan | A FloorPlan is an explicit representation of a collection of similar accommodations, allowing the provision of common information (room counts, sizes, layout diagrams) and offers for rental or sale. In typical use, some ApartmentComplex has an accommodationFloorPlan which is a FloorPlan. A FloorPlan is always in the context of a particular place, either a larger ApartmentComplex or a single Apartment. The visual/spatial aspects of a floor plan (i.e. room layout, see wikipedia) can be indicated using image. | |
| Florist | A florist. | |
| FollowAction | The act of forming a personal connection with someone/something (object) unidirectionally/asymmetrically to get updates polled from. Related actions:
|
|
| FoodEstablishment | A food-related business. | |
| FoodEstablishmentReservation | A reservation to dine at a food-related business. Note: This type is for information about actual reservations, e.g. in confirmation emails or HTML pages with individual confirmations of reservations. |
|
| FoodEvent | Event type: Food event. | |
| FoodService | A food service, like breakfast, lunch, or dinner. | |
| FourWheelDriveConfiguration | Four-wheel drive is a transmission layout where the engine primarily drives two wheels with a part-time four-wheel drive capability. | |
| Friday | The day of the week between Thursday and Saturday. | |
| FrontWheelDriveConfiguration | Front-wheel drive is a transmission layout where the engine drives the front wheels. | |
| FullRefund | A FullRefund ... | |
| FundingAgency | A FundingAgency is an organization that implements one or more FundingSchemes and manages
the granting process (via Grants, typically MonetaryGrants).
A funding agency is not always required for grant funding, e.g. philanthropic giving, corporate sponsorship etc. Examples of funding agencies include ERC, REA, NIH, Bill and Melinda Gates Foundation... |
|
| FundingScheme | A FundingScheme combines organizational, project and policy aspects of grant-based funding that sets guidelines, principles and mechanisms to support other kinds of projects and activities. Funding is typically organized via Grant funding. Examples of funding schemes: Swiss Priority Programmes (SPPs); EU Framework 7 (FP7); Horizon 2020; the NIH-R01 Grant Program; Wellcome institutional strategic support fund. For large scale public sector funding, the management and administration of grant awards is often handled by other, dedicated, organizations - FundingAgencys such as ERC, REA, ... | |
| Fungus | Pathogenic fungus. | |
| FurnitureStore | A furniture store. | |
| Game | The Game type represents things which are games. These are typically rule-governed recreational activities, e.g. role-playing games in which players assume the role of characters in a fictional setting. | |
| GamePlayMode | Indicates whether this game is multi-player, co-op or single-player. | |
| GameServer | Server that provides game interaction in a multiplayer game. | |
| GameServerStatus | Status of a game server. | |
| GardenStore | A garden store. | |
| GasStation | A gas station. | |
| Gastroenterologic | A specific branch of medical science that pertains to diagnosis and treatment of disorders of digestive system. | |
| GatedResidenceCommunity | Residence type: Gated community. | |
| GenderType | An enumeration of genders. | |
| GeneralContractor | A general contractor. | |
| Genetic | A specific branch of medical science that pertains to hereditary transmission and the variation of inherited characteristics and disorders. | |
| Genitourinary | Genitourinary system function assessment with clinical examination. | |
| GeoCircle | A GeoCircle is a GeoShape representing a circular geographic area. As it is a GeoShape it provides the simple textual property 'circle', but also allows the combination of postalCode alongside geoRadius. The center of the circle can be indicated via the 'geoMidpoint' property, or more approximately using 'address', 'postalCode'. | |
| GeoCoordinates | The geographic coordinates of a place or event. | |
| GeoShape | The geographic shape of a place. A GeoShape can be described using several properties whose values are based on latitude/longitude pairs. Either whitespace or commas can be used to separate latitude and longitude; whitespace should be used when writing a list of several such points. | |
| GeospatialGeometry | (Eventually to be defined as) a supertype of GeoShape designed to accommodate definitions from Geo-Spatial best practices. | |
| Geriatric | A specific branch of medical science that is concerned with the diagnosis and treatment of diseases, debilities and provision of care to the aged. | |
| GettingAccessHealthAspect | Content that discusses practical and policy aspects for getting access to specific kinds of healthcare (e.g. distribution mechanisms for vaccines). | |
| GiveAction | The act of transferring ownership of an object to a destination. Reciprocal of TakeAction. Related actions:
|
|
| GlutenFreeDiet | A diet exclusive of gluten. | |
| GolfCourse | A golf course. | |
| GovernmentBenefitsType | GovernmentBenefitsType enumerates several kinds of government benefits to support the COVID-19 situation. Note that this structure may not capture all benefits offered. | |
| GovernmentBuilding | A government building. | |
| GovernmentOffice | A government office—for example, an IRS or DMV office. | |
| GovernmentOrganization | A governmental organization or agency. | |
| GovernmentPermit | A permit issued by a government agency. | |
| GovernmentService | A service provided by a government organization, e.g. food stamps, veterans benefits, etc. | |
| Grant | A grant, typically financial or otherwise quantifiable, of resources. Typically a funder sponsors some MonetaryAmount to an Organization or Person,
sometimes not necessarily via a dedicated or long-lived Project, resulting in one or more outputs, or fundedItems. For financial sponsorship, indicate the funder of a MonetaryGrant. For non-financial support, indicate sponsor of Grants of resources (e.g. office space). Grants support activities directed towards some agreed collective goals, often but not always organized as Projects. Long-lived projects are sometimes sponsored by a variety of grants over time, but it is also common for a project to be associated with a single grant. The amount of a Grant is represented using amount as a MonetaryAmount. |
|
| GraphicNovel | Book format: GraphicNovel. May represent a bound collection of ComicIssue instances. | |
| GroceryStore | A grocery store. | |
| GroupBoardingPolicy | The airline boards by groups based on check-in time, priority, etc. | |
| Guide | Guide is a page or article that recommend specific products or services, or aspects of a thing for a user to consider. A Guide may represent a Buying Guide and detail aspects of products or services for a user to consider. A Guide may represent a Product Guide and recommend specific products or services. A Guide may represent a Ranked List and recommend specific products or services with ranking. | |
| Gynecologic | A specific branch of medical science that pertains to the health care of women, particularly in the diagnosis and treatment of disorders affecting the female reproductive system. | |
| HVACBusiness | A business that provide Heating, Ventilation and Air Conditioning services. | |
| Hackathon | A hackathon event. | |
| HairSalon | A hair salon. | |
| HalalDiet | A diet conforming to Islamic dietary practices. | |
| Hardcover | Book format: Hardcover. | |
| HardwareStore | A hardware store. | |
| Head | Head assessment with clinical examination. | |
| HealthAndBeautyBusiness | Health and beauty. | |
| HealthAspectEnumeration | HealthAspectEnumeration enumerates several aspects of health content online, each of which might be described using hasHealthAspect and HealthTopicContent. | |
| HealthCare | HealthCare: this is a benefit for health care. | |
| HealthClub | A health club. | |
| HealthInsurancePlan | A US-style health insurance plan, including PPOs, EPOs, and HMOs. | |
| HealthPlanCostSharingSpecification | A description of costs to the patient under a given network or formulary. | |
| HealthPlanFormulary | For a given health insurance plan, the specification for costs and coverage of prescription drugs. | |
| HealthPlanNetwork | A US-style health insurance plan network. | |
| HealthTopicContent | HealthTopicContent is WebContent that is about some aspect of a health topic, e.g. a condition, its symptoms or treatments. Such content may be comprised of several parts or sections and use different types of media. Multiple instances of WebContent (and hence HealthTopicContent) can be related using hasPart / isPartOf where there is some kind of content hierarchy, and their content described with about and mentions e.g. building upon the existing MedicalCondition vocabulary. | |
| HearingImpairedSupported | Uses devices to support users with hearing impairments. | |
| Hematologic | A specific branch of medical science that pertains to diagnosis and treatment of disorders of blood and blood producing organs. | |
| HighSchool | A high school. | |
| HinduDiet | A diet conforming to Hindu dietary practices, in particular, beef-free. | |
| HinduTemple | A Hindu temple. | |
| HobbyShop | A store that sells materials useful or necessary for various hobbies. | |
| HomeAndConstructionBusiness | A construction business. A HomeAndConstructionBusiness is a LocalBusiness that provides services around homes and buildings. As a LocalBusiness it can be described as a provider of one or more Service(s). |
|
| HomeGoodsStore | A home goods store. | |
| Homeopathic | A system of medicine based on the principle that a disease can be cured by a substance that produces similar symptoms in healthy people. | |
| Hospital | A hospital. | |
| Hostel | A hostel - cheap accommodation, often in shared dormitories.
See also the dedicated document on the use of schema.org for marking up hotels and other forms of accommodations. |
|
| Hotel | A hotel is an establishment that provides lodging paid on a short-term basis (Source: Wikipedia, the free encyclopedia, see http://en.wikipedia.org/wiki/Hotel).
See also the dedicated document on the use of schema.org for marking up hotels and other forms of accommodations. |
|
| HotelRoom | A hotel room is a single room in a hotel.
See also the dedicated document on the use of schema.org for marking up hotels and other forms of accommodations. |
|
| House | A house is a building or structure that has the ability to be occupied for habitation by humans or other creatures (Source: Wikipedia, the free encyclopedia, see http://en.wikipedia.org/wiki/House). | |
| HousePainter | A house painting service. | |
| HowItWorksHealthAspect | Content that discusses and explains how a particular health-related topic works, e.g. in terms of mechanisms and underlying science. | |
| HowOrWhereHealthAspect | Information about how or where to find a topic. Also may contain location data that can be used for where to look for help if the topic is observed. | |
| HowTo | Instructions that explain how to achieve a result by performing a sequence of steps. | |
| HowToDirection | A direction indicating a single action to do in the instructions for how to achieve a result. | |
| HowToItem | An item used as either a tool or supply when performing the instructions for how to to achieve a result. | |
| HowToSection | A sub-grouping of steps in the instructions for how to achieve a result (e.g. steps for making a pie crust within a pie recipe). | |
| HowToStep | A step in the instructions for how to achieve a result. It is an ordered list with HowToDirection and/or HowToTip items. | |
| HowToSupply | A supply consumed when performing the instructions for how to achieve a result. | |
| HowToTip | An explanation in the instructions for how to achieve a result. It provides supplementary information about a technique, supply, author's preference, etc. It can explain what could be done, or what should not be done, but doesn't specify what should be done (see HowToDirection). | |
| HowToTool | A tool used (but not consumed) when performing instructions for how to achieve a result. | |
| HyperToc | A HyperToc represents a hypertext table of contents for complex media objects, such as VideoObject, AudioObject. Items in the table of contents are indicated using the tocEntry property, and typed HyperTocEntry. For cases where the same larger work is split into multiple files, associatedMedia can be used on individual HyperTocEntry items. | |
| HyperTocEntry | A HyperToEntry is an item within a HyperToc, which represents a hypertext table of contents for complex media objects, such as VideoObject, AudioObject. The media object itself is indicated using associatedMedia. Each section of interest within that content can be described with a HyperTocEntry, with associated startOffset and endOffset. When several entries are all from the same file, associatedMedia is used on the overarching HyperTocEntry; if the content has been split into multiple files, they can be referenced using associatedMedia on each HyperTocEntry. | |
| IceCreamShop | An ice cream shop. | |
| IgnoreAction | The act of intentionally disregarding the object. An agent ignores an object. | |
| ImageGallery | Web page type: Image gallery page. | |
| ImageObject | An image file. | |
| ImagingTest | Any medical imaging modality typically used for diagnostic purposes. | |
| InForce | Indicates that a legislation is in force. | |
| InStock | Indicates that the item is in stock. | |
| InStoreOnly | Indicates that the item is available only at physical locations. | |
| IndividualProduct | A single, identifiable product instance (e.g. a laptop with a particular serial number). | |
| Infectious | Something in medical science that pertains to infectious diseases i.e caused by bacterial, viral, fungal or parasitic infections. | |
| InfectiousAgentClass | Classes of agents or pathogens that transmit infectious diseases. Enumerated type. | |
| InfectiousDisease | An infectious disease is a clinically evident human disease resulting from the presence of pathogenic microbial agents, like pathogenic viruses, pathogenic bacteria, fungi, protozoa, multicellular parasites, and prions. To be considered an infectious disease, such pathogens are known to be able to cause this disease. | |
| InformAction | The act of notifying someone of information pertinent to them, with no expectation of a response. | |
| IngredientsHealthAspect | Content discussing ingredients-related aspects of a health topic. | |
| InsertAction | The act of adding at a specific location in an ordered collection. | |
| InstallAction | The act of installing an application. | |
| Installment | Represents the installment pricing component of the total price for an offered product. | |
| InsuranceAgency | An Insurance agency. | |
| Intangible | A utility class that serves as the umbrella for a number of 'intangible' things such as quantities, structured values, etc. | |
| Integer | Data type: Integer. | |
| InteractAction | The act of interacting with another person or organization. | |
| InteractionCounter | A summary of how users have interacted with this CreativeWork. In most cases, authors will use a subtype to specify the specific type of interaction. | |
| InternationalTrial | An international trial. | |
| InternetCafe | An internet cafe. | |
| InvestmentFund | A company or fund that gathers capital from a number of investors to create a pool of money that is then re-invested into stocks, bonds and other assets. | |
| InvestmentOrDeposit | A type of financial product that typically requires the client to transfer funds to a financial service in return for potential beneficial financial return. | |
| InviteAction | The act of asking someone to attend an event. Reciprocal of RsvpAction. | |
| Invoice | A statement of the money due for goods or services; a bill. | |
| InvoicePrice | Represents the invoice price of an offered product. | |
| ItemAvailability | A list of possible product availability options. | |
| ItemList | A list of items of any sort—for example, Top 10 Movies About Weathermen, or Top 100 Party Songs. Not to be confused with HTML lists, which are often used only for formatting. | |
| ItemListOrderAscending | An ItemList ordered with lower values listed first. | |
| ItemListOrderDescending | An ItemList ordered with higher values listed first. | |
| ItemListOrderType | Enumerated for values for itemListOrder for indicating how an ordered ItemList is organized. | |
| ItemListUnordered | An ItemList ordered with no explicit order. | |
| ItemPage | A page devoted to a single item, such as a particular product or hotel. | |
| JewelryStore | A jewelry store. | |
| JobPosting | A listing that describes a job opening in a certain organization. | |
| JoinAction | An agent joins an event/group with participants/friends at a location. Related actions:
|
|
| Joint | The anatomical location at which two or more bones make contact. | |
| KosherDiet | A diet conforming to Jewish dietary practices. | |
| LaboratoryScience | A medical science pertaining to chemical, hematological, immunologic, microscopic, or bacteriological diagnostic analyses or research. | |
| LakeBodyOfWater | A lake (for example, Lake Pontrachain). | |
| Landform | A landform or physical feature. Landform elements include mountains, plains, lakes, rivers, seascape and oceanic waterbody interface features such as bays, peninsulas, seas and so forth, including sub-aqueous terrain features such as submersed mountain ranges, volcanoes, and the great ocean basins. | |
| LandmarksOrHistoricalBuildings | An historical landmark or building. | |
| Language | Natural languages such as Spanish, Tamil, Hindi, English, etc. Formal language code tags expressed in BCP 47 can be used via the alternateName property. The Language type previously also covered programming languages such as Scheme and Lisp, which are now best represented using ComputerLanguage. | |
| LaserDiscFormat | LaserDiscFormat. | |
| LearningResource | The LearningResource type can be used to indicate CreativeWorks (whether physical or digital) that have a particular and explicit orientation towards learning, education, skill acquisition, and other educational purposes. LearningResource is expected to be used as an addition to a primary type such as Book, VideoObject, Product etc. EducationEvent serves a similar purpose for event-like things (e.g. a Trip). A LearningResource may be created as a result of an EducationEvent, for example by recording one. |
|
| LeaveAction | An agent leaves an event / group with participants/friends at a location. Related actions:
|
|
| LeftHandDriving | The steering position is on the left side of the vehicle (viewed from the main direction of driving). | |
| LegalForceStatus | A list of possible statuses for the legal force of a legislation. | |
| LegalService | A LegalService is a business that provides legally-oriented services, advice and representation, e.g. law firms. As a LocalBusiness it can be described as a provider of one or more Service(s). |
|
| LegalValueLevel | A list of possible levels for the legal validity of a legislation. | |
| Legislation | A legal document such as an act, decree, bill, etc. (enforceable or not) or a component of a legal act (like an article). | |
| LegislationObject | A specific object or file containing a Legislation. Note that the same Legislation can be published in multiple files. For example, a digitally signed PDF, a plain PDF and an HTML version. | |
| LegislativeBuilding | A legislative building—for example, the state capitol. | |
| LeisureTimeActivity | Any physical activity engaged in for recreational purposes. Examples may include ballroom dancing, roller skating, canoeing, fishing, etc. | |
| LendAction | The act of providing an object under an agreement that it will be returned at a later date. Reciprocal of BorrowAction. Related actions:
|
|
| Library | A library. | |
| LibrarySystem | A LibrarySystem is a collaborative system amongst several libraries. | |
| LifestyleModification | A process of care involving exercise, changes to diet, fitness routines, and other lifestyle changes aimed at improving a health condition. | |
| Ligament | A short band of tough, flexible, fibrous connective tissue that functions to connect multiple bones, cartilages, and structurally support joints. | |
| LikeAction | The act of expressing a positive sentiment about the object. An agent likes an object (a proposition, topic or theme) with participants. | |
| LimitedAvailability | Indicates that the item has limited availability. | |
| LimitedByGuaranteeCharity | LimitedByGuaranteeCharity: Non-profit type referring to a charitable company that is limited by guarantee (UK). | |
| LinkRole | A Role that represents a Web link e.g. as expressed via the 'url' property. Its linkRelationship property can indicate URL-based and plain textual link types e.g. those in IANA link registry or others such as 'amphtml'. This structure provides a placeholder where details from HTML's link element can be represented outside of HTML, e.g. in JSON-LD feeds. | |
| LiquorStore | A shop that sells alcoholic drinks such as wine, beer, whisky and other spirits. | |
| ListItem | An list item, e.g. a step in a checklist or how-to description. | |
| ListPrice | Represents the list price (the price a product is actually advertised for) of an offered product. | |
| ListenAction | The act of consuming audio content. | |
| LiteraryEvent | Event type: Literary event. | |
| LiveAlbum | LiveAlbum. | |
| LiveBlogPosting | A blog post intended to provide a rolling textual coverage of an ongoing event through continuous updates. | |
| LivingWithHealthAspect | Information about coping or life related to the topic. | |
| LoanOrCredit | A financial product for the loaning of an amount of money, or line of credit, under agreed terms and charges. | |
| LocalBusiness | A particular physical business or branch of an organization. Examples of LocalBusiness include a restaurant, a particular branch of a restaurant chain, a branch of a bank, a medical practice, a club, a bowling alley, etc. | |
| LocationFeatureSpecification | Specifies a location feature by providing a structured value representing a feature of an accommodation as a property-value pair of varying degrees of formality. | |
| LockerDelivery | A DeliveryMethod in which an item is made available via locker. | |
| Locksmith | A locksmith. | |
| LodgingBusiness | A lodging business, such as a motel, hotel, or inn. | |
| LodgingReservation | A reservation for lodging at a hotel, motel, inn, etc. Note: This type is for information about actual reservations, e.g. in confirmation emails or HTML pages with individual confirmations of reservations. |
|
| Longitudinal | Unlike cross-sectional studies, longitudinal studies track the same people, and therefore the differences observed in those people are less likely to be the result of cultural differences across generations. Longitudinal studies are also used in medicine to uncover predictors of certain diseases. | |
| LoseAction | The act of being defeated in a competitive activity. | |
| LowCalorieDiet | A diet focused on reduced calorie intake. | |
| LowFatDiet | A diet focused on reduced fat and cholesterol intake. | |
| LowLactoseDiet | A diet appropriate for people with lactose intolerance. | |
| LowSaltDiet | A diet focused on reduced sodium intake. | |
| Lung | Lung and respiratory system clinical examination. | |
| LymphaticVessel | A type of blood vessel that specifically carries lymph fluid unidirectionally toward the heart. | |
| MRI | Magnetic resonance imaging. | |
| MSRP | Represents the manufacturer suggested retail price ("MSRP") of an offered product. | |
| Male | The male gender. | |
| Manuscript | A book, document, or piece of music written by hand rather than typed or printed. | |
| Map | A map. | |
| MapCategoryType | An enumeration of several kinds of Map. | |
| MarryAction | The act of marrying a person. | |
| Mass | Properties that take Mass as values are of the form '<Number> <Mass unit of measure>'. E.g., '7 kg'. | |
| MathSolver | A math solver which is capable of solving a subset of mathematical problems. | |
| MaximumDoseSchedule | The maximum dosing schedule considered safe for a drug or supplement as recommended by an authority or by the drug/supplement's manufacturer. Capture the recommending authority in the recognizingAuthority property of MedicalEntity. | |
| MayTreatHealthAspect | Related topics may be treated by a Topic. | |
| MeasurementTypeEnumeration | Enumeration of common measurement types (or dimensions), for example "chest" for a person, "inseam" for pants, "gauge" for screws, or "wheel" for bicycles. | |
| MediaGallery | Web page type: Media gallery page. A mixed-media page that can contains media such as images, videos, and other multimedia. | |
| MediaManipulationRatingEnumeration | Codes for use with the mediaAuthenticityCategory property, indicating the authenticity of a media object (in the context of how it was published or shared). In general these codes are not mutually exclusive, although some combinations (such as 'original' versus 'transformed', 'edited' and 'staged') would be contradictory if applied in the same MediaReview. Note that the application of these codes is with regard to a piece of media shared or published in a particular context. | |
| MediaObject | A media object, such as an image, video, or audio object embedded in a web page or a downloadable dataset i.e. DataDownload. Note that a creative work may have many media objects associated with it on the same web page. For example, a page about a single song (MusicRecording) may have a music video (VideoObject), and a high and low bandwidth audio stream (2 AudioObject's). | |
| MediaReview | A MediaReview is a more specialized form of Review dedicated to the evaluation of media content online, typically in the context of fact-checking and misinformation. For more general reviews of media in the broader sense, use UserReview, CriticReview or other Review types. This definition is a work in progress. While the MediaManipulationRatingEnumeration list reflects significant community review amongst fact-checkers and others working to combat misinformation, the specific structures for representing media objects, their versions and publication context, is still evolving. Similarly, best practices for the relationship between MediaReview and ClaimReview markup has not yet been finalized. | |
| MediaSubscription | A subscription which allows a user to access media including audio, video, books, etc. | |
| MedicalAudience | Target audiences for medical web pages. | |
| MedicalAudienceType | Target audiences types for medical web pages. Enumerated type. | |
| MedicalBusiness | A particular physical or virtual business of an organization for medical purposes. Examples of MedicalBusiness include differents business run by health professionals. | |
| MedicalCause | The causative agent(s) that are responsible for the pathophysiologic process that eventually results in a medical condition, symptom or sign. In this schema, unless otherwise specified this is meant to be the proximate cause of the medical condition, symptom or sign. The proximate cause is defined as the causative agent that most directly results in the medical condition, symptom or sign. For example, the HIV virus could be considered a cause of AIDS. Or in a diagnostic context, if a patient fell and sustained a hip fracture and two days later sustained a pulmonary embolism which eventuated in a cardiac arrest, the cause of the cardiac arrest (the proximate cause) would be the pulmonary embolism and not the fall. Medical causes can include cardiovascular, chemical, dermatologic, endocrine, environmental, gastroenterologic, genetic, hematologic, gynecologic, iatrogenic, infectious, musculoskeletal, neurologic, nutritional, obstetric, oncologic, otolaryngologic, pharmacologic, psychiatric, pulmonary, renal, rheumatologic, toxic, traumatic, or urologic causes; medical conditions can be causes as well. | |
| MedicalClinic | A facility, often associated with a hospital or medical school, that is devoted to the specific diagnosis and/or healthcare. Previously limited to outpatients but with evolution it may be open to inpatients as well. | |
| MedicalCode | A code for a medical entity. | |
| MedicalCondition | Any condition of the human body that affects the normal functioning of a person, whether physically or mentally. Includes diseases, injuries, disabilities, disorders, syndromes, etc. | |
| MedicalConditionStage | A stage of a medical condition, such as 'Stage IIIa'. | |
| MedicalContraindication | A condition or factor that serves as a reason to withhold a certain medical therapy. Contraindications can be absolute (there are no reasonable circumstances for undertaking a course of action) or relative (the patient is at higher risk of complications, but that these risks may be outweighed by other considerations or mitigated by other measures). | |
| MedicalDevice | Any object used in a medical capacity, such as to diagnose or treat a patient. | |
| MedicalDevicePurpose | Categories of medical devices, organized by the purpose or intended use of the device. | |
| MedicalEntity | The most generic type of entity related to health and the practice of medicine. | |
| MedicalEnumeration | Enumerations related to health and the practice of medicine: A concept that is used to attribute a quality to another concept, as a qualifier, a collection of items or a listing of all of the elements of a set in medicine practice. | |
| MedicalEvidenceLevel | Level of evidence for a medical guideline. Enumerated type. | |
| MedicalGuideline | Any recommendation made by a standard society (e.g. ACC/AHA) or consensus statement that denotes how to diagnose and treat a particular condition. Note: this type should be used to tag the actual guideline recommendation; if the guideline recommendation occurs in a larger scholarly article, use MedicalScholarlyArticle to tag the overall article, not this type. Note also: the organization making the recommendation should be captured in the recognizingAuthority base property of MedicalEntity. | |
| MedicalGuidelineContraindication | A guideline contraindication that designates a process as harmful and where quality of the data supporting the contraindication is sound. | |
| MedicalGuidelineRecommendation | A guideline recommendation that is regarded as efficacious and where quality of the data supporting the recommendation is sound. | |
| MedicalImagingTechnique | Any medical imaging modality typically used for diagnostic purposes. Enumerated type. | |
| MedicalIndication | A condition or factor that indicates use of a medical therapy, including signs, symptoms, risk factors, anatomical states, etc. | |
| MedicalIntangible | A utility class that serves as the umbrella for a number of 'intangible' things in the medical space. | |
| MedicalObservationalStudy | An observational study is a type of medical study that attempts to infer the possible effect of a treatment through observation of a cohort of subjects over a period of time. In an observational study, the assignment of subjects into treatment groups versus control groups is outside the control of the investigator. This is in contrast with controlled studies, such as the randomized controlled trials represented by MedicalTrial, where each subject is randomly assigned to a treatment group or a control group before the start of the treatment. | |
| MedicalObservationalStudyDesign | Design models for observational medical studies. Enumerated type. | |
| MedicalOrganization | A medical organization (physical or not), such as hospital, institution or clinic. | |
| MedicalProcedure | A process of care used in either a diagnostic, therapeutic, preventive or palliative capacity that relies on invasive (surgical), non-invasive, or other techniques. | |
| MedicalProcedureType | An enumeration that describes different types of medical procedures. | |
| MedicalResearcher | Medical researchers. | |
| MedicalRiskCalculator | A complex mathematical calculation requiring an online calculator, used to assess prognosis. Note: use the url property of Thing to record any URLs for online calculators. | |
| MedicalRiskEstimator | Any rule set or interactive tool for estimating the risk of developing a complication or condition. | |
| MedicalRiskFactor | A risk factor is anything that increases a person's likelihood of developing or contracting a disease, medical condition, or complication. | |
| MedicalRiskScore | A simple system that adds up the number of risk factors to yield a score that is associated with prognosis, e.g. CHAD score, TIMI risk score. | |
| MedicalScholarlyArticle | A scholarly article in the medical domain. | |
| MedicalSign | Any physical manifestation of a person's medical condition discoverable by objective diagnostic tests or physical examination. | |
| MedicalSignOrSymptom | Any feature associated or not with a medical condition. In medicine a symptom is generally subjective while a sign is objective. | |
| MedicalSpecialty | Any specific branch of medical science or practice. Medical specialities include clinical specialties that pertain to particular organ systems and their respective disease states, as well as allied health specialties. Enumerated type. | |
| MedicalStudy | A medical study is an umbrella type covering all kinds of research studies relating to human medicine or health, including observational studies and interventional trials and registries, randomized, controlled or not. When the specific type of study is known, use one of the extensions of this type, such as MedicalTrial or MedicalObservationalStudy. Also, note that this type should be used to mark up data that describes the study itself; to tag an article that publishes the results of a study, use MedicalScholarlyArticle. Note: use the code property of MedicalEntity to store study IDs, e.g. clinicaltrials.gov ID. | |
| MedicalStudyStatus | The status of a medical study. Enumerated type. | |
| MedicalSymptom | Any complaint sensed and expressed by the patient (therefore defined as subjective) like stomachache, lower-back pain, or fatigue. | |
| MedicalTest | Any medical test, typically performed for diagnostic purposes. | |
| MedicalTestPanel | Any collection of tests commonly ordered together. | |
| MedicalTherapy | Any medical intervention designed to prevent, treat, and cure human diseases and medical conditions, including both curative and palliative therapies. Medical therapies are typically processes of care relying upon pharmacotherapy, behavioral therapy, supportive therapy (with fluid or nutrition for example), or detoxification (e.g. hemodialysis) aimed at improving or preventing a health condition. | |
| MedicalTrial | A medical trial is a type of medical study that uses scientific process used to compare the safety and efficacy of medical therapies or medical procedures. In general, medical trials are controlled and subjects are allocated at random to the different treatment and/or control groups. | |
| MedicalTrialDesign | Design models for medical trials. Enumerated type. | |
| MedicalWebPage | A web page that provides medical information. | |
| MedicineSystem | Systems of medical practice. | |
| MeetingRoom | A meeting room, conference room, or conference hall is a room provided for singular events such as business conferences and meetings (Source: Wikipedia, the free encyclopedia, see http://en.wikipedia.org/wiki/Conference_hall).
See also the dedicated document on the use of schema.org for marking up hotels and other forms of accommodations. |
|
| MensClothingStore | A men's clothing store. | |
| Menu | A structured representation of food or drink items available from a FoodEstablishment. | |
| MenuItem | A food or drink item listed in a menu or menu section. | |
| MenuSection | A sub-grouping of food or drink items in a menu. E.g. courses (such as 'Dinner', 'Breakfast', etc.), specific type of dishes (such as 'Meat', 'Vegan', 'Drinks', etc.), or some other classification made by the menu provider. | |
| MerchantReturnEnumeration | MerchantReturnEnumeration enumerates several kinds of product return policy. Note that this structure may not capture all aspects of the policy. | |
| MerchantReturnFiniteReturnWindow | MerchantReturnFiniteReturnWindow: there is a finite window for product returns. | |
| MerchantReturnNotPermitted | MerchantReturnNotPermitted: product returns are not permitted. | |
| MerchantReturnPolicy | A MerchantReturnPolicy provides information about product return policies associated with an Organization or Product. | |
| MerchantReturnUnlimitedWindow | MerchantReturnUnlimitedWindow: there is an unlimited window for product returns. | |
| MerchantReturnUnspecified | MerchantReturnUnspecified: a product return policy is not specified here. | |
| Message | A single message from a sender to one or more organizations or people. | |
| MiddleSchool | A middle school (typically for children aged around 11-14, although this varies somewhat). | |
| Midwifery | A nurse-like health profession that deals with pregnancy, childbirth, and the postpartum period (including care of the newborn), besides sexual and reproductive health of women throughout their lives. | |
| MinimumAdvertisedPrice | Represents the minimum advertised price ("MAP") (as dictated by the manufacturer) of an offered product. | |
| MisconceptionsHealthAspect | Content about common misconceptions and myths that are related to a topic. | |
| MixedEventAttendanceMode | MixedEventAttendanceMode - an event that is conducted as a combination of both offline and online modes. | |
| MixtapeAlbum | MixtapeAlbum. | |
| MobileApplication | A software application designed specifically to work well on a mobile device such as a telephone. | |
| MobilePhoneStore | A store that sells mobile phones and related accessories. | |
| Monday | The day of the week between Sunday and Tuesday. | |
| MonetaryAmount | A monetary value or range. This type can be used to describe an amount of money such as $50 USD, or a range as in describing a bank account being suitable for a balance between £1,000 and £1,000,000 GBP, or the value of a salary, etc. It is recommended to use PriceSpecification Types to describe the price of an Offer, Invoice, etc. | |
| MonetaryAmountDistribution | A statistical distribution of monetary amounts. | |
| MonetaryGrant | A monetary grant. | |
| MoneyTransfer | The act of transferring money from one place to another place. This may occur electronically or physically. | |
| MortgageLoan | A loan in which property or real estate is used as collateral. (A loan securitized against some real estate). | |
| Mosque | A mosque. | |
| Motel | A motel.
See also the dedicated document on the use of schema.org for marking up hotels and other forms of accommodations. |
|
| Motorcycle | A motorcycle or motorbike is a single-track, two-wheeled motor vehicle. | |
| MotorcycleDealer | A motorcycle dealer. | |
| MotorcycleRepair | A motorcycle repair shop. | |
| MotorizedBicycle | A motorized bicycle is a bicycle with an attached motor used to power the vehicle, or to assist with pedaling. | |
| Mountain | A mountain, like Mount Whitney or Mount Everest. | |
| MoveAction | The act of an agent relocating to a place. Related actions:
|
|
| Movie | A movie. | |
| MovieClip | A short segment/part of a movie. | |
| MovieRentalStore | A movie rental store. | |
| MovieSeries | A series of movies. Included movies can be indicated with the hasPart property. | |
| MovieTheater | A movie theater. | |
| MovingCompany | A moving company. | |
| MultiCenterTrial | A trial that takes place at multiple centers. | |
| MultiPlayer | Play mode: MultiPlayer. Requiring or allowing multiple human players to play simultaneously. | |
| MulticellularParasite | Multicellular parasite that causes an infection. | |
| Muscle | A muscle is an anatomical structure consisting of a contractile form of tissue that animals use to effect movement. | |
| Musculoskeletal | A specific branch of medical science that pertains to diagnosis and treatment of disorders of muscles, ligaments and skeletal system. | |
| MusculoskeletalExam | Musculoskeletal system clinical examination. | |
| Museum | A museum. | |
| MusicAlbum | A collection of music tracks. | |
| MusicAlbumProductionType | Classification of the album by it's type of content: soundtrack, live album, studio album, etc. | |
| MusicAlbumReleaseType | The kind of release which this album is: single, EP or album. | |
| MusicComposition | A musical composition. | |
| MusicEvent | Event type: Music event. | |
| MusicGroup | A musical group, such as a band, an orchestra, or a choir. Can also be a solo musician. | |
| MusicPlaylist | A collection of music tracks in playlist form. | |
| MusicRecording | A music recording (track), usually a single song. | |
| MusicRelease | A MusicRelease is a specific release of a music album. | |
| MusicReleaseFormatType | Format of this release (the type of recording media used, ie. compact disc, digital media, LP, etc.). | |
| MusicStore | A music store. | |
| MusicVenue | A music venue. | |
| MusicVideoObject | A music video file. | |
| NGO | Organization: Non-governmental Organization. | |
| NLNonprofitType | NLNonprofitType: Non-profit organization type originating from the Netherlands. | |
| NailSalon | A nail salon. | |
| Neck | Neck assessment with clinical examination. | |
| Nerve | A common pathway for the electrochemical nerve impulses that are transmitted along each of the axons. | |
| Neuro | Neurological system clinical examination. | |
| Neurologic | A specific branch of medical science that studies the nerves and nervous system and its respective disease states. | |
| NewCondition | Indicates that the item is new. | |
| NewsArticle | A NewsArticle is an article whose content reports news, or provides background context and supporting materials for understanding the news. A more detailed overview of schema.org News markup is also available. |
|
| NewsMediaOrganization | A News/Media organization such as a newspaper or TV station. | |
| Newspaper | A publication containing information about varied topics that are pertinent to general information, a geographic area, or a specific subject matter (i.e. business, culture, education). Often published daily. | |
| NightClub | A nightclub or discotheque. | |
| NoninvasiveProcedure | A type of medical procedure that involves noninvasive techniques. | |
| Nonprofit501a | Nonprofit501a: Non-profit type referring to Farmers’ Cooperative Associations. | |
| Nonprofit501c1 | Nonprofit501c1: Non-profit type referring to Corporations Organized Under Act of Congress, including Federal Credit Unions and National Farm Loan Associations. | |
| Nonprofit501c10 | Nonprofit501c10: Non-profit type referring to Domestic Fraternal Societies and Associations. | |
| Nonprofit501c11 | Nonprofit501c11: Non-profit type referring to Teachers' Retirement Fund Associations. | |
| Nonprofit501c12 | Nonprofit501c12: Non-profit type referring to Benevolent Life Insurance Associations, Mutual Ditch or Irrigation Companies, Mutual or Cooperative Telephone Companies. | |
| Nonprofit501c13 | Nonprofit501c13: Non-profit type referring to Cemetery Companies. | |
| Nonprofit501c14 | Nonprofit501c14: Non-profit type referring to State-Chartered Credit Unions, Mutual Reserve Funds. | |
| Nonprofit501c15 | Nonprofit501c15: Non-profit type referring to Mutual Insurance Companies or Associations. | |
| Nonprofit501c16 | Nonprofit501c16: Non-profit type referring to Cooperative Organizations to Finance Crop Operations. | |
| Nonprofit501c17 | Nonprofit501c17: Non-profit type referring to Supplemental Unemployment Benefit Trusts. | |
| Nonprofit501c18 | Nonprofit501c18: Non-profit type referring to Employee Funded Pension Trust (created before 25 June 1959). | |
| Nonprofit501c19 | Nonprofit501c19: Non-profit type referring to Post or Organization of Past or Present Members of the Armed Forces. | |
| Nonprofit501c2 | Nonprofit501c2: Non-profit type referring to Title-holding Corporations for Exempt Organizations. | |
| Nonprofit501c20 | Nonprofit501c20: Non-profit type referring to Group Legal Services Plan Organizations. | |
| Nonprofit501c21 | Nonprofit501c21: Non-profit type referring to Black Lung Benefit Trusts. | |
| Nonprofit501c22 | Nonprofit501c22: Non-profit type referring to Withdrawal Liability Payment Funds. | |
| Nonprofit501c23 | Nonprofit501c23: Non-profit type referring to Veterans Organizations. | |
| Nonprofit501c24 | Nonprofit501c24: Non-profit type referring to Section 4049 ERISA Trusts. | |
| Nonprofit501c25 | Nonprofit501c25: Non-profit type referring to Real Property Title-Holding Corporations or Trusts with Multiple Parents. | |
| Nonprofit501c26 | Nonprofit501c26: Non-profit type referring to State-Sponsored Organizations Providing Health Coverage for High-Risk Individuals. | |
| Nonprofit501c27 | Nonprofit501c27: Non-profit type referring to State-Sponsored Workers' Compensation Reinsurance Organizations. | |
| Nonprofit501c28 | Nonprofit501c28: Non-profit type referring to National Railroad Retirement Investment Trusts. | |
| Nonprofit501c3 | Nonprofit501c3: Non-profit type referring to Religious, Educational, Charitable, Scientific, Literary, Testing for Public Safety, to Foster National or International Amateur Sports Competition, or Prevention of Cruelty to Children or Animals Organizations. | |
| Nonprofit501c4 | Nonprofit501c4: Non-profit type referring to Civic Leagues, Social Welfare Organizations, and Local Associations of Employees. | |
| Nonprofit501c5 | Nonprofit501c5: Non-profit type referring to Labor, Agricultural and Horticultural Organizations. | |
| Nonprofit501c6 | Nonprofit501c6: Non-profit type referring to Business Leagues, Chambers of Commerce, Real Estate Boards. | |
| Nonprofit501c7 | Nonprofit501c7: Non-profit type referring to Social and Recreational Clubs. | |
| Nonprofit501c8 | Nonprofit501c8: Non-profit type referring to Fraternal Beneficiary Societies and Associations. | |
| Nonprofit501c9 | Nonprofit501c9: Non-profit type referring to Voluntary Employee Beneficiary Associations. | |
| Nonprofit501d | Nonprofit501d: Non-profit type referring to Religious and Apostolic Associations. | |
| Nonprofit501e | Nonprofit501e: Non-profit type referring to Cooperative Hospital Service Organizations. | |
| Nonprofit501f | Nonprofit501f: Non-profit type referring to Cooperative Service Organizations. | |
| Nonprofit501k | Nonprofit501k: Non-profit type referring to Child Care Organizations. | |
| Nonprofit501n | Nonprofit501n: Non-profit type referring to Charitable Risk Pools. | |
| Nonprofit501q | Nonprofit501q: Non-profit type referring to Credit Counseling Organizations. | |
| Nonprofit527 | Nonprofit527: Non-profit type referring to Political organizations. | |
| NonprofitANBI | NonprofitANBI: Non-profit type referring to a Public Benefit Organization (NL). | |
| NonprofitSBBI | NonprofitSBBI: Non-profit type referring to a Social Interest Promoting Institution (NL). | |
| NonprofitType | NonprofitType enumerates several kinds of official non-profit types of which a non-profit organization can be. | |
| Nose | Nose function assessment with clinical examination. | |
| NotInForce | Indicates that a legislation is currently not in force. | |
| NotYetRecruiting | Not yet recruiting. | |
| Notary | A notary. | |
| NoteDigitalDocument | A file containing a note, primarily for the author. | |
| Number | Data type: Number. Usage guidelines:
|
|
| Nursing | A health profession of a person formally educated and trained in the care of the sick or infirm person. | |
| NutritionInformation | Nutritional information about the recipe. | |
| OTC | The character of a medical substance, typically a medicine, of being available over the counter or not. | |
| Observation | Instances of the class Observation are used to specify observations about an entity (which may or may not be an instance of a StatisticalPopulation), at a particular time. The principal properties of an Observation are observedNode, measuredProperty, measuredValue (or median, etc.) and observationDate (measuredProperty properties can, but need not always, be W3C RDF Data Cube "measure properties", as in the lifeExpectancy example). See also StatisticalPopulation, and the data and datasets overview for more details. | |
| Observational | An observational study design. | |
| Obstetric | A specific branch of medical science that specializes in the care of women during the prenatal and postnatal care and with the delivery of the child. | |
| Occupation | A profession, may involve prolonged training and/or a formal qualification. | |
| OccupationalActivity | Any physical activity engaged in for job-related purposes. Examples may include waiting tables, maid service, carrying a mailbag, picking fruits or vegetables, construction work, etc. | |
| OccupationalExperienceRequirements | Indicates employment-related experience requirements, e.g. monthsOfExperience. | |
| OccupationalTherapy | A treatment of people with physical, emotional, or social problems, using purposeful activity to help them overcome or learn to deal with their problems. | |
| OceanBodyOfWater | An ocean (for example, the Pacific). | |
| Offer | An offer to transfer some rights to an item or to provide a service — for example, an offer to sell tickets to an event, to rent the DVD of a movie, to stream a TV show over the internet, to repair a motorcycle, or to loan a book. Note: As the businessFunction property, which identifies the form of offer (e.g. sell, lease, repair, dispose), defaults to http://purl.org/goodrelations/v1#Sell; an Offer without a defined businessFunction value can be assumed to be an offer to sell. For GTIN-related fields, see Check Digit calculator and validation guide from GS1. |
|
| OfferCatalog | An OfferCatalog is an ItemList that contains related Offers and/or further OfferCatalogs that are offeredBy the same provider. | |
| OfferForLease | An OfferForLease in Schema.org represents an Offer to lease out something, i.e. an Offer whose businessFunction is lease out. See Good Relations for background on the underlying concepts. | |
| OfferForPurchase | An OfferForPurchase in Schema.org represents an Offer to sell something, i.e. an Offer whose businessFunction is sell. See Good Relations for background on the underlying concepts. | |
| OfferItemCondition | A list of possible conditions for the item. | |
| OfferShippingDetails | OfferShippingDetails represents information about shipping destinations. Multiple of these entities can be used to represent different shipping rates for different destinations: One entity for Alaska/Hawaii. A different one for continental US.A different one for all France. Multiple of these entities can be used to represent different shipping costs and delivery times. Two entities that are identical but differ in rate and time: e.g. Cheaper and slower: $5 in 5-7days or Fast and expensive: $15 in 1-2 days. |
|
| OfficeEquipmentStore | An office equipment store. | |
| OfficialLegalValue | All the documents published by an official publisher should have at least the legal value level "OfficialLegalValue". This indicates that the document was published by an organisation with the public task of making it available (e.g. a consolidated version of a EU directive published by the EU Office of Publications). | |
| OfflineEventAttendanceMode | OfflineEventAttendanceMode - an event that is primarily conducted offline. | |
| OfflinePermanently | Game server status: OfflinePermanently. Server is offline and not available. | |
| OfflineTemporarily | Game server status: OfflineTemporarily. Server is offline now but it can be online soon. | |
| OnDemandEvent | A publication event e.g. catch-up TV or radio podcast, during which a program is available on-demand. | |
| OnSitePickup | A DeliveryMethod in which an item is collected on site, e.g. in a store or at a box office. | |
| Oncologic | A specific branch of medical science that deals with benign and malignant tumors, including the study of their development, diagnosis, treatment and prevention. | |
| OneTimePayments | OneTimePayments: this is a benefit for one-time payments for individuals. | |
| Online | Game server status: Online. Server is available. | |
| OnlineEventAttendanceMode | OnlineEventAttendanceMode - an event that is primarily conducted online. | |
| OnlineFull | Game server status: OnlineFull. Server is online but unavailable. The maximum number of players has reached. | |
| OnlineOnly | Indicates that the item is available only online. | |
| OpenTrial | A trial design in which the researcher knows the full details of the treatment, and so does the patient. | |
| OpeningHoursSpecification | A structured value providing information about the opening hours of a place or a certain service inside a place. The place is open if the opens property is specified, and closed otherwise. If the value for the closes property is less than the value for the opens property then the hour range is assumed to span over the next day. |
|
| OpinionNewsArticle | An OpinionNewsArticle is a NewsArticle that primarily expresses opinions rather than journalistic reporting of news and events. For example, a NewsArticle consisting of a column or Blog/BlogPosting entry in the Opinions section of a news publication. | |
| Optician | A store that sells reading glasses and similar devices for improving vision. | |
| Optometric | The science or practice of testing visual acuity and prescribing corrective lenses. | |
| Order | An order is a confirmation of a transaction (a receipt), which can contain multiple line items, each represented by an Offer that has been accepted by the customer. | |
| OrderAction | An agent orders an object/product/service to be delivered/sent. | |
| OrderCancelled | OrderStatus representing cancellation of an order. | |
| OrderDelivered | OrderStatus representing successful delivery of an order. | |
| OrderInTransit | OrderStatus representing that an order is in transit. | |
| OrderItem | An order item is a line of an order. It includes the quantity and shipping details of a bought offer. | |
| OrderPaymentDue | OrderStatus representing that payment is due on an order. | |
| OrderPickupAvailable | OrderStatus representing availability of an order for pickup. | |
| OrderProblem | OrderStatus representing that there is a problem with the order. | |
| OrderProcessing | OrderStatus representing that an order is being processed. | |
| OrderReturned | OrderStatus representing that an order has been returned. | |
| OrderStatus | Enumerated status values for Order. | |
| Organization | An organization such as a school, NGO, corporation, club, etc. | |
| OrganizationRole | A subclass of Role used to describe roles within organizations. | |
| OrganizeAction | The act of manipulating/administering/supervising/controlling one or more objects. | |
| OriginalMediaContent | Content coded 'as original media content' in a MediaReview, considered in the context of how it was published or shared. For a VideoObject to be 'original': No evidence the footage has been misleadingly altered or manipulated, though it may contain false or misleading claims. For an ImageObject to be 'original': No evidence the image has been misleadingly altered or manipulated, though it may still contain false or misleading claims. For an ImageObject with embedded text to be 'original': No evidence the image has been misleadingly altered or manipulated, though it may still contain false or misleading claims. For an AudioObject to be 'original': No evidence the audio has been misleadingly altered or manipulated, though it may contain false or misleading claims. |
|
| OriginalShippingFees | OriginalShippingFees ... | |
| Osteopathic | A system of medicine focused on promoting the body's innate ability to heal itself. | |
| Otolaryngologic | A specific branch of medical science that is concerned with the ear, nose and throat and their respective disease states. | |
| OutOfStock | Indicates that the item is out of stock. | |
| OutletStore | An outlet store. | |
| OverviewHealthAspect | Overview of the content. Contains a summarized view of the topic with the most relevant information for an introduction. | |
| OwnershipInfo | A structured value providing information about when a certain organization or person owned a certain product. | |
| PET | Positron emission tomography imaging. | |
| PaidLeave | PaidLeave: this is a benefit for paid leave. | |
| PaintAction | The act of producing a painting, typically with paint and canvas as instruments. | |
| Painting | A painting. | |
| PalliativeProcedure | A medical procedure intended primarily for palliative purposes, aimed at relieving the symptoms of an underlying health condition. | |
| Paperback | Book format: Paperback. | |
| ParcelDelivery | The delivery of a parcel either via the postal service or a commercial service. | |
| ParcelService | A private parcel service as the delivery mode available for a certain offer. Commonly used values:
|
|
| ParentAudience | A set of characteristics describing parents, who can be interested in viewing some content. | |
| ParentalSupport | ParentalSupport: this is a benefit for parental support. | |
| Park | A park. | |
| ParkingFacility | A parking lot or other parking facility. | |
| ParkingMap | A parking map. | |
| PartiallyInForce | Indicates that parts of the legislation are in force, and parts are not. | |
| Pathology | A specific branch of medical science that is concerned with the study of the cause, origin and nature of a disease state, including its consequences as a result of manifestation of the disease. In clinical care, the term is used to designate a branch of medicine using laboratory tests to diagnose and determine the prognostic significance of illness. | |
| PathologyTest | A medical test performed by a laboratory that typically involves examination of a tissue sample by a pathologist. | |
| Patient | A patient is any person recipient of health care services. | |
| PatientExperienceHealthAspect | Content about the real life experience of patients or people that have lived a similar experience about the topic. May be forums, topics, Q-and-A and related material. | |
| PawnShop | A shop that will buy, or lend money against the security of, personal possessions. | |
| PayAction | An agent pays a price to a participant. | |
| PaymentAutomaticallyApplied | An automatic payment system is in place and will be used. | |
| PaymentCard | A payment method using a credit, debit, store or other card to associate the payment with an account. | |
| PaymentChargeSpecification | The costs of settling the payment using a particular payment method. | |
| PaymentComplete | The payment has been received and processed. | |
| PaymentDeclined | The payee received the payment, but it was declined for some reason. | |
| PaymentDue | The payment is due, but still within an acceptable time to be received. | |
| PaymentMethod | A payment method is a standardized procedure for transferring the monetary amount for a purchase. Payment methods are characterized by the legal and technical structures used, and by the organization or group carrying out the transaction. Commonly used values:
|
|
| PaymentPastDue | The payment is due and considered late. | |
| PaymentService | A Service to transfer funds from a person or organization to a beneficiary person or organization. | |
| PaymentStatusType | A specific payment status. For example, PaymentDue, PaymentComplete, etc. | |
| Pediatric | A specific branch of medical science that specializes in the care of infants, children and adolescents. | |
| PeopleAudience | A set of characteristics belonging to people, e.g. who compose an item's target audience. | |
| PercutaneousProcedure | A type of medical procedure that involves percutaneous techniques, where access to organs or tissue is achieved via needle-puncture of the skin. For example, catheter-based procedures like stent delivery. | |
| PerformAction | The act of participating in performance arts. | |
| PerformanceRole | A PerformanceRole is a Role that some entity places with regard to a theatrical performance, e.g. in a Movie, TVSeries etc. | |
| PerformingArtsTheater | A theater or other performing art center. | |
| PerformingGroup | A performance group, such as a band, an orchestra, or a circus. | |
| Periodical | A publication in any medium issued in successive parts bearing numerical or chronological designations and intended, such as a magazine, scholarly journal, or newspaper to continue indefinitely. See also blog post. |
|
| Permit | A permit issued by an organization, e.g. a parking pass. | |
| Person | A person (alive, dead, undead, or fictional). | |
| PetStore | A pet store. | |
| Pharmacy | A pharmacy or drugstore. | |
| PharmacySpecialty | The practice or art and science of preparing and dispensing drugs and medicines. | |
| Photograph | A photograph. | |
| PhotographAction | The act of capturing still images of objects using a camera. | |
| PhysicalActivity | Any bodily activity that enhances or maintains physical fitness and overall health and wellness. Includes activity that is part of daily living and routine, structured exercise, and exercise prescribed as part of a medical treatment or recovery plan. | |
| PhysicalActivityCategory | Categories of physical activity, organized by physiologic classification. | |
| PhysicalExam | A type of physical examination of a patient performed by a physician. | |
| PhysicalTherapy | A process of progressive physical care and rehabilitation aimed at improving a health condition. | |
| Physician | A doctor's office. | |
| Physiotherapy | The practice of treatment of disease, injury, or deformity by physical methods such as massage, heat treatment, and exercise rather than by drugs or surgery.. | |
| Place | Entities that have a somewhat fixed, physical extension. | |
| PlaceOfWorship | Place of worship, such as a church, synagogue, or mosque. | |
| PlaceboControlledTrial | A placebo-controlled trial design. | |
| PlanAction | The act of planning the execution of an event/task/action/reservation/plan to a future date. | |
| PlasticSurgery | A specific branch of medical science that pertains to therapeutic or cosmetic repair or re-formation of missing, injured or malformed tissues or body parts by manual and instrumental means. | |
| Play | A play is a form of literature, usually consisting of dialogue between characters, intended for theatrical performance rather than just reading. Note the peformance of a Play would be a TheaterEvent - the Play being the workPerformed. | |
| PlayAction | The act of playing/exercising/training/performing for enjoyment, leisure, recreation, Competition or exercise. Related actions:
|
|
| Playground | A playground. | |
| Plumber | A plumbing service. | |
| PodcastEpisode | A single episode of a podcast series. | |
| PodcastSeason | A single season of a podcast. Many podcasts do not break down into separate seasons. In that case, PodcastSeries should be used. | |
| PodcastSeries | A podcast is an episodic series of digital audio or video files which a user can download and listen to. | |
| Podiatric | Podiatry is the care of the human foot, especially the diagnosis and treatment of foot disorders. | |
| PoliceStation | A police station. | |
| Pond | A pond. | |
| PostOffice | A post office. | |
| PostalAddress | The mailing address. | |
| PostalCodeRangeSpecification | Indicates a range of postalcodes, usually defined as the set of valid codes between postalCodeBegin and postalCodeEnd, inclusively. | |
| Poster | A large, usually printed placard, bill, or announcement, often illustrated, that is posted to advertise or publicize something. | |
| PotentialActionStatus | A description of an action that is supported. | |
| PreOrder | Indicates that the item is available for pre-order. | |
| PreOrderAction | An agent orders a (not yet released) object/product/service to be delivered/sent. | |
| PreSale | Indicates that the item is available for ordering and delivery before general availability. | |
| PregnancyHealthAspect | Content discussing pregnancy-related aspects of a health topic. | |
| PrependAction | The act of inserting at the beginning if an ordered collection. | |
| Preschool | A preschool. | |
| PrescriptionOnly | Available by prescription only. | |
| PresentationDigitalDocument | A file containing slides or used for a presentation. | |
| PreventionHealthAspect | Information about actions or measures that can be taken to avoid getting the topic or reaching a critical situation related to the topic. | |
| PreventionIndication | An indication for preventing an underlying condition, symptom, etc. | |
| PriceComponentTypeEnumeration | Enumerates different price components that together make up the total price for an offered product. | |
| PriceSpecification | A structured value representing a price or price range. Typically, only the subclasses of this type are used for markup. It is recommended to use MonetaryAmount to describe independent amounts of money such as a salary, credit card limits, etc. | |
| PriceTypeEnumeration | Enumerates different price types, for example list price, invoice price, and sale price. | |
| PrimaryCare | The medical care by a physician, or other health-care professional, who is the patient's first contact with the health-care system and who may recommend a specialist if necessary. | |
| Prion | A prion is an infectious agent composed of protein in a misfolded form. | |
| Product | Any offered product or service. For example: a pair of shoes; a concert ticket; the rental of a car; a haircut; or an episode of a TV show streamed online. | |
| ProductCollection | A set of products (either ProductGroups or specific variants) that are listed together e.g. in an Offer. | |
| ProductGroup | A ProductGroup represents a group of Products that vary only in certain well-described ways, such as by size, color, material etc. While a ProductGroup itself is not directly offered for sale, the various varying products that it represents can be. The ProductGroup serves as a prototype or template, standing in for all of the products who have an isVariantOf relationship to it. As such, properties (including additional types) can be applied to the ProductGroup to represent characteristics shared by each of the (possibly very many) variants. Properties that reference a ProductGroup are not included in this mechanism; neither are the following specific properties variesBy, hasVariant, url. |
|
| ProductModel | A datasheet or vendor specification of a product (in the sense of a prototypical description). | |
| ProfessionalService | Original definition: "provider of professional services." The general ProfessionalService type for local businesses was deprecated due to confusion with Service. For reference, the types that it included were: Dentist, AccountingService, Attorney, Notary, as well as types for several kinds of HomeAndConstructionBusiness: Electrician, GeneralContractor, HousePainter, Locksmith, Plumber, RoofingContractor. LegalService was introduced as a more inclusive supertype of Attorney. |
|
| ProfilePage | Web page type: Profile page. | |
| PrognosisHealthAspect | Typical progression and happenings of life course of the topic. | |
| ProgramMembership | Used to describe membership in a loyalty programs (e.g. "StarAliance"), traveler clubs (e.g. "AAA"), purchase clubs ("Safeway Club"), etc. | |
| Project | An enterprise (potentially individual but typically collaborative), planned to achieve a particular aim. Use properties from Organization, subOrganization/parentOrganization to indicate project sub-structures. | |
| PronounceableText | Data type: PronounceableText. | |
| Property | A property, used to indicate attributes and relationships of some Thing; equivalent to rdf:Property. | |
| PropertyValue | A property-value pair, e.g. representing a feature of a product or place. Use the 'name' property for the name of the property. If there is an additional human-readable version of the value, put that into the 'description' property. Always use specific schema.org properties when a) they exist and b) you can populate them. Using PropertyValue as a substitute will typically not trigger the same effect as using the original, specific property. |
|
| PropertyValueSpecification | A Property value specification. | |
| Protozoa | Single-celled organism that causes an infection. | |
| Psychiatric | A specific branch of medical science that is concerned with the study, treatment, and prevention of mental illness, using both medical and psychological therapies. | |
| PsychologicalTreatment | A process of care relying upon counseling, dialogue and communication aimed at improving a mental health condition without use of drugs. | |
| PublicHealth | Branch of medicine that pertains to the health services to improve and protect community health, especially epidemiology, sanitation, immunization, and preventive medicine. | |
| PublicHolidays | This stands for any day that is a public holiday; it is a placeholder for all official public holidays in some particular location. While not technically a "day of the week", it can be used with OpeningHoursSpecification. In the context of an opening hours specification it can be used to indicate opening hours on public holidays, overriding general opening hours for the day of the week on which a public holiday occurs. | |
| PublicSwimmingPool | A public swimming pool. | |
| PublicToilet | A public toilet is a room or small building containing one or more toilets (and possibly also urinals) which is available for use by the general public, or by customers or employees of certain businesses. | |
| PublicationEvent | A PublicationEvent corresponds indifferently to the event of publication for a CreativeWork of any type e.g. a broadcast event, an on-demand event, a book/journal publication via a variety of delivery media. | |
| PublicationIssue | A part of a successively published publication such as a periodical or publication volume, often numbered, usually containing a grouping of works such as articles. See also blog post. |
|
| PublicationVolume | A part of a successively published publication such as a periodical or multi-volume work, often numbered. It may represent a time span, such as a year. See also blog post. |
|
| Pulmonary | A specific branch of medical science that pertains to the study of the respiratory system and its respective disease states. | |
| QAPage | A QAPage is a WebPage focussed on a specific Question and its Answer(s), e.g. in a question answering site or documenting Frequently Asked Questions (FAQs). | |
| QualitativeValue | A predefined value for a product characteristic, e.g. the power cord plug type 'US' or the garment sizes 'S', 'M', 'L', and 'XL'. | |
| QuantitativeValue | A point value or interval for product characteristics and other purposes. | |
| QuantitativeValueDistribution | A statistical distribution of values. | |
| Quantity | Quantities such as distance, time, mass, weight, etc. Particular instances of say Mass are entities like '3 Kg' or '4 milligrams'. | |
| Question | A specific question - e.g. from a user seeking answers online, or collected in a Frequently Asked Questions (FAQ) document. | |
| Quiz | Quiz: A test of knowledge, skills and abilities. | |
| Quotation | A quotation. Often but not necessarily from some written work, attributable to a real world author and - if associated with a fictional character - to any fictional Person. Use isBasedOn to link to source/origin. The recordedIn property can be used to reference a Quotation from an Event. | |
| QuoteAction | An agent quotes/estimates/appraises an object/product/service with a price at a location/store. | |
| RVPark | A place offering space for "Recreational Vehicles", Caravans, mobile homes and the like. | |
| RadiationTherapy | A process of care using radiation aimed at improving a health condition. | |
| RadioBroadcastService | A delivery service through which radio content is provided via broadcast over the air or online. | |
| RadioChannel | A unique instance of a radio BroadcastService on a CableOrSatelliteService lineup. | |
| RadioClip | A short radio program or a segment/part of a radio program. | |
| RadioEpisode | A radio episode which can be part of a series or season. | |
| RadioSeason | Season dedicated to radio broadcast and associated online delivery. | |
| RadioSeries | CreativeWorkSeries dedicated to radio broadcast and associated online delivery. | |
| RadioStation | A radio station. | |
| Radiography | Radiography is an imaging technique that uses electromagnetic radiation other than visible light, especially X-rays, to view the internal structure of a non-uniformly composed and opaque object such as the human body. | |
| RandomizedTrial | A randomized trial design. | |
| Rating | A rating is an evaluation on a numeric scale, such as 1 to 5 stars. | |
| ReactAction | The act of responding instinctively and emotionally to an object, expressing a sentiment. | |
| ReadAction | The act of consuming written content. | |
| ReadPermission | Permission to read or view the document. | |
| RealEstateAgent | A real-estate agent. | |
| RealEstateListing | A RealEstateListing is a listing that describes one or more real-estate Offers (whose businessFunction is typically to lease out, or to sell). The RealEstateListing type itself represents the overall listing, as manifested in some WebPage. | |
| RearWheelDriveConfiguration | Real-wheel drive is a transmission layout where the engine drives the rear wheels. | |
| ReceiveAction | The act of physically/electronically taking delivery of an object that has been transferred from an origin to a destination. Reciprocal of SendAction. Related actions:
|
|
| Recipe | A recipe. For dietary restrictions covered by the recipe, a few common restrictions are enumerated via suitableForDiet. The keywords property can also be used to add more detail. | |
| Recommendation | Recommendation is a type of Review that suggests or proposes something as the best option or best course of action. Recommendations may be for products or services, or other concrete things, as in the case of a ranked list or product guide. A Guide may list multiple recommendations for different categories. For example, in a Guide about which TVs to buy, the author may have several Recommendations. | |
| RecommendedDoseSchedule | A recommended dosing schedule for a drug or supplement as prescribed or recommended by an authority or by the drug/supplement's manufacturer. Capture the recommending authority in the recognizingAuthority property of MedicalEntity. | |
| Recruiting | Recruiting participants. | |
| RecyclingCenter | A recycling center. | |
| RefundTypeEnumeration | RefundTypeEnumeration enumerates several kinds of product return refund types. | |
| RefurbishedCondition | Indicates that the item is refurbished. | |
| RegisterAction | The act of registering to be a user of a service, product or web page. Related actions:
|
|
| Registry | A registry-based study design. | |
| ReimbursementCap | The drug's cost represents the maximum reimbursement paid by an insurer for the drug. | |
| RejectAction | The act of rejecting to/adopting an object. Related actions:
|
|
| RelatedTopicsHealthAspect | Other prominent or relevant topics tied to the main topic. | |
| RemixAlbum | RemixAlbum. | |
| Renal | A specific branch of medical science that pertains to the study of the kidneys and its respective disease states. | |
| RentAction | The act of giving money in return for temporary use, but not ownership, of an object such as a vehicle or property. For example, an agent rents a property from a landlord in exchange for a periodic payment. | |
| RentalCarReservation | A reservation for a rental car. Note: This type is for information about actual reservations, e.g. in confirmation emails or HTML pages with individual confirmations of reservations. |
|
| RentalVehicleUsage | Indicates the usage of the vehicle as a rental car. | |
| RepaymentSpecification | A structured value representing repayment. | |
| ReplaceAction | The act of editing a recipient by replacing an old object with a new object. | |
| ReplyAction | The act of responding to a question/message asked/sent by the object. Related to AskAction Related actions:
|
|
| Report | A Report generated by governmental or non-governmental organization. | |
| ReportageNewsArticle | The ReportageNewsArticle type is a subtype of NewsArticle representing
news articles which are the result of journalistic news reporting conventions. In practice many news publishers produce a wide variety of article types, many of which might be considered a NewsArticle but not a ReportageNewsArticle. For example, opinion pieces, reviews, analysis, sponsored or satirical articles, or articles that combine several of these elements. The ReportageNewsArticle type is based on a stricter ideal for "news" as a work of journalism, with articles based on factual information either observed or verified by the author, or reported and verified from knowledgeable sources. This often includes perspectives from multiple viewpoints on a particular issue (distinguishing news reports from public relations or propaganda). News reports in the ReportageNewsArticle sense de-emphasize the opinion of the author, with commentary and value judgements typically expressed elsewhere. A ReportageNewsArticle which goes deeper into analysis can also be marked with an additional type of AnalysisNewsArticle. |
|
| ReportedDoseSchedule | A patient-reported or observed dosing schedule for a drug or supplement. | |
| ResearchProject | A Research project. | |
| Researcher | Researchers. | |
| Reservation | Describes a reservation for travel, dining or an event. Some reservations require tickets. Note: This type is for information about actual reservations, e.g. in confirmation emails or HTML pages with individual confirmations of reservations. For offers of tickets, restaurant reservations, flights, or rental cars, use Offer. |
|
| ReservationCancelled | The status for a previously confirmed reservation that is now cancelled. | |
| ReservationConfirmed | The status of a confirmed reservation. | |
| ReservationHold | The status of a reservation on hold pending an update like credit card number or flight changes. | |
| ReservationPackage | A group of multiple reservations with common values for all sub-reservations. | |
| ReservationPending | The status of a reservation when a request has been sent, but not confirmed. | |
| ReservationStatusType | Enumerated status values for Reservation. | |
| ReserveAction | Reserving a concrete object. Related actions:
|
|
| Reservoir | A reservoir of water, typically an artificially created lake, like the Lake Kariba reservoir. | |
| Residence | The place where a person lives. | |
| Resort | A resort is a place used for relaxation or recreation, attracting visitors for holidays or vacations. Resorts are places, towns or sometimes commercial establishment operated by a single company (Source: Wikipedia, the free encyclopedia, see http://en.wikipedia.org/wiki/Resort).
See also the dedicated document on the use of schema.org for marking up hotels and other forms of accommodations. |
|
| RespiratoryTherapy | The therapy that is concerned with the maintenance or improvement of respiratory function (as in patients with pulmonary disease). | |
| Restaurant | A restaurant. | |
| RestockingFees | RestockingFees ... | |
| RestrictedDiet | A diet restricted to certain foods or preparations for cultural, religious, health or lifestyle reasons. | |
| ResultsAvailable | Results are available. | |
| ResultsNotAvailable | Results are not available. | |
| ResumeAction | The act of resuming a device or application which was formerly paused (e.g. resume music playback or resume a timer). | |
| Retail | The drug's cost represents the retail cost of the drug. | |
| ReturnAction | The act of returning to the origin that which was previously received (concrete objects) or taken (ownership). | |
| ReturnFeesEnumeration | ReturnFeesEnumeration expresses policies for return fees. | |
| ReturnShippingFees | ReturnShippingFees ... | |
| Review | A review of an item - for example, of a restaurant, movie, or store. | |
| ReviewAction | The act of producing a balanced opinion about the object for an audience. An agent reviews an object with participants resulting in a review. | |
| ReviewNewsArticle | A NewsArticle and CriticReview providing a professional critic's assessment of a service, product, performance, or artistic or literary work. | |
| Rheumatologic | A specific branch of medical science that deals with the study and treatment of rheumatic, autoimmune or joint diseases. | |
| RightHandDriving | The steering position is on the right side of the vehicle (viewed from the main direction of driving). | |
| RisksOrComplicationsHealthAspect | Information about the risk factors and possible complications that may follow a topic. | |
| RiverBodyOfWater | A river (for example, the broad majestic Shannon). | |
| Role | Represents additional information about a relationship or property. For example a Role can be used to say that a 'member' role linking some SportsTeam to a player occurred during a particular time period. Or that a Person's 'actor' role in a Movie was for some particular characterName. Such properties can be attached to a Role entity, which is then associated with the main entities using ordinary properties like 'member' or 'actor'. See also blog post. |
|
| RoofingContractor | A roofing contractor. | |
| Room | A room is a distinguishable space within a structure, usually separated from other spaces by interior walls. (Source: Wikipedia, the free encyclopedia, see http://en.wikipedia.org/wiki/Room).
See also the dedicated document on the use of schema.org for marking up hotels and other forms of accommodations. |
|
| RsvpAction | The act of notifying an event organizer as to whether you expect to attend the event. | |
| RsvpResponseMaybe | The invitee may or may not attend. | |
| RsvpResponseNo | The invitee will not attend. | |
| RsvpResponseType | RsvpResponseType is an enumeration type whose instances represent responding to an RSVP request. | |
| RsvpResponseYes | The invitee will attend. | |
| SRP | Represents the suggested retail price ("SRP") of an offered product. | |
| SafetyHealthAspect | Content about the safety-related aspects of a health topic. | |
| SaleEvent | Event type: Sales event. | |
| SalePrice | Represents a sale price (usually active for a limited period) of an offered product. | |
| SatireOrParodyContent | Content coded 'satire or content' in a MediaReview, considered in the context of how it was published or shared. For a VideoObject to be 'satire or parody content': A video that was created as political or humorous commentary and is presented in that context. (Reshares of satire/parody content that do not include relevant context are more likely to fall under the “missing context” rating.) For an ImageObject to be 'satire or parody content': An image that was created as political or humorous commentary and is presented in that context. (Reshares of satire/parody content that do not include relevant context are more likely to fall under the “missing context” rating.) For an ImageObject with embedded text to be 'satire or parody content': An image that was created as political or humorous commentary and is presented in that context. (Reshares of satire/parody content that do not include relevant context are more likely to fall under the “missing context” rating.) For an AudioObject to be 'satire or parody content': Audio that was created as political or humorous commentary and is presented in that context. (Reshares of satire/parody content that do not include relevant context are more likely to fall under the “missing context” rating.) |
|
| SatiricalArticle | An Article whose content is primarily [satirical] in nature, i.e. unlikely to be literally true. A satirical article is sometimes but not necessarily also a NewsArticle. ScholarlyArticles are also sometimes satirized. | |
| Saturday | The day of the week between Friday and Sunday. | |
| Schedule | A schedule defines a repeating time period used to describe a regularly occurring Event. At a minimum a schedule will specify repeatFrequency which describes the interval between occurences of the event. Additional information can be provided to specify the schedule more precisely. This includes identifying the day(s) of the week or month when the recurring event will take place, in addition to its start and end time. Schedules may also have start and end dates to indicate when they are active, e.g. to define a limited calendar of events. | |
| ScheduleAction | Scheduling future actions, events, or tasks. Related actions:
|
|
| ScholarlyArticle | A scholarly article. | |
| School | A school. | |
| SchoolDistrict | A School District is an administrative area for the administration of schools. | |
| ScreeningEvent | A screening of a movie or other video. | |
| ScreeningHealthAspect | Content about how to screen or further filter a topic. | |
| Sculpture | A piece of sculpture. | |
| SeaBodyOfWater | A sea (for example, the Caspian sea). | |
| SearchAction | The act of searching for an object. Related actions:
|
|
| SearchResultsPage | Web page type: Search results page. | |
| Season | A media season e.g. tv, radio, video game etc. | |
| Seat | Used to describe a seat, such as a reserved seat in an event reservation. | |
| SeatingMap | A seating map. | |
| SeeDoctorHealthAspect | Information about questions that may be asked, when to see a professional, measures before seeing a doctor or content about the first consultation. | |
| SeekToAction | This is the Action of navigating to a specific startOffset timestamp within a VideoObject, typically represented with a URL template structure. | |
| SelfCareHealthAspect | Self care actions or measures that can be taken to sooth, health or avoid a topic. This may be carried at home and can be carried/managed by the person itself. | |
| SelfStorage | A self-storage facility. | |
| SellAction | The act of taking money from a buyer in exchange for goods or services rendered. An agent sells an object, product, or service to a buyer for a price. Reciprocal of BuyAction. | |
| SendAction | The act of physically/electronically dispatching an object for transfer from an origin to a destination.Related actions:
|
|
| Series | A Series in schema.org is a group of related items, typically but not necessarily of the same kind. See also CreativeWorkSeries, EventSeries. | |
| Service | A service provided by an organization, e.g. delivery service, print services, etc. | |
| ServiceChannel | A means for accessing a service, e.g. a government office location, web site, or phone number. | |
| ShareAction | The act of distributing content to people for their amusement or edification. | |
| SheetMusic | Printed music, as opposed to performed or recorded music. | |
| ShippingDeliveryTime | ShippingDeliveryTime provides various pieces of information about delivery times for shipping. | |
| ShippingRateSettings | A ShippingRateSettings represents re-usable pieces of shipping information. It is designed for publication on an URL that may be referenced via the shippingSettingsLink property of an OfferShippingDetails. Several occurrences can be published, distinguished and matched (i.e. identified/referenced) by their different values for shippingLabel. | |
| ShoeStore | A shoe store. | |
| ShoppingCenter | A shopping center or mall. | |
| ShortStory | Short story or tale. A brief work of literature, usually written in narrative prose. | |
| SideEffectsHealthAspect | Side effects that can be observed from the usage of the topic. | |
| SingleBlindedTrial | A trial design in which the researcher knows which treatment the patient was randomly assigned to but the patient does not. | |
| SingleCenterTrial | A trial that takes place at a single center. | |
| SingleFamilyResidence | Residence type: Single-family home. | |
| SinglePlayer | Play mode: SinglePlayer. Which is played by a lone player. | |
| SingleRelease | SingleRelease. | |
| SiteNavigationElement | A navigation element of the page. | |
| SizeGroupEnumeration | Enumerates common size groups for various product categories. | |
| SizeSpecification | Size related properties of a product, typically a size code (name) and optionally a sizeSystem, sizeGroup, and product measurements (hasMeasurement). In addition, the intended audience can be defined through suggestedAge, suggestedGender, and suggested body measurements (suggestedMeasurement). | |
| SizeSystemEnumeration | Enumerates common size systems for different categories of products, for example "EN-13402" or "UK" for wearables or "Imperial" for screws. | |
| SizeSystemImperial | Imperial size system. | |
| SizeSystemMetric | Metric size system. | |
| SkiResort | A ski resort. | |
| Skin | Skin assessment with clinical examination. | |
| SocialEvent | Event type: Social event. | |
| SocialMediaPosting | A post to a social media platform, including blog posts, tweets, Facebook posts, etc. | |
| SoftwareApplication | A software application. | |
| SoftwareSourceCode | Computer programming source code. Example: Full (compile ready) solutions, code snippet samples, scripts, templates. | |
| SoldOut | Indicates that the item has sold out. | |
| SolveMathAction | The action that takes in a math expression and directs users to a page potentially capable of solving/simplifying that expression. | |
| SomeProducts | A placeholder for multiple similar products of the same kind. | |
| SoundtrackAlbum | SoundtrackAlbum. | |
| SpeakableSpecification | A SpeakableSpecification indicates (typically via xpath or cssSelector) sections of a document that are highlighted as particularly speakable. Instances of this type are expected to be used primarily as values of the speakable property. | |
| SpecialAnnouncement | A SpecialAnnouncement combines a simple date-stamped textual information update
with contextualized Web links and other structured data. It represents an information update made by a
locally-oriented organization, for example schools, pharmacies, healthcare providers, community groups, police,
local government. For work in progress guidelines on Coronavirus-related markup see this doc. The motivating scenario for SpecialAnnouncement is the Coronavirus pandemic, and the initial vocabulary is oriented to this urgent situation. Schema.org expect to improve the markup iteratively as it is deployed and as feedback emerges from use. In addition to our usual Github entry, feedback comments can also be provided in this document. While this schema is designed to communicate urgent crisis-related information, it is not the same as an emergency warning technology like CAP, although there may be overlaps. The intent is to cover the kinds of everyday practical information being posted to existing websites during an emergency situation. Several kinds of information can be provided: We encourage the provision of "name", "text", "datePosted", "expires" (if appropriate), "category" and "url" as a simple baseline. It is important to provide a value for "category" where possible, most ideally as a well known URL from Wikipedia or Wikidata. In the case of the 2019-2020 Coronavirus pandemic, this should be "https://en.wikipedia.org/w/index.php?title=2019-20_coronavirus_pandemic" or "https://www.wikidata.org/wiki/Q81068910". For many of the possible properties, values can either be simple links or an inline description, depending on whether a summary is available. For a link, provide just the URL of the appropriate page as the property's value. For an inline description, use a WebContent type, and provide the url as a property of that, alongside at least a simple "text" summary of the page. It is unlikely that a single SpecialAnnouncement will need all of the possible properties simultaneously. We expect that in many cases the page referenced might contain more specialized structured data, e.g. contact info, openingHours, Event, FAQPage etc. By linking to those pages from a SpecialAnnouncement you can help make it clearer that the events are related to the situation (e.g. Coronavirus) indicated by the category property of the SpecialAnnouncement. Many SpecialAnnouncements will relate to particular regions and to identifiable local organizations. Use spatialCoverage for the region, and announcementLocation to indicate specific LocalBusinesses and CivicStructures. If the announcement affects both a particular region and a specific location (for example, a library closure that serves an entire region), use both spatialCoverage and announcementLocation. The about property can be used to indicate entities that are the focus of the announcement. We now recommend using about only for representing non-location entities (e.g. a Course or a RadioStation). For places, use announcementLocation and spatialCoverage. Consumers of this markup should be aware that the initial design encouraged the use of /about for locations too. The basic content of SpecialAnnouncement is similar to that of an RSS or Atom feed. For publishers without such feeds, basic feed-like information can be shared by posting SpecialAnnouncement updates in a page, e.g. using JSON-LD. For sites with Atom/RSS functionality, you can point to a feed with the webFeed property. This can be a simple URL, or an inline DataFeed object, with encodingFormat providing media type information e.g. "application/rss+xml" or "application/atom+xml". |
|
| Specialty | Any branch of a field in which people typically develop specific expertise, usually after significant study, time, and effort. | |
| SpeechPathology | The scientific study and treatment of defects, disorders, and malfunctions of speech and voice, as stuttering, lisping, or lalling, and of language disturbances, as aphasia or delayed language acquisition. | |
| SpokenWordAlbum | SpokenWordAlbum. | |
| SportingGoodsStore | A sporting goods store. | |
| SportsActivityLocation | A sports location, such as a playing field. | |
| SportsClub | A sports club. | |
| SportsEvent | Event type: Sports event. | |
| SportsOrganization | Represents the collection of all sports organizations, including sports teams, governing bodies, and sports associations. | |
| SportsTeam | Organization: Sports team. | |
| SpreadsheetDigitalDocument | A spreadsheet file. | |
| StadiumOrArena | A stadium. | |
| StagedContent | Content coded 'staged content' in a MediaReview, considered in the context of how it was published or shared. For a VideoObject to be 'staged content': A video that has been created using actors or similarly contrived. For an ImageObject to be 'staged content': An image that was created using actors or similarly contrived, such as a screenshot of a fake tweet. For an ImageObject with embedded text to be 'staged content': An image that was created using actors or similarly contrived, such as a screenshot of a fake tweet. For an AudioObject to be 'staged content': Audio that has been created using actors or similarly contrived. |
|
| StagesHealthAspect | Stages that can be observed from a topic. | |
| State | A state or province of a country. | |
| StatisticalPopulation | A StatisticalPopulation is a set of instances of a certain given type that satisfy some set of constraints. The property populationType is used to specify the type. Any property that can be used on instances of that type can appear on the statistical population. For example, a StatisticalPopulation representing all Persons with a homeLocation of East Podunk California, would be described by applying the appropriate homeLocation and populationType properties to a StatisticalPopulation item that stands for that set of people. The properties numConstraints and constrainingProperty are used to specify which of the populations properties are used to specify the population. Note that the sense of "population" used here is the general sense of a statistical population, and does not imply that the population consists of people. For example, a populationType of Event or NewsArticle could be used. See also Observation, and the data and datasets overview for more details. | |
| StatusEnumeration | Lists or enumerations dealing with status types. | |
| SteeringPositionValue | A value indicating a steering position. | |
| Store | A retail good store. | |
| StoreCreditRefund | A StoreCreditRefund ... | |
| StrengthTraining | Physical activity that is engaged in to improve muscle and bone strength. Also referred to as resistance training. | |
| StructuredValue | Structured values are used when the value of a property has a more complex structure than simply being a textual value or a reference to another thing. | |
| StudioAlbum | StudioAlbum. | |
| SubscribeAction | The act of forming a personal connection with someone/something (object) unidirectionally/asymmetrically to get updates pushed to. Related actions:
|
|
| Subscription | Represents the subscription pricing component of the total price for an offered product. | |
| Substance | Any matter of defined composition that has discrete existence, whose origin may be biological, mineral or chemical. | |
| SubwayStation | A subway station. | |
| Suite | A suite in a hotel or other public accommodation, denotes a class of luxury accommodations, the key feature of which is multiple rooms (Source: Wikipedia, the free encyclopedia, see http://en.wikipedia.org/wiki/Suite_(hotel)).
See also the dedicated document on the use of schema.org for marking up hotels and other forms of accommodations. |
|
| Sunday | The day of the week between Saturday and Monday. | |
| SuperficialAnatomy | Anatomical features that can be observed by sight (without dissection), including the form and proportions of the human body as well as surface landmarks that correspond to deeper subcutaneous structures. Superficial anatomy plays an important role in sports medicine, phlebotomy, and other medical specialties as underlying anatomical structures can be identified through surface palpation. For example, during back surgery, superficial anatomy can be used to palpate and count vertebrae to find the site of incision. Or in phlebotomy, superficial anatomy can be used to locate an underlying vein; for example, the median cubital vein can be located by palpating the borders of the cubital fossa (such as the epicondyles of the humerus) and then looking for the superficial signs of the vein, such as size, prominence, ability to refill after depression, and feel of surrounding tissue support. As another example, in a subluxation (dislocation) of the glenohumeral joint, the bony structure becomes pronounced with the deltoid muscle failing to cover the glenohumeral joint allowing the edges of the scapula to be superficially visible. Here, the superficial anatomy is the visible edges of the scapula, implying the underlying dislocation of the joint (the related anatomical structure). | |
| Surgical | A specific branch of medical science that pertains to treating diseases, injuries and deformities by manual and instrumental means. | |
| SurgicalProcedure | A medical procedure involving an incision with instruments; performed for diagnose, or therapeutic purposes. | |
| SuspendAction | The act of momentarily pausing a device or application (e.g. pause music playback or pause a timer). | |
| Suspended | Suspended. | |
| SymptomsHealthAspect | Symptoms or related symptoms of a Topic. | |
| Synagogue | A synagogue. | |
| TVClip | A short TV program or a segment/part of a TV program. | |
| TVEpisode | A TV episode which can be part of a series or season. | |
| TVSeason | Season dedicated to TV broadcast and associated online delivery. | |
| TVSeries | CreativeWorkSeries dedicated to TV broadcast and associated online delivery. | |
| Table | A table on a Web page. | |
| TakeAction | The act of gaining ownership of an object from an origin. Reciprocal of GiveAction. Related actions:
|
|
| TattooParlor | A tattoo parlor. | |
| Taxi | A taxi. | |
| TaxiReservation | A reservation for a taxi. Note: This type is for information about actual reservations, e.g. in confirmation emails or HTML pages with individual confirmations of reservations. For offers of tickets, use Offer. |
|
| TaxiService | A service for a vehicle for hire with a driver for local travel. Fares are usually calculated based on distance traveled. | |
| TaxiStand | A taxi stand. | |
| TaxiVehicleUsage | Indicates the usage of the car as a taxi. | |
| TechArticle | A technical article - Example: How-to (task) topics, step-by-step, procedural troubleshooting, specifications, etc. | |
| TelevisionChannel | A unique instance of a television BroadcastService on a CableOrSatelliteService lineup. | |
| TelevisionStation | A television station. | |
| TennisComplex | A tennis complex. | |
| Terminated | Terminated. | |
| Text | Data type: Text. | |
| TextDigitalDocument | A file composed primarily of text. | |
| TheaterEvent | Event type: Theater performance. | |
| TheaterGroup | A theater group or company, for example, the Royal Shakespeare Company or Druid Theatre. | |
| Therapeutic | A medical device used for therapeutic purposes. | |
| TherapeuticProcedure | A medical procedure intended primarily for therapeutic purposes, aimed at improving a health condition. | |
| Thesis | A thesis or dissertation document submitted in support of candidature for an academic degree or professional qualification. | |
| Thing | The most generic type of item. | |
| Throat | Throat assessment with clinical examination. | |
| Thursday | The day of the week between Wednesday and Friday. | |
| Ticket | Used to describe a ticket to an event, a flight, a bus ride, etc. | |
| TieAction | The act of reaching a draw in a competitive activity. | |
| Time | A point in time recurring on multiple days in the form hh:mm:ss[Z|(+|-)hh:mm] (see XML schema for details). | |
| TipAction | The act of giving money voluntarily to a beneficiary in recognition of services rendered. | |
| TireShop | A tire shop. | |
| TollFree | The associated telephone number is toll free. | |
| TouristAttraction | A tourist attraction. In principle any Thing can be a TouristAttraction, from a Mountain and LandmarksOrHistoricalBuildings to a LocalBusiness. This Type can be used on its own to describe a general TouristAttraction, or be used as an additionalType to add tourist attraction properties to any other type. (See examples below) | |
| TouristDestination | A tourist destination. In principle any Place can be a TouristDestination from a City, Region or Country to an AmusementPark or Hotel. This Type can be used on its own to describe a general TouristDestination, or be used as an additionalType to add tourist relevant properties to any other Place. A TouristDestination is defined as a Place that contains, or is colocated with, one or more TouristAttractions, often linked by a similar theme or interest to a particular touristType. The UNWTO defines Destination (main destination of a tourism trip) as the place visited that is central to the decision to take the trip. (See examples below). | |
| TouristInformationCenter | A tourist information center. | |
| TouristTrip | A tourist trip. A created itinerary of visits to one or more places of interest (TouristAttraction/TouristDestination) often linked by a similar theme, geographic area, or interest to a particular touristType. The UNWTO defines tourism trip as the Trip taken by visitors. (See examples below). | |
| Toxicologic | A specific branch of medical science that is concerned with poisons, their nature, effects and detection and involved in the treatment of poisoning. | |
| ToyStore | A toy store. | |
| TrackAction | An agent tracks an object for updates. Related actions:
|
|
| TradeAction | The act of participating in an exchange of goods and services for monetary compensation. An agent trades an object, product or service with a participant in exchange for a one time or periodic payment. | |
| TraditionalChinese | A system of medicine based on common theoretical concepts that originated in China and evolved over thousands of years, that uses herbs, acupuncture, exercise, massage, dietary therapy, and other methods to treat a wide range of conditions. | |
| TrainReservation | A reservation for train travel. Note: This type is for information about actual reservations, e.g. in confirmation emails or HTML pages with individual confirmations of reservations. For offers of tickets, use Offer. |
|
| TrainStation | A train station. | |
| TrainTrip | A trip on a commercial train line. | |
| TransferAction | The act of transferring/moving (abstract or concrete) animate or inanimate objects from one place to another. | |
| TransformedContent | Content coded 'transformed content' in a MediaReview, considered in the context of how it was published or shared. For a VideoObject to be 'transformed content': or all of the video has been manipulated to transform the footage itself. This category includes using tools like the Adobe Suite to change the speed of the video, add or remove visual elements or dub audio. Deepfakes are also a subset of transformation. For an ImageObject to be transformed content': Adding or deleting visual elements to give the image a different meaning with the intention to mislead. For an ImageObject with embedded text to be 'transformed content': Adding or deleting visual elements to give the image a different meaning with the intention to mislead. For an AudioObject to be 'transformed content': Part or all of the audio has been manipulated to alter the words or sounds, or the audio has been synthetically generated, such as to create a sound-alike voice. |
|
| TransitMap | A transit map. | |
| TravelAction | The act of traveling from an fromLocation to a destination by a specified mode of transport, optionally with participants. | |
| TravelAgency | A travel agency. | |
| TreatmentIndication | An indication for treating an underlying condition, symptom, etc. | |
| TreatmentsHealthAspect | Treatments or related therapies for a Topic. | |
| Trip | A trip or journey. An itinerary of visits to one or more places. | |
| TripleBlindedTrial | A trial design in which neither the researcher, the person administering the therapy nor the patient knows the details of the treatment the patient was randomly assigned to. | |
| True | The boolean value true. | |
| Tuesday | The day of the week between Monday and Wednesday. | |
| TypeAndQuantityNode | A structured value indicating the quantity, unit of measurement, and business function of goods included in a bundle offer. | |
| TypesHealthAspect | Categorization and other types related to a topic. | |
| UKNonprofitType | UKNonprofitType: Non-profit organization type originating from the United Kingdom. | |
| UKTrust | UKTrust: Non-profit type referring to a UK trust. | |
| URL | Data type: URL. | |
| USNonprofitType | USNonprofitType: Non-profit organization type originating from the United States. | |
| Ultrasound | Ultrasound imaging. | |
| UnRegisterAction | The act of un-registering from a service. Related actions:
|
|
| UnemploymentSupport | UnemploymentSupport: this is a benefit for unemployment support. | |
| UnincorporatedAssociationCharity | UnincorporatedAssociationCharity: Non-profit type referring to a charitable company that is not incorporated (UK). | |
| UnitPriceSpecification | The price asked for a given offer by the respective organization or person. | |
| UnofficialLegalValue | Indicates that a document has no particular or special standing (e.g. a republication of a law by a private publisher). | |
| UpdateAction | The act of managing by changing/editing the state of the object. | |
| Urologic | A specific branch of medical science that is concerned with the diagnosis and treatment of diseases pertaining to the urinary tract and the urogenital system. | |
| UsageOrScheduleHealthAspect | Content about how, when, frequency and dosage of a topic. | |
| UseAction | The act of applying an object to its intended purpose. | |
| UsedCondition | Indicates that the item is used. | |
| UserBlocks | UserInteraction and its subtypes is an old way of talking about users interacting with pages. It is generally better to use Action-based vocabulary, alongside types such as Comment. | |
| UserCheckins | UserInteraction and its subtypes is an old way of talking about users interacting with pages. It is generally better to use Action-based vocabulary, alongside types such as Comment. | |
| UserComments | UserInteraction and its subtypes is an old way of talking about users interacting with pages. It is generally better to use Action-based vocabulary, alongside types such as Comment. | |
| UserDownloads | UserInteraction and its subtypes is an old way of talking about users interacting with pages. It is generally better to use Action-based vocabulary, alongside types such as Comment. | |
| UserInteraction | UserInteraction and its subtypes is an old way of talking about users interacting with pages. It is generally better to use Action-based vocabulary, alongside types such as Comment. | |
| UserLikes | UserInteraction and its subtypes is an old way of talking about users interacting with pages. It is generally better to use Action-based vocabulary, alongside types such as Comment. | |
| UserPageVisits | UserInteraction and its subtypes is an old way of talking about users interacting with pages. It is generally better to use Action-based vocabulary, alongside types such as Comment. | |
| UserPlays | UserInteraction and its subtypes is an old way of talking about users interacting with pages. It is generally better to use Action-based vocabulary, alongside types such as Comment. | |
| UserPlusOnes | UserInteraction and its subtypes is an old way of talking about users interacting with pages. It is generally better to use Action-based vocabulary, alongside types such as Comment. | |
| UserReview | A review created by an end-user (e.g. consumer, purchaser, attendee etc.), in contrast with CriticReview. | |
| UserTweets | UserInteraction and its subtypes is an old way of talking about users interacting with pages. It is generally better to use Action-based vocabulary, alongside types such as Comment. | |
| VeganDiet | A diet exclusive of all animal products. | |
| VegetarianDiet | A diet exclusive of animal meat. | |
| Vehicle | A vehicle is a device that is designed or used to transport people or cargo over land, water, air, or through space. | |
| Vein | A type of blood vessel that specifically carries blood to the heart. | |
| VenueMap | A venue map (e.g. for malls, auditoriums, museums, etc.). | |
| Vessel | A component of the human body circulatory system comprised of an intricate network of hollow tubes that transport blood throughout the entire body. | |
| VeterinaryCare | A vet's office. | |
| VideoGallery | Web page type: Video gallery page. | |
| VideoGame | A video game is an electronic game that involves human interaction with a user interface to generate visual feedback on a video device. | |
| VideoGameClip | A short segment/part of a video game. | |
| VideoGameSeries | A video game series. | |
| VideoObject | A video file. | |
| ViewAction | The act of consuming static visual content. | |
| VinylFormat | VinylFormat. | |
| VirtualLocation | An online or virtual location for attending events. For example, one may attend an online seminar or educational event. While a virtual location may be used as the location of an event, virtual locations should not be confused with physical locations in the real world. | |
| Virus | Pathogenic virus that causes viral infection. | |
| VisualArtsEvent | Event type: Visual arts event. | |
| VisualArtwork | A work of art that is primarily visual in character. | |
| VitalSign | Vital signs are measures of various physiological functions in order to assess the most basic body functions. | |
| Volcano | A volcano, like Fuji san. | |
| VoteAction | The act of expressing a preference from a fixed/finite/structured set of choices/options. | |
| WPAdBlock | An advertising section of the page. | |
| WPFooter | The footer section of the page. | |
| WPHeader | The header section of the page. | |
| WPSideBar | A sidebar section of the page. | |
| WantAction | The act of expressing a desire about the object. An agent wants an object. | |
| WarrantyPromise | A structured value representing the duration and scope of services that will be provided to a customer free of charge in case of a defect or malfunction of a product. | |
| WarrantyScope | A range of of services that will be provided to a customer free of charge in case of a defect or malfunction of a product. Commonly used values:
|
|
| WatchAction | The act of consuming dynamic/moving visual content. | |
| Waterfall | A waterfall, like Niagara. | |
| WearAction | The act of dressing oneself in clothing. | |
| WearableMeasurementBack | Measurement of the back section, for example of a jacket | |
| WearableMeasurementChestOrBust | Measurement of the chest/bust section, for example of a suit | |
| WearableMeasurementCollar | Measurement of the collar, for example of a shirt | |
| WearableMeasurementCup | Measurement of the cup, for example of a bra | |
| WearableMeasurementHeight | Measurement of the height, for example the heel height of a shoe | |
| WearableMeasurementHips | Measurement of the hip section, for example of a skirt | |
| WearableMeasurementInseam | Measurement of the inseam, for example of pants | |
| WearableMeasurementLength | Represents the length, for example of a dress | |
| WearableMeasurementOutsideLeg | Measurement of the outside leg, for example of pants | |
| WearableMeasurementSleeve | Measurement of the sleeve length, for example of a shirt | |
| WearableMeasurementTypeEnumeration | Enumerates common types of measurement for wearables products. | |
| WearableMeasurementWaist | Measurement of the waist section, for example of pants | |
| WearableMeasurementWidth | Measurement of the width, for example of shoes | |
| WearableSizeGroupBig | Size group "Big" for wearables. | |
| WearableSizeGroupBoys | Size group "Boys" for wearables. | |
| WearableSizeGroupEnumeration | Enumerates common size groups (also known as "size types") for wearable products. | |
| WearableSizeGroupExtraShort | Size group "Extra Short" for wearables. | |
| WearableSizeGroupExtraTall | Size group "Extra Tall" for wearables. | |
| WearableSizeGroupGirls | Size group "Girls" for wearables. | |
| WearableSizeGroupHusky | Size group "Husky" (or "Stocky") for wearables. | |
| WearableSizeGroupInfants | Size group "Infants" for wearables. | |
| WearableSizeGroupJuniors | Size group "Juniors" for wearables. | |
| WearableSizeGroupMaternity | Size group "Maternity" for wearables. | |
| WearableSizeGroupMens | Size group "Mens" for wearables. | |
| WearableSizeGroupMisses | Size group "Misses" (also known as "Missy") for wearables. | |
| WearableSizeGroupPetite | Size group "Petite" for wearables. | |
| WearableSizeGroupPlus | Size group "Plus" for wearables. | |
| WearableSizeGroupRegular | Size group "Regular" for wearables. | |
| WearableSizeGroupShort | Size group "Short" for wearables. | |
| WearableSizeGroupTall | Size group "Tall" for wearables. | |
| WearableSizeGroupWomens | Size group "Womens" for wearables. | |
| WearableSizeSystemAU | Australian size system for wearables. | |
| WearableSizeSystemBR | Brazilian size system for wearables. | |
| WearableSizeSystemCN | Chinese size system for wearables. | |
| WearableSizeSystemContinental | Continental size system for wearables. | |
| WearableSizeSystemDE | German size system for wearables. | |
| WearableSizeSystemEN13402 | EN 13402 (joint European standard for size labelling of clothes). | |
| WearableSizeSystemEnumeration | Enumerates common size systems specific for wearable products | |
| WearableSizeSystemEurope | European size system for wearables. | |
| WearableSizeSystemFR | French size system for wearables. | |
| WearableSizeSystemGS1 | GS1 (formerly NRF) size system for wearables. | |
| WearableSizeSystemIT | Italian size system for wearables. | |
| WearableSizeSystemJP | Japanese size system for wearables. | |
| WearableSizeSystemMX | Mexican size system for wearables. | |
| WearableSizeSystemUK | United Kingdom size system for wearables. | |
| WearableSizeSystemUS | United States size system for wearables. | |
| WebAPI | An application programming interface accessible over Web/Internet technologies. | |
| WebApplication | Web applications. | |
| WebContent | WebContent is a type representing all WebPage, WebSite and WebPageElement content. It is sometimes the case that detailed distinctions between Web pages, sites and their parts is not always important or obvious. The WebContent type makes it easier to describe Web-addressable content without requiring such distinctions to always be stated. (The intent is that the existing types WebPage, WebSite and WebPageElement will eventually be declared as subtypes of WebContent). | |
| WebPage | A web page. Every web page is implicitly assumed to be declared to be of type WebPage, so the various properties about that webpage, such as breadcrumb may be used. We recommend explicit declaration if these properties are specified, but if they are found outside of an itemscope, they will be assumed to be about the page. |
|
| WebPageElement | A web page element, like a table or an image. | |
| WebSite | A WebSite is a set of related web pages and other items typically served from a single web domain and accessible via URLs. | |
| Wednesday | The day of the week between Tuesday and Thursday. | |
| WesternConventional | The conventional Western system of medicine, that aims to apply the best available evidence gained from the scientific method to clinical decision making. Also known as conventional or Western medicine. | |
| Wholesale | The drug's cost represents the wholesale acquisition cost of the drug. | |
| WholesaleStore | A wholesale store. | |
| WinAction | The act of achieving victory in a competitive activity. | |
| Winery | A winery. | |
| Withdrawn | Withdrawn. | |
| WorkBasedProgram | A program with both an educational and employment component. Typically based at a workplace and structured around work-based learning, with the aim of instilling competencies related to an occupation. WorkBasedProgram is used to distinguish programs such as apprenticeships from school, college or other classroom based educational programs. | |
| WorkersUnion | A Workers Union (also known as a Labor Union, Labour Union, or Trade Union) is an organization that promotes the interests of its worker members by collectively bargaining with management, organizing, and political lobbying. | |
| WriteAction | The act of authoring written creative content. | |
| WritePermission | Permission to write or edit the document. | |
| XPathType | Text representing an XPath (typically but not necessarily version 1.0). | |
| XRay | X-ray imaging. | |
| ZoneBoardingPolicy | The airline boards by zones of the plane. | |
| Zoo | A zoo. |
Recommended Semantic Terms
Overview
This document provides a complete list of terms from Schema.org vocabulary that can be used as semantic descriptors (id) in ALPS profiles.
Usage
- When starting API design, first select appropriate terms from 🔵 Core Terms.
- If more detailed expression is needed, consider 🟡 Extended Terms.
- For special use cases, consider ⚪ Full Terms.
- You can find terms by category using the category index.
- Regarding domain-specific terms:
- Define industry or business-specific terms as custom semantic descriptors
- Naming convention: domainName + PropertyName (e.g., orderShippingStatus, medicalDiagnosisCode)
- It is recommended to build on Schema.org terms while making necessary extensions
- When defining domain-specific terms, it’s important to clearly document their meaning and usage
Category Index
- Basic Properties
- Identifiers & References
- Metadata
- Dates & Periods
- Text & Content
- Media & Files
- Person & Individual
- Organization & Group
- Address & Location
- Products & Services
- Price & Payment
- Events & Activities
- Reviews & Ratings
- Education & Learning
- Medical & Health
- Finance & Transactions
- Reservations & Scheduling
- Communication
- Security & Access Control
- Workflow & Process
- Technical & System
- Legal & Terms
- Other Attributes
| status | 🔵 | Status | |
| type | 🔵 | Type | |
| category | 🔵 | Category | |
| order | 🔵 | Order | |
| priority | 🔵 | Priority | |
| tag | 🔵 | Tag | |
| group | 🔵 | Group | |
| relation | 🔵 | Relation | |
| source | 🔵 | Source | |
| target | 🔵 | Target | |
| origin | 🟡 | Origin | |
| destination | 🟡 | Destination | |
| sortOrder | 🟡 | Sort order | |
| rank | 🟡 | Rank | |
| score | 🟡 | Score | |
| level | 🟡 | Level | |
| theme | 🟡 | Theme | |
| style | 🟡 | Style | |
| layout | 🟡 | Layout | |
| template | 🟡 | Template | |
| format | 🟡 | Format | |
| mode | 🟡 | Mode | |
| state | 🟡 | State | |
| phase | 🟡 | Phase | |
| context | 🟡 | Context | |
| scope | 🟡 | Scope | |
| flags | ⚪ | Flags | |
| options | ⚪ | Options | |
| settings | ⚪ | Settings | |
| preferences | ⚪ | Preferences | |
| configuration | ⚪ | Configuration | |
| customization | ⚪ | Customization | |
| variant | ⚪ | Variant | |
| alternative | ⚪ | Alternative | |
| fallback | ⚪ | Fallback | |
| override | ⚪ | Override | |
| default | ⚪ | Default | |
| custom | ⚪ | Custom | |
| external | ⚪ | External | |
| internal | ⚪ | Internal | |
| public | ⚪ | Public | |
| private | ⚪ | Private | |
| hidden | ⚪ | Hidden | |
| visible | ⚪ | Visible | |
| enabled | ⚪ | Enabled | |
| disabled | ⚪ | Disabled | |
| locked | ⚪ | Locked | |
| archived | ⚪ | Archived | |
| deleted | ⚪ | Deleted | |
| deprecated | ⚪ | Deprecated |
Conclusion
This document is continuously updated and new terms and usage patterns may be added.
Importance Levels
All terms are classified into three levels based on importance and frequency of use:
🔵 Core Terms: Essential key terms for basic APIs (about 10-15% of total)
- Fundamental vocabulary used in most applications
- First choice when creating simple APIs
- Terms necessary for common CRUD operations
🟡 Extended Terms: Commonly used extended terms (about 30-35% of total)
- Vocabulary needed for specific domains and more detailed expressions
- Terms commonly used in general business applications
- Options when richer expressiveness is needed
⚪ Full Terms: Special purpose terms (about 50-55% of total)
- Vocabulary needed for specific industries and special use cases
- Options when complete compatibility is needed
- Terms for very specialized expressions
Usage Notes
- Naming Conventions:
- Use lowerCamelCase format
- Avoid abbreviations, use complete words
- Maintain consistent naming patterns
- Customization:
- Can add custom terms as needed
- Recommend using appropriate prefixes for industry-specific terms
- Strive for unified term usage within organization
- Interoperability:
- Consider compatibility with Schema.org
- Prioritize standard terms
- Clearly document when making custom extensions
Reference Resources
Shared Vocabulary
When designing applications, it is recommended to use standardized terms registered in shared vocabulary sites.
IANA Link Relations
Link relations are standardized identifiers that indicate the relationship between two resources. The main purpose is to clarify the semantic relationship between resources.
Example) author registered in IANA
<descriptor id="goBookAuthor" type="safe" rt="#BookAuthor" rel="author">
Please refer to IANA Link Relations.
Schema.org
Schema.org is a vocabulary for structured data jointly developed by Google, Microsoft, Yahoo, and Yandex.
Please refer to Semantic Terms.
ALPS files that import semantics from Schema.org are available.
Link to semantics using href.
Example) givenName and familyName
<descriptor id="Person">
<descriptor href="https://alps-io.github.io/imports/schema.org/properties/givenName.json" />
<descriptor href="https://alps-io.github.io/imports/schema.org/properties/familyName.json" />
</descriptor>
Narrowing Down
You can create descriptors that narrow down semantics from shared vocabulary.
Example)
<descriptor id="bankAccountId" href="https://alps-io.github.io/imports/schema.org/properties/accountId.json" />

When building a house, we don't rely solely on pictures or perspective drawings.
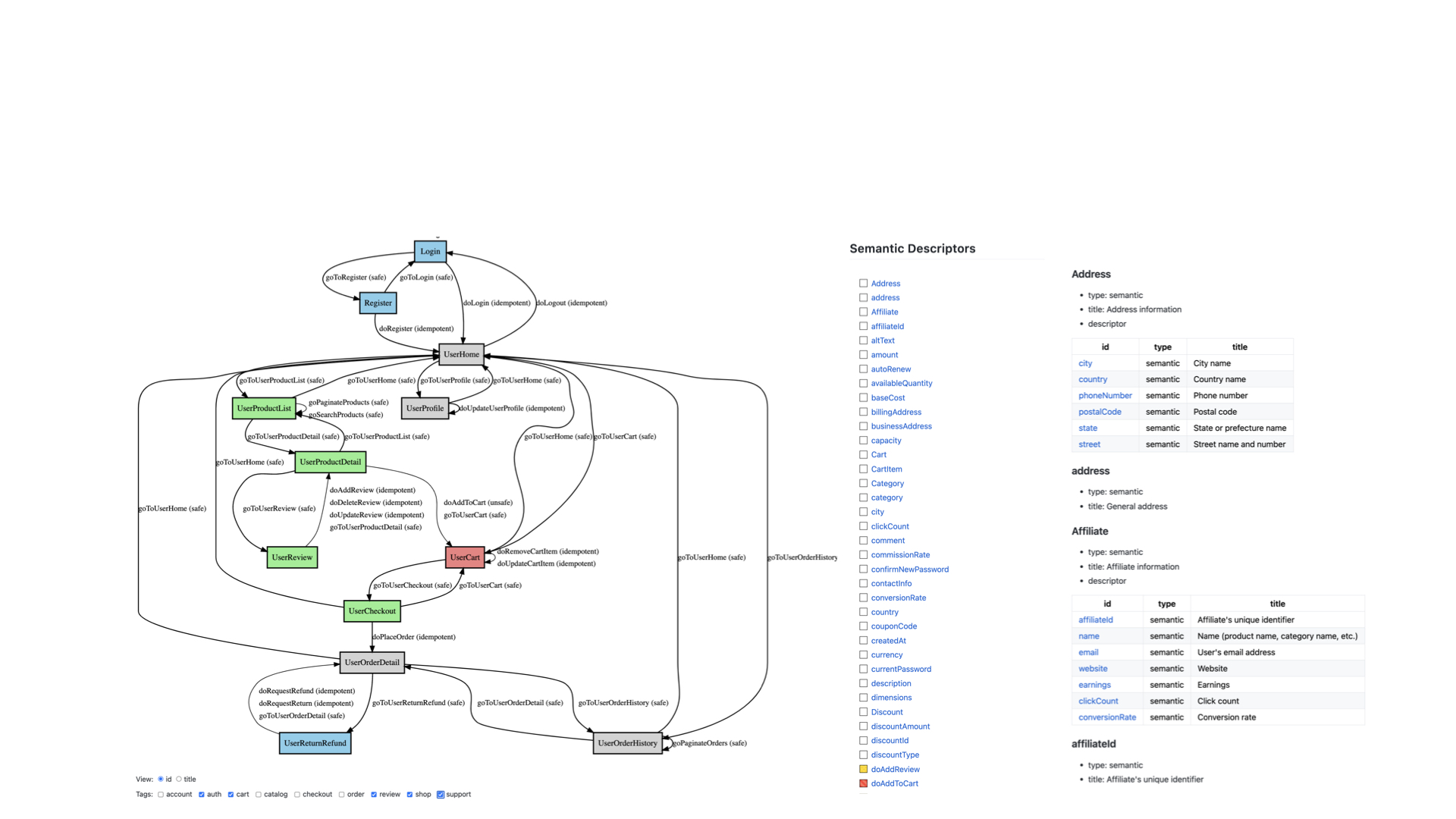
Similarly, ALPS document is that common language when it comes to building a website.
ALPS Basic Tutorial
The ALPS tutorial consists of two parts:
- Basic Tutorial (this page)
- Learn the basic usage of ALPS through hands-on practice
- Start with tool usage and gradually understand ALPS features
- Ideal as the first step to getting started with ALPS
- Advanced Tutorial
- Learn about the theoretical foundation and design patterns of ALPS
- Understand the essence of REST/HTTP applications as state transition systems
- For those who want a deeper understanding or are involved in large-scale application design
We recommend starting with this basic tutorial.
Getting Started
In this tutorial, we’ll use the browser-based ALPS editor:
- Open ALPS Editor
- Delete all demo code displayed in the left editor pane
Note: While you can use the ASD application in a local environment, we recommend using the online editor for this tutorial.
First Step: Preparing an Empty File
The first step in creating an ALPS document is to prepare a basic empty file. This file serves as the starting point with the minimum structure required for all ALPS documents.
ALPS documents can be written in either XML or JSON format. Each format references its respective schema (xsd for XML, json-schema for JSON) which defines the valid structure and ensures your document follows the ALPS specification. There is no functional difference between the two formats, so you can choose based on your team’s preferences and existing toolchain.
For XML:
<?xml version="1.0" encoding="UTF-8"?>
<alps
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="https://alps-io.github.io/schemas/alps.xsd">
</alps>
For JSON:
{
"$schema": "https://alps-io.github.io/schemas/alps.json",
"alps": {
"descriptor": [
]
}
}
Register Meanings as IDs
In ALPS, specific terms handled by the application are defined as IDs. Let’s start by adding the term dateCreated.
In XML:
<?xml version="1.0" encoding="UTF-8"?>
<alps
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="https://alps-io.github.io/schemas/alps.xsd">
+ <descriptor id="dateCreated"/>
</alps>
In JSON:
{
"$schema": "https://alps-io.github.io/schemas/alps.json",
"alps": {
"descriptor": [
+ {"id": "dateCreated"}
]
}
}
Describe Terms
You can add descriptions using title and doc.
In XML:
<?xml version="1.0" encoding="UTF-8"?>
<alps
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="https://alps-io.github.io/schemas/alps.xsd">
- <descriptor id="dateCreated"/>
+ <descriptor id="dateCreated" title="作成日付">
+ <doc format="text">ISO8601フォーマットで記事の作成日付を表します</doc>
+ </descriptor>
</alps>
In JSON:
{
"$schema": "https://alps-io.github.io/schemas/alps.json",
"alps": {
"descriptor": [
- {"id": "dateCreated"}
+ {"id": "dateCreated", "title": "Creation Date", "doc": {"format": "text", "value": "Represents the article creation date in ISO8601 format"}}
]
}
}
The title is a concise expression like a heading, while doc provides a longer text explanation.
This ID bound to a meaning is called a semantic descriptor. dateCreated is a semantic descriptor tied to the meaning “creation date”. Such definition of meanings and concepts is called an ontology.
Vocabulary
One of ALPS’s important roles is to serve as a dictionary of application terms. It helps users use the same terms when referring to the same meaning, preventing expression variations and misunderstandings among users.
Information Contains Information
Semantic descriptors can contain other semantic descriptors.
For example, BlogPosting contains articleBody and dateCreated. By describing descriptors within descriptors, we represent information hierarchy. Such information structure and arrangement is called taxonomy.
In XML:
<alps
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="https://alps-io.github.io/schemas/alps.xsd">
<!-- Ontology -->
<descriptor id="id" title="id"/>
<descriptor id="articleBody" title="Content"/>
<descriptor id="dateCreated" title="Creation Date"/>
<!-- Taxonomy -->
<descriptor id="BlogPosting" title="Article" >
<descriptor href="#id"/>
<descriptor href="#dateCreated"/>
<descriptor href="#articleBody"/>
</descriptor>
<descriptor id="Blog" title="Article List">
<descriptor href="#BlogPosting"/>
</descriptor>
</alps>
In JSON:
{
"$schema": "https://alps-io.github.io/schemas/alps.json",
"alps": {
"descriptor": [
{"id": "id", "title": "id"},
{"id": "articleBody", "title": "Content"},
{"id": "dateCreated", "title": "Creation Date"},
{"id": "BlogPosting", "title": "Article", "descriptor": [
{"href": "#id"},
{"href": "#dateCreated"},
{"href": "#articleBody"}
]},
{"id": "Blog", "title": "Article List", "descriptor": [
{"href": "#BlogPosting"}
]}
]
}
}
You can use # to reference other descriptors. This is called an inline link and allows referencing one descriptor from multiple locations.
Viewing and Manipulating Information
Web pages contain not just information but also links to other pages and action forms, allowing viewing and manipulation of related information. There are three types of operations:
safe
Viewing related information. In HTML, this corresponds to anchor elements (), and in HTTP, to GET. This is a safe transition that doesn’t change the resource state. What changes is the application state, i.e., which URL the user is viewing.
idempotent
Changes the resource state. Has idempotency, meaning repeated execution yields the same result. Think of overwriting a file - the result doesn’t change no matter how many times you execute it.
unsafe
Like idempotent, it changes the resource state but lacks idempotency. Think of appending to a file - the result differs with each execution.
HTTP Method Correspondence
safe corresponds to GET, idempotent to PUT or DELETE, and unsafe to POST HTTP methods.
Links
Create links by specifying the operation type with type and the destination with rt.
This example is a link to view Blog:
In XML:
<descriptor type="safe" id="goBlog" rt="#Blog" title="View Blog Post List" />
In JSON:
{"type": "safe", "id": "goBlog", "rt": "#Blog", "title": "View Blog Post List"}
This example adds an operation to return to the blog post list from a blog post:
In XML:
<descriptor id="BlogPosting" title="Article">
<descriptor href="#id"/>
<descriptor href="#dateCreated"/>
<descriptor href="#articleBody"/>
<descriptor href="#goBlog" />
</descriptor>
In JSON:
{"id": "BlogPosting", "title": "Article", "descriptor": [
{"href": "#id"},
{"href": "#dateCreated"},
{"href": "#articleBody"},
{"href": "#goBlog"}
]}
Include descriptors needed for transitions and operations in the descriptor:
In XML:
<descriptor id="goBlogPosting" type="safe" rt="#BlogPosting" title="View Article">
<!-- ID is needed to view an article -->
<descriptor href="#id"/>
</descriptor>
In JSON:
{"id": "goBlogPosting", "type": "safe", "rt": "#BlogPosting", "title": "View Article", "descriptor": [
{"href": "#id"}
]}
Let’s add links for both blog post list and blog post:
In XML:
<alps
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="https://alps-io.github.io/schemas/alps.xsd">
<!-- Ontology -->
<descriptor id="id" title="id"/>
<descriptor id="articleBody" title="Content"/>
<descriptor id="dateCreated" title="Creation Date"/>
<!-- Taxonomy -->
<descriptor id="BlogPosting" title="Article" >
<descriptor href="#id"/>
<descriptor href="#dateCreated"/>
<descriptor href="#articleBody"/>
<descriptor href="#goBlog" />
</descriptor>
<descriptor id="Blog" title="Article List">
<descriptor href="#BlogPosting"/>
<descriptor href="#goBlogPosting" />
</descriptor>
<!-- Choreography -->
<descriptor type="safe" id="goBlog" rt="#Blog" title="View Article List" />
<descriptor type="safe" id="goBlogPosting" rt="#BlogPosting" title="View Article">
<descriptor href="#id"/>
</descriptor>
</alps>
In JSON:
{
"$schema": "https://alps-io.github.io/schemas/alps.json",
"alps": {
"descriptor": [
{"id": "id", "title": "id"},
{"id": "articleBody", "title": "Content"},
{"id": "dateCreated", "title": "Creation Date"},
{"id": "BlogPosting", "title": "Article", "descriptor": [
{"href": "#id"},
{"href": "#dateCreated"},
{"href": "#articleBody"},
{"href": "#goBlog"}
]},
{"id": "Blog", "title": "Article List", "descriptor": [
{"href": "#BlogPosting"},
{"href": "#goBlogPosting"}
]},
{"type": "safe", "id": "goBlog", "rt": "#Blog", "title": "View Article List"},
{"type": "safe", "id": "goBlogPosting", "rt": "#BlogPosting", "title": "View Article", "descriptor": [
{"href": "#id"}
]}
]
}
}
ALPS Tutorial for REST Applications
Introduction
Modern web applications (online shopping, social networks, video streaming services, business systems, etc.) are mostly built based on the REST architecture. In this tutorial, we will explain how to design applications using ALPS, considering the basic concepts of REST.
Essence of REST Applications
A REST application is essentially a “state transition system.” For example:
- Search for a product, add it to the cart, and confirm the order (online shopping)
- Read posts, react, and leave comments (social network)
All of these actions can be viewed as “transitions” from one “state” to another, and a REST application manages these transitions.
What is State Transition?
State transition refers to a change from one state to another within a system. In web applications:
- Users are always “somewhere” (current state).
- They can move “somewhere else” (possible state transition).
- “How” to move is defined (transition method).
These three elements are the basics of a state transition system.
Two States in REST
In addition to the states used in state transitions, REST has two important types of states:
- Application State
- Represents the client (browser) location, expressed as URLs
- Resource State
- Represents the state of data managed on the server
The client accesses resource states by changing its application state, and the server responds with both resource states and network affordances that describe possible state transitions.
Basic Flow of State Transitions in REST Applications
State transitions in REST applications proceed as follows:
- Recognize the Current State
- The client understands the current state and the available information.
- Choose a Transition
- The client checks the provided links and actions, then chooses the next transition.
- Execute the Transition
- The client performs the chosen action, moving to a new state.
This flow repeats continuously throughout the use of the application.
Information Architecture and ALPS
To properly design a REST application, the state transition system needs to be systematically documented. Dan Klyn has proposed three important aspects needed for this documentation:
- Ontology
- Defines “what something means.”
- Example: The meaning of terms such as “blog post” or “creation date.”
- Shares the same meaning of terms.
- Taxonomy
- Organizes “how things relate.”
- Example: A “blog post” has a “creation date” and “body.”
- Defines the structure of information.
- Choreography
- Describes “how things work.”
- Example: Viewing, creating, updating, and deleting posts.
- Shows the flow of actions.
ALPS is a means to practically express these concepts. In the following sections of this tutorial:
- Ontology: Define the basic terms.
- Taxonomy (1): Define the information structure.
- Choreography: Define state transitions.
- Taxonomy (2): Integrate states and transitions.
We will learn the specific implementation methods.
Ontology: Defining Terms
Ontology defines the meaning of terms used in the application. Clearly defining these terms at this stage helps create a shared understanding among the team and ensures consistent API design.
Setting Up the Editor
- Open https://editor.app-state-diagram.com/ in your browser.
- Delete all the demo code displayed in the left editor pane.
Defining the First Term
Below is an example definition for the term “creation date.”
In XML:
<?xml version="1.0" encoding="UTF-8"?>
<alps
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="https://alps-io.github.io/schemas/alps.xsd">
<descriptor id="dateCreated" title="Creation Date">
<doc format="text">Represents the date the post was created, in ISO8601 format</doc>
</descriptor>
</alps>
In JSON:
{
"$schema": "https://alps-io.github.io/schemas/alps.json",
"alps": {
"version": "1.0",
"descriptor": [
{"id": "dateCreated", "title": "Creation Date", "doc": {"format": "text", "value": "Represents the date the post was created, in ISO8601 format"}}
]
}
}
Explanation of each element in this definition:
idAttribute- The identifier for the term.
titleAttribute- A short, human-readable description used for display in UI or documentation.
docElement- Describes the precise meaning and usage of the term.
- Specifies the format attribute (e.g., text).
Defining the Article Body
Next, we add a term that represents the body of a blog post.
In XML:
<?xml version="1.0" encoding="UTF-8"?>
<alps
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="https://alps-io.github.io/schemas/alps.xsd">
<descriptor id="dateCreated" title="Creation Date">
<doc format="text">Represents the date the post was created, in ISO8601 format</doc>
</descriptor>
<descriptor id="articleBody" title="Article Body">
<doc format="text">The body of the blog post</doc>
</descriptor>
</alps>
In JSON:
{
"$schema": "https://alps-io.github.io/schemas/alps.json",
"alps": {
"version": "1.0",
"descriptor": [
{"id": "dateCreated", "title": "Creation Date", "doc": {"format": "text", "value": "Represents the date the post was created, in ISO8601 format"}},
{"id": "articleBody", "title": "Article Body", "doc": {"format": "text", "value": "The body of the blog post"}}
]
}
}
Key Points of Ontology Definition
- Naming Conventions
- Prioritize semantic terms.
- Use consistent naming patterns.
- CamelCase is recommended (e.g., dateCreated, articleBody).
- Writing Descriptions
- Aim for concise and clear descriptions.
- Include examples if necessary.
- Specify formats or constraints if applicable.
Taxonomy: Structuring Information
Taxonomy defines “how to organize and classify information.” By combining the terms we defined earlier, we can represent larger concepts.
A blog post (BlogPosting) can be defined as a collection of information with a creation date and body.
In XML:
<?xml version="1.0" encoding="UTF-8"?>
<alps
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="https://alps-io.github.io/schemas/alps.xsd">
<descriptor id="dateCreated" title="Creation Date">
<doc format="text">Represents the date the post was created, in ISO8601 format</doc>
</descriptor>
<descriptor id="articleBody" title="Article Body">
<doc format="text">The body of the blog post</doc>
</descriptor>
<descriptor id="BlogPosting" title="Blog Post">
<descriptor href="#dateCreated"/>
<descriptor href="#articleBody"/>
</descriptor>
</alps>
In JSON:
{
"$schema": "https://alps-io.github.io/schemas/alps.json",
"alps": {
"version": "1.0",
"descriptor": [
{"id": "dateCreated", "title": "Creation Date", "doc": {"format": "text", "value": "Represents the date the post was created, in ISO8601 format"}},
{"id": "articleBody", "title": "Article Body", "doc": {"format": "text", "value": "The body of the blog post"}},
{"id": "BlogPosting", "title": "Blog Post", "descriptor": [
{"href": "#dateCreated"},
{"href": "#articleBody"}
]}
]
}
}
Key Points of Structuring
- Reference by
href- Use
#to refer to existing terms. - Allows reuse of the same definitions multiple times.
- Ensures consistency of terms.
- Use
- Representation of Hierarchical Structure
BlogPostingincludesdateCreatedandarticleBody.- The included elements are represented using the
descriptortag. - Represented as a parent-child relationship.
Preview in Editor
- Vocabulary List
- Defined terms are displayed hierarchically.
- Elements contained within
BlogPostingare displayed.
- State Diagram
BlogPostingis displayed as a single state.- No transitions are defined at this stage.
Why Structuring is Important
- Clarification of Relationships
- Which information belongs to which concept.
- Visualization of dependencies between pieces of information.
- Consistent API
- The same structure is always represented in the same way.
- Makes implementation on the client side easier.
- Role as Documentation
- Understanding the system as a whole.
- Establishing a common understanding of the information structure.
Choreography: Defining State Transitions
Choreography defines state transitions according to the types of operations. In ALPS, operations are categorized as follows:
| Operation | Type | HTTP Method Description |
|---|---|---|
| safe | GET | Changes only application state |
| unsafe | POST | Creates new resource state |
| idempotent | PUT/DELETE | Updates/deletes resource state |
safe- Changes only the application state (e.g., GET).
- Resource state is not altered.
unsafe- Creates a new resource state.
- May have different outcomes each time it is executed.
idempotent- Updates or deletes the resource state.
- Produces the same outcome no matter how many times it is executed.
ALPS operations distinguish between resource changes that have a different result each time they are performed, i.e., non-idempotent operations, such as add operations, and those that have a different result each time they are performed, i.e., idempotent operations, such as change or delete operations, which do not change the result no matter how many times they are repeated.
Defining the Transition to View an Article
First, let’s define a safe operation to view a blog post:
In XML:
<?xml version="1.0" encoding="UTF-8"?>
<alps
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="https://alps-io.github.io/schemas/alps.xsd">
<descriptor id="dateCreated" title="Creation Date">
<doc format="text">Represents the date the post was created, in ISO8601 format</doc>
</descriptor>
<descriptor id="articleBody" title="Article Body">
<doc format="text">The body of the blog post</doc>
</descriptor>
<descriptor id="BlogPosting" title="Blog Post">
<descriptor href="#dateCreated"/>
<descriptor href="#articleBody"/>
</descriptor>
<descriptor id="goBlogPosting" type="safe" rt="#BlogPosting" title="View Blog Post">
<descriptor href="#dateCreated"/>
</descriptor>
</alps>
In JSON:
{
"$schema": "https://alps-io.github.io/schemas/alps.json",
"alps": {
"version": "1.0",
"descriptor": [
{"id": "dateCreated", "title": "Creation Date", "doc": {"format": "text", "value": "Represents the date the post was created, in ISO8601 format"}},
{"id": "articleBody", "title": "Article Body", "doc": {"format": "text", "value": "The body of the blog post"}},
{"id": "BlogPosting", "title": "Blog Post", "descriptor": [
{"href": "#dateCreated"},
{"href": "#articleBody"}
]},
{"id": "goBlogPosting", "type": "safe", "rt": "#BlogPosting", "title": "View Blog Post", "descriptor": [
{"href": "#dateCreated"}
]}
]
}
}
Important elements of this definition:
- Prefix Naming Convention
- Use
goforsafetransitions. - Use
doforunsafeandidempotenttransitions.
- Use
typeAttribute- Specifies the type of operation.
- In this case, it is
safe(a safe transition).
rt(return type) Attribute- Specifies the destination state.
- Indicates a transition to
#BlogPosting.
- Information Needed for the Transition
- Specified by
descriptor href="#dateCreated". - Represents the information needed to identify the post.
- Specified by
In the preview screen:
- The state diagram shows the state (
BlogPosting) and an arrow representing the transition. - The vocabulary list displays information about the transition (
goBlogPosting).
Defining the Transition to Create an Article
Next, let’s define an unsafe operation to create a new blog post:
In XML:
<descriptor id="doCreateBlogPosting" type="unsafe" rt="#BlogPosting" title="Create Blog Post">
<descriptor href="#articleBody"/>
</descriptor>
In JSON:
{"id": "doCreateBlogPosting", "type": "unsafe", "rt": "#BlogPosting", "title": "Create Blog Post", "descriptor": [
{"href": "#articleBody"}
]}
Important elements of this definition:
- Prefix Naming Convention
- Use
doforunsafetransitions.
- Use
typeAttribute- Specifies the type of operation.
- In this case, it is
unsafe(a state-changing operation).
rt(return type) Attribute- Specifies the destination state.
- Indicates a transition to
#BlogPosting.
- Information Needed for the Transition
- Specified by
descriptor href="#articleBody". - Represents the information needed to create the post.
- Specified by
In the preview screen:
- The state diagram shows the state (
BlogPosting) and an arrow representing the transition (doCreateBlogPosting). - The vocabulary list displays information about the transition (
doCreateBlogPosting).
Defining the Transition to Update an Article
Now, let’s define an idempotent operation to update a blog post:
In XML:
<descriptor id="doUpdateBlogPosting" type="idempotent" rt="#BlogPosting" title="Update Blog Post">
<descriptor href="#articleBody"/>
</descriptor>
In JSON:
{"id": "doUpdateBlogPosting", "type": "idempotent", "rt": "#BlogPosting", "title": "Update Blog Post", "descriptor": [
{"href": "#articleBody"}
]}
Important elements of this definition:
- Prefix Naming Convention
- Use
doforidempotenttransitions.
- Use
typeAttribute- Specifies the type of operation.
- In this case, it is
idempotent(an operation that can be repeated without changing the result).
rt(return type) Attribute- Specifies the destination state.
- Indicates a transition to
#BlogPosting.
- Information Needed for the Transition
- Specified by
descriptor href="#articleBody". - Represents the information needed to update the post.
- Specified by
In the preview screen:
- The state diagram shows the state (
BlogPosting) and an arrow representing the transition (doUpdateBlogPosting). - The vocabulary list displays information about the transition (
doUpdateBlogPosting).
Taxonomy (2): Integrating States and Transitions
So far, we have defined the terms (ontology), the information structure (taxonomy), and the state transitions (choreography). Now, let’s integrate these elements to represent the complete blog system.
In XML:
<descriptor id="Blog" title="Blog">
<descriptor href="#BlogPosting"/>
<descriptor href="#goBlogPosting"/>
<descriptor href="#doCreateBlogPosting"/>
<descriptor href="#doUpdateBlogPosting"/>
</descriptor>
In JSON:
{"id": "Blog", "title": "Blog", "descriptor": [
{"href": "#BlogPosting"},
{"href": "#goBlogPosting"},
{"href": "#doCreateBlogPosting"},
{"href": "#doUpdateBlogPosting"}
]}
This final structure represents the complete blog system, integrating all defined states and transitions.
Summary of Blog Structure
- Information Structure
- BlogPosting: Represents the structure of a blog post (with
dateCreatedandarticleBody).
- BlogPosting: Represents the structure of a blog post (with
- State Transitions
- goBlogPosting: A
safeoperation to view a blog post. - doCreateBlogPosting: An
unsafeoperation to create a new blog post. - doUpdateBlogPosting: An
idempotentoperation to update an existing blog post.
- goBlogPosting: A
- Complete Blog System
- Blog: Integrates all states (
BlogPosting) and transitions (goBlogPosting,doCreateBlogPosting,doUpdateBlogPosting).
- Blog: Integrates all states (
In the preview screen:
- The state diagram shows the complete structure of the blog system.
- The vocabulary list displays all defined elements and their relationships.
Conclusion: ALPS as a Design Methodology
In this tutorial, we learned how to use ALPS to design a blog system:
- Ontology: Defining terms and their meanings.
- Taxonomy: Structuring information.
- Choreography: Defining state transitions.
- Integration: Combining states and transitions to represent the complete system.
Using ALPS allows for clear and consistent API design, shared understanding among team members, and effective documentation.
The ALPS approach may initially seem like extra work, but as the project grows, its value becomes evident. Consistent design, clear documentation, and effective communication are key contributors to the long-term success of a project.